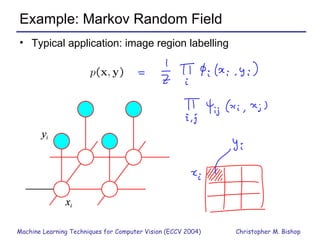
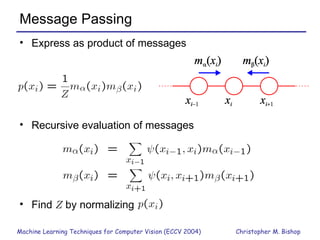
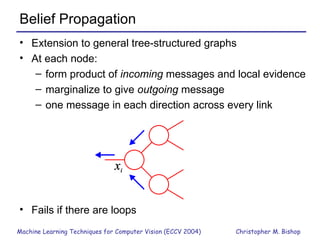
Part 1 of the document provides an overview of graphical models and machine learning techniques for computer vision. It discusses directed and undirected graphs, inference using message passing algorithms like belief propagation, and learning techniques like maximum likelihood and Bayesian learning. Graphical models allow modeling complex distributions and exploiting conditional independencies between variables. Inference on graphs is generally intractable for large cliques, but approximations like loopy belief propagation are commonly used.