Download as PDF, PPTX




![Greedy Layer-wise Deep Training
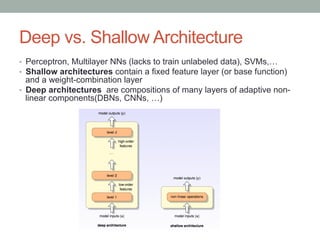
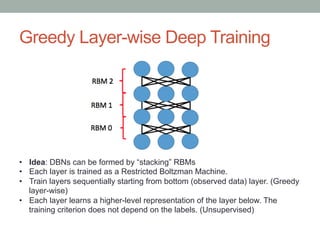
• The principle of greedy layer-wise unsupervised training can be
applied to DBNs with RBMs as the building blocks for each layer
[Hinton06], [Bengio07]
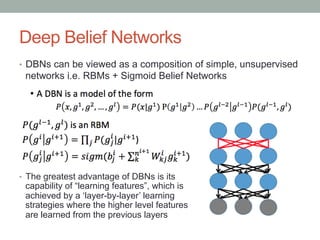
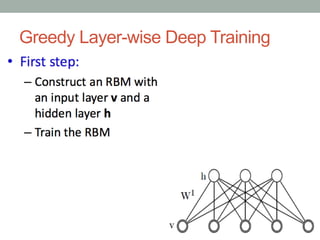
• 1. Train the first layer as an RBM that models the raw input x =
• h0 as its visible layer.
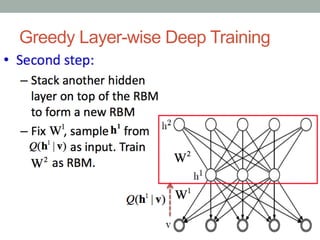
• 2. Use that first layer to obtain a representation of the input that will be used as data for the
second layer. Two common solutions exist. This representation can be chosen as being the
mean activations p(h1 = 1| h0}) or samples of p(h1 | h0}).
• 3. Train the second layer as an RBM, taking the transformed data (samples or mean
activations) as training examples (for the visible layer of that RBM).
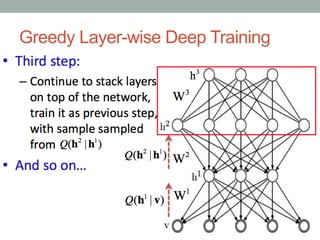
• 4. Iterate (2 and 3) for the desired number of layers, each time propagating upward either
samples or mean values.
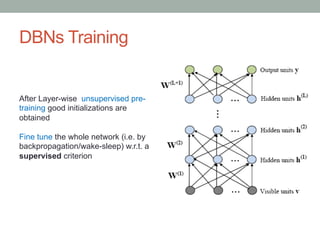
• 5. Fine-tune all the parameters of this deep architecture with respect to a proxy for the DBN
log- likelihood, or with respect to a supervised training criterion (after adding extra learning
machinery to convert the learned representation into supervised predictions, e.g. a linear
classifier).](https://image.slidesharecdn.com/dbns-hhtopcu-160211154651/85/Deep-Belief-Networks-8-320.jpg)





The document discusses deep belief networks (DBNs), emphasizing their capability for unsupervised feature learning through a hierarchical structure constructed from restricted Boltzmann machines (RBMs). It outlines the greedy layer-wise training methodology, where each network layer is trained sequentially to capture increasingly abstract features from the data without needing labeled inputs. The conclusion highlights DBNs' superiority in learning features compared to traditional machine learning methods and mentions an application of DBNs for classifying handwritten digits in the MNIST dataset.



































































