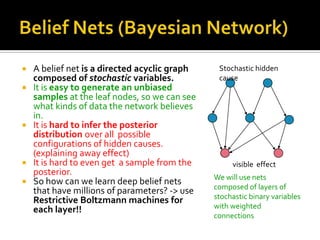
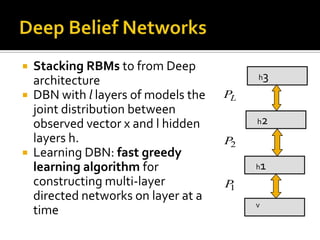
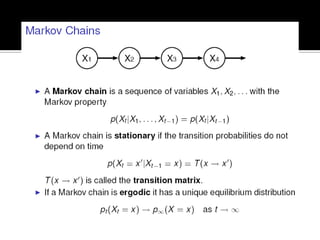
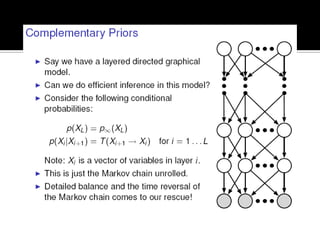
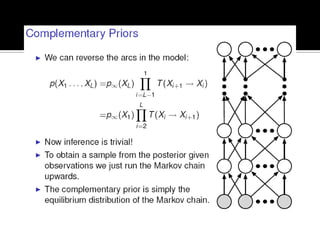
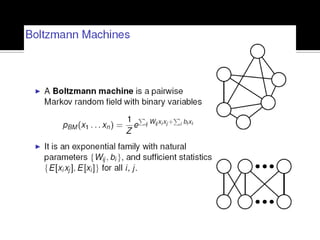
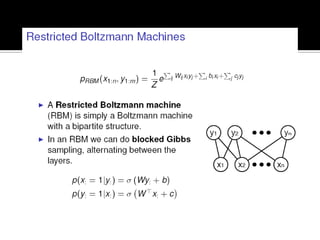
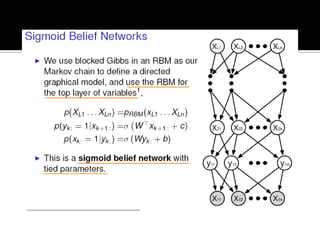
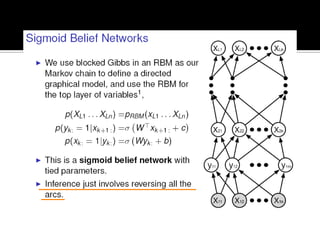
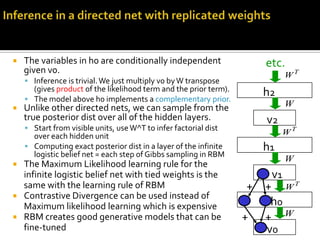
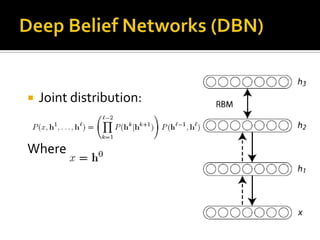
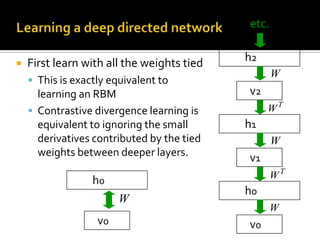
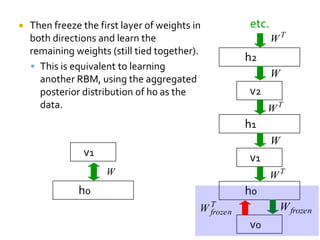
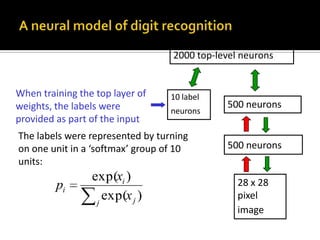
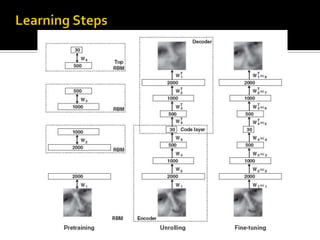
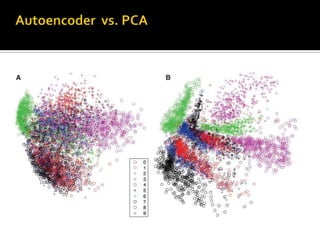
Deep Belief Nets (DBNs) are stacks of Restricted Boltzmann Machines (RBMs) that form a deep neural network architecture. RBMs are energy-based models that can be trained layer-by-layer to learn hierarchical representations of data. This presentation discusses how RBMs are used to learn the weights of DBNs in a greedy, unsupervised manner by treating the hidden units of one RBM as the visible data for the next RBM. Fine-tuning of the entire DBN can then be done with backpropagation. The paper demonstrates state-of-the-art performance of DBNs on MNIST handwritten digit recognition.