This document provides an introduction to statistical modeling and machine learning concepts. It discusses:
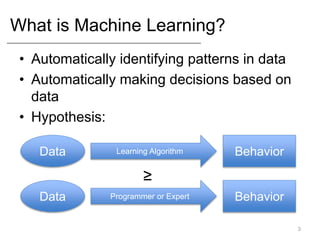
- What statistical modeling and machine learning are, including training models on data and evaluating them.
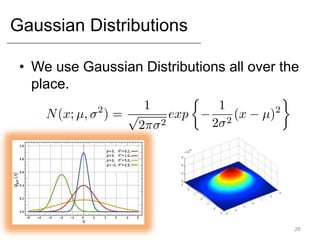
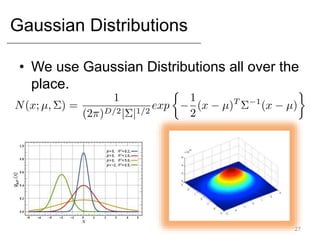
- Common statistical models like Gaussian, Bernoulli, and Multinomial distributions.
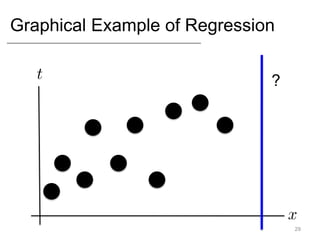
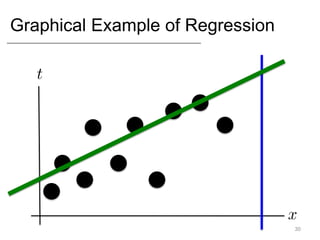
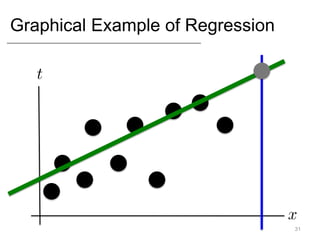
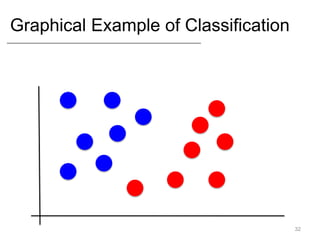
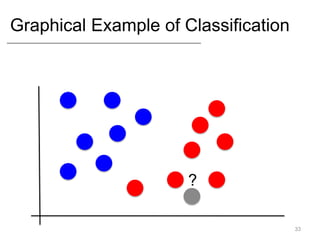
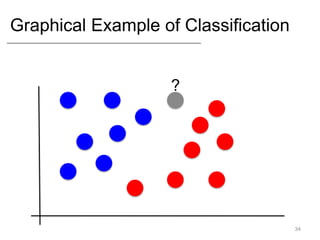
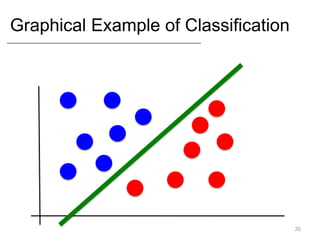
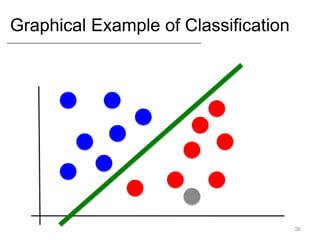
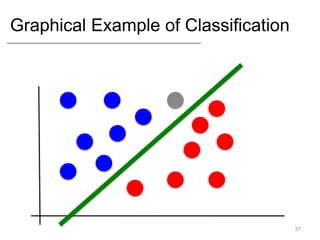
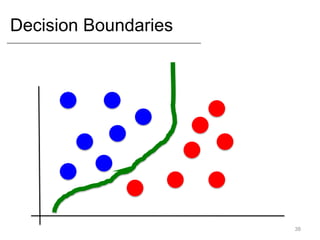
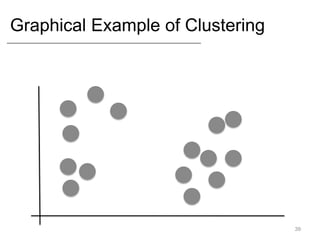
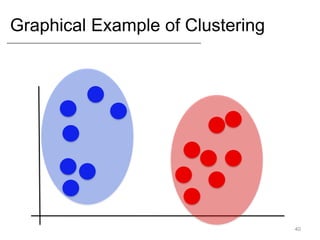
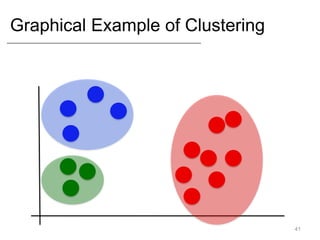
- Supervised learning tasks like regression and classification, and unsupervised clustering.
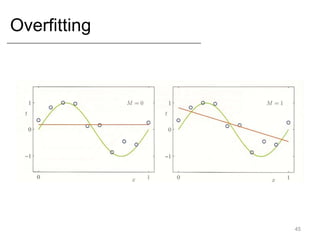
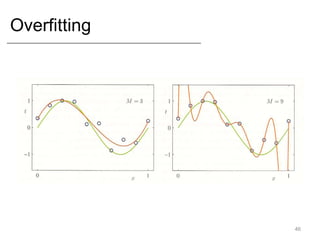
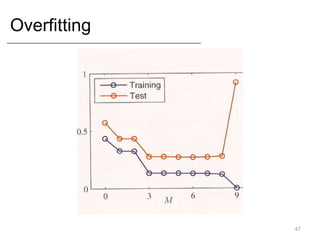
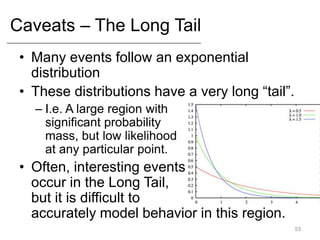
- Key concepts like overfitting, evaluation metrics, and issues with modeling like black swans and the long tail.




![Basics of Probabilities.
• Probabilities fall in the range [0,1]
• Mutually Exclusive events are events
that cannot simultaneously occur.
– The sum of the likelihoods of all mutually
exclusive events must be 1.
4](https://image.slidesharecdn.com/4646150-230426060459-f4cb0beb/85/4646150-ppt-5-320.jpg)