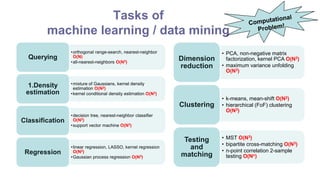
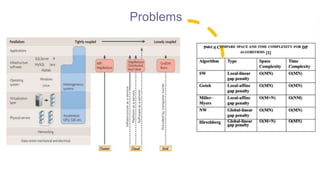
This document discusses 7 computational problems that arise in massive data analysis:
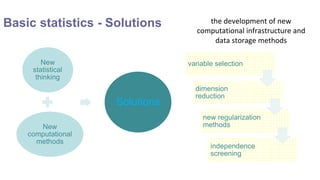
1. Basic statistics - calculating descriptive statistics like mean, variance on large datasets. Challenges include high dimensionality and noise. Solutions include new statistical methods and computational infrastructure.
2. Generalized N-body problem - predicting interactions between large numbers of objects. Challenges are its computational intensity as it scales as O(N^2). Solutions include tree-based algorithms that reduce complexity to O(N log N).
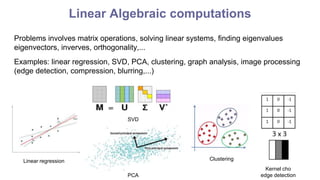
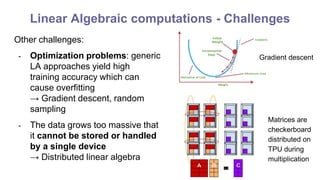
3. Linear algebraic computations - operations on large matrices. Challenges are matrices with slowly decaying spectra and noise. Solutions include truncated SVD, regularization, and distributed computation.








![N-body problem
• Three bodies
with equal
mass
[published
2000]
• Three bodies
of unequal
mass
• Two pairs of
bodies orbiting
about each
other
• An orbit discovered
in 2008 by
Tiancheng
Ouyang, Duokui
Yan, and Skyler
Simmons at BYU](https://image.slidesharecdn.com/computationalgiantsnhom-230724050446-c7040b07/85/Computational-Giants_nhom-pptx-11-320.jpg)

![Generalized N-body problem - Solutions
• Barnes-Hut Algorithm [Barnes and Hut, 87]:
if
r
s
s
r
i
R
R
i x
K
N
x
x
K )
,
(
)
,
(
O(N log N)
N(N-1)/2 = O(N2)](https://image.slidesharecdn.com/computationalgiantsnhom-230724050446-c7040b07/85/Computational-Giants_nhom-pptx-13-320.jpg)
![Generalized N-body problem - Solutions
• Fast Multipole Method [Greengard and Rokhlin 1987]:
i
i
x
x
K
x )
,
(
, O(N)
multipole/Taylor expansion
of order p
Quadtree
[Callahan-Kosaraju 95]: O(N) is impossible for log-depth tree
N(N-1)/2 = O(N2)](https://image.slidesharecdn.com/computationalgiantsnhom-230724050446-c7040b07/85/Computational-Giants_nhom-pptx-14-320.jpg)






























































![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

