Downloaded 16 times








![Markov Random Field Smoothing
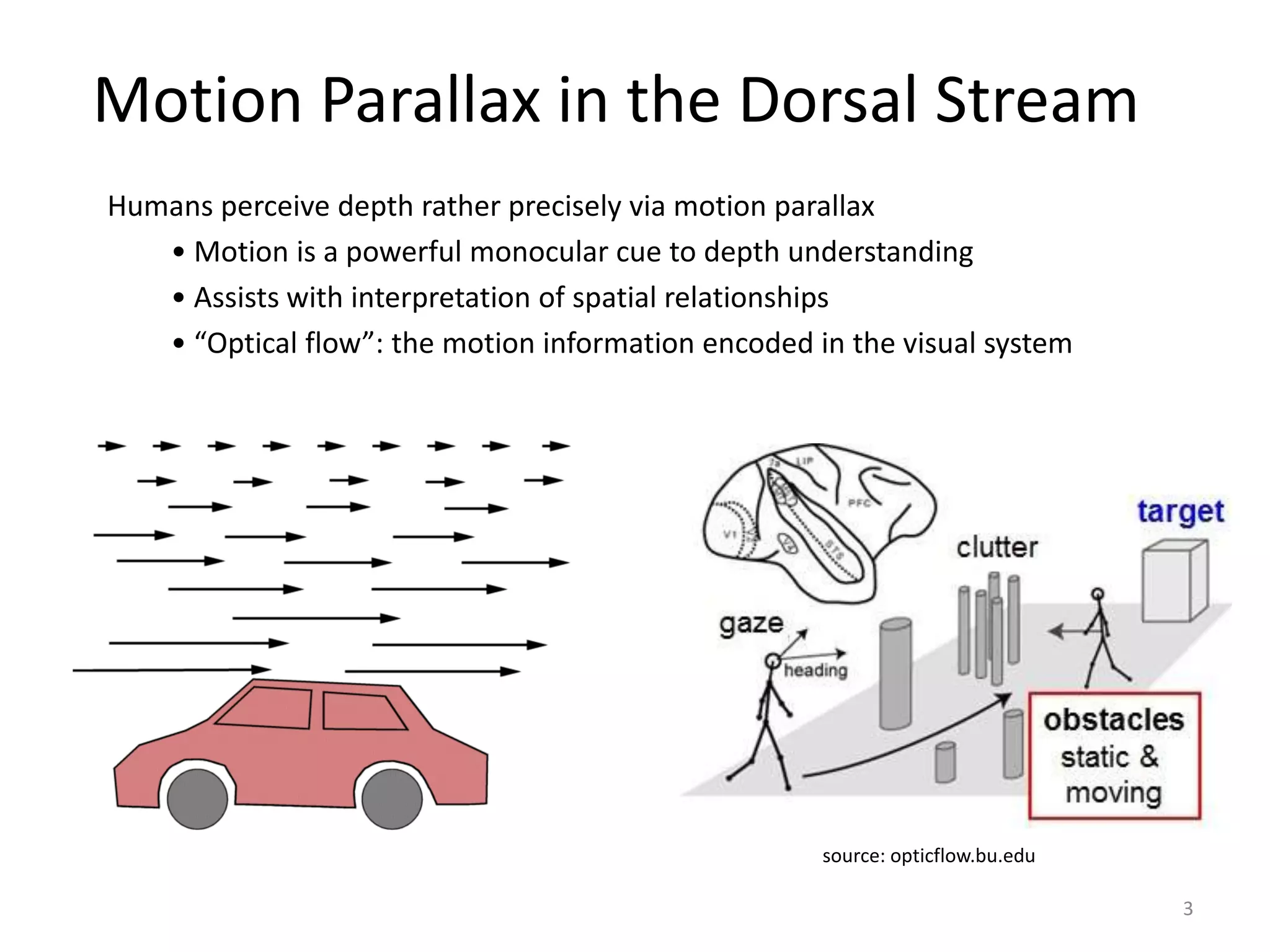
Receptive field can be a powerful tool for decoding
14
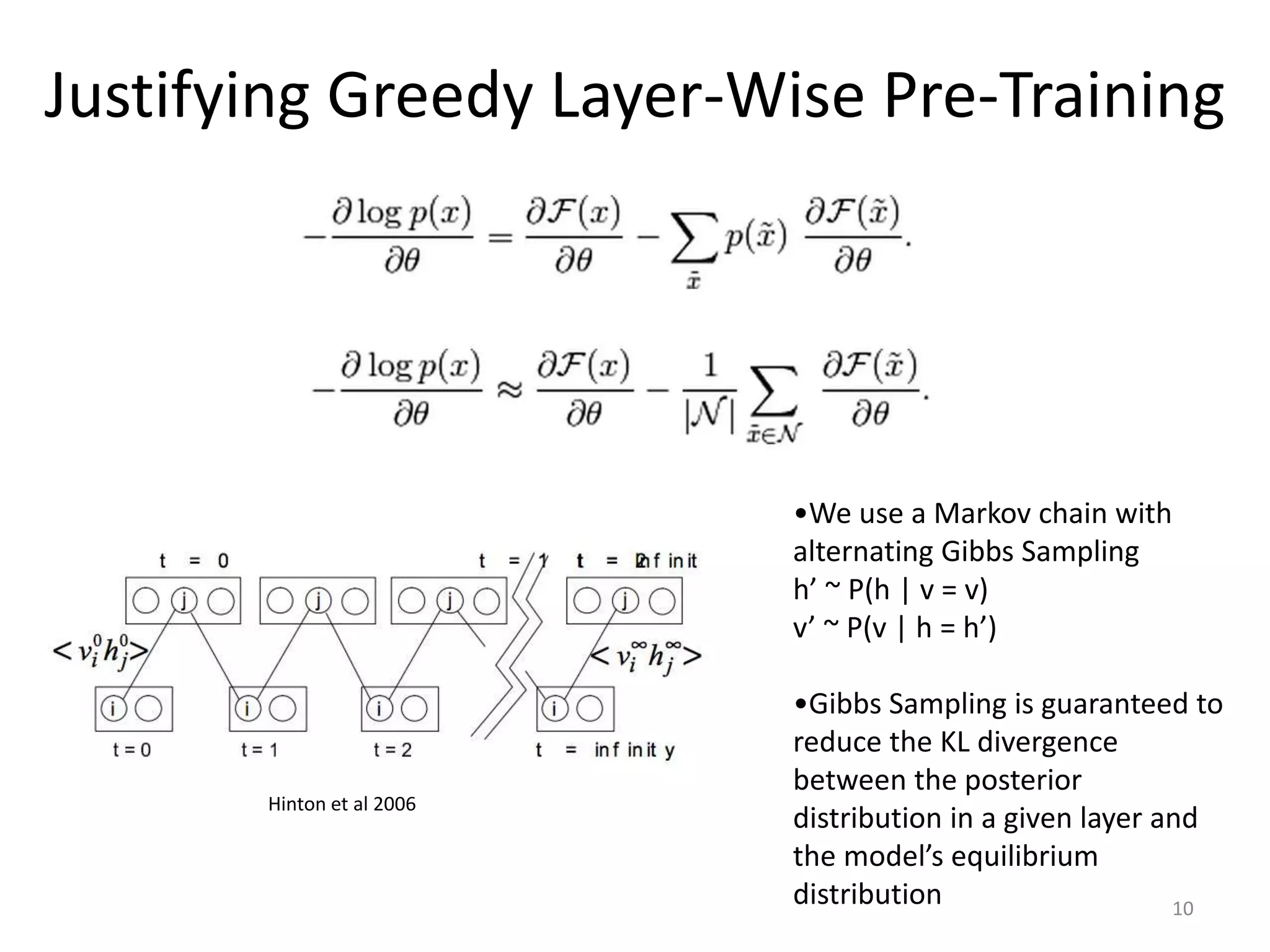
MRF defined by two potential functions:
1) Φ = ∑_i [ (w • x_i − d_i) ^ 2 ]
2) Ψ = ∑_<i,j> [ (d_i − d_j)^2 /( (d_i − d_j)^2 + 1) ) ]
(note: <i,j> = all neighboring pairs i,j)
P(d | x ; alpha, w) = (1/Z) * exp(− (alpha*Ψ + Φ)).
Peter Orchard, University of Edinburgh
ground truth original prediction: 0.595 MRF prediction: 0.630](https://image.slidesharecdn.com/thesispresentation-150419182519-conversion-gate01/75/Thesis-Presentation-14-2048.jpg)





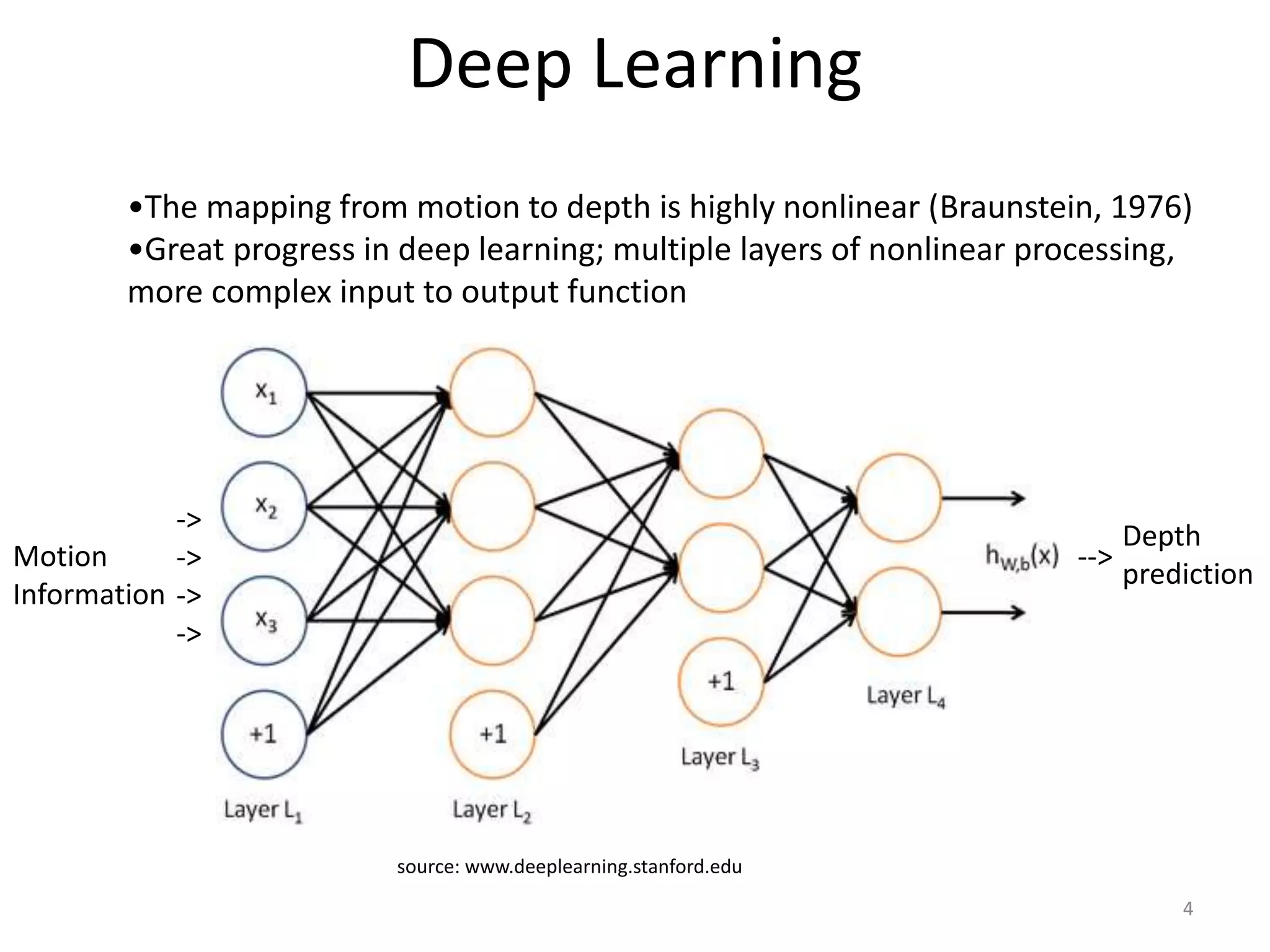
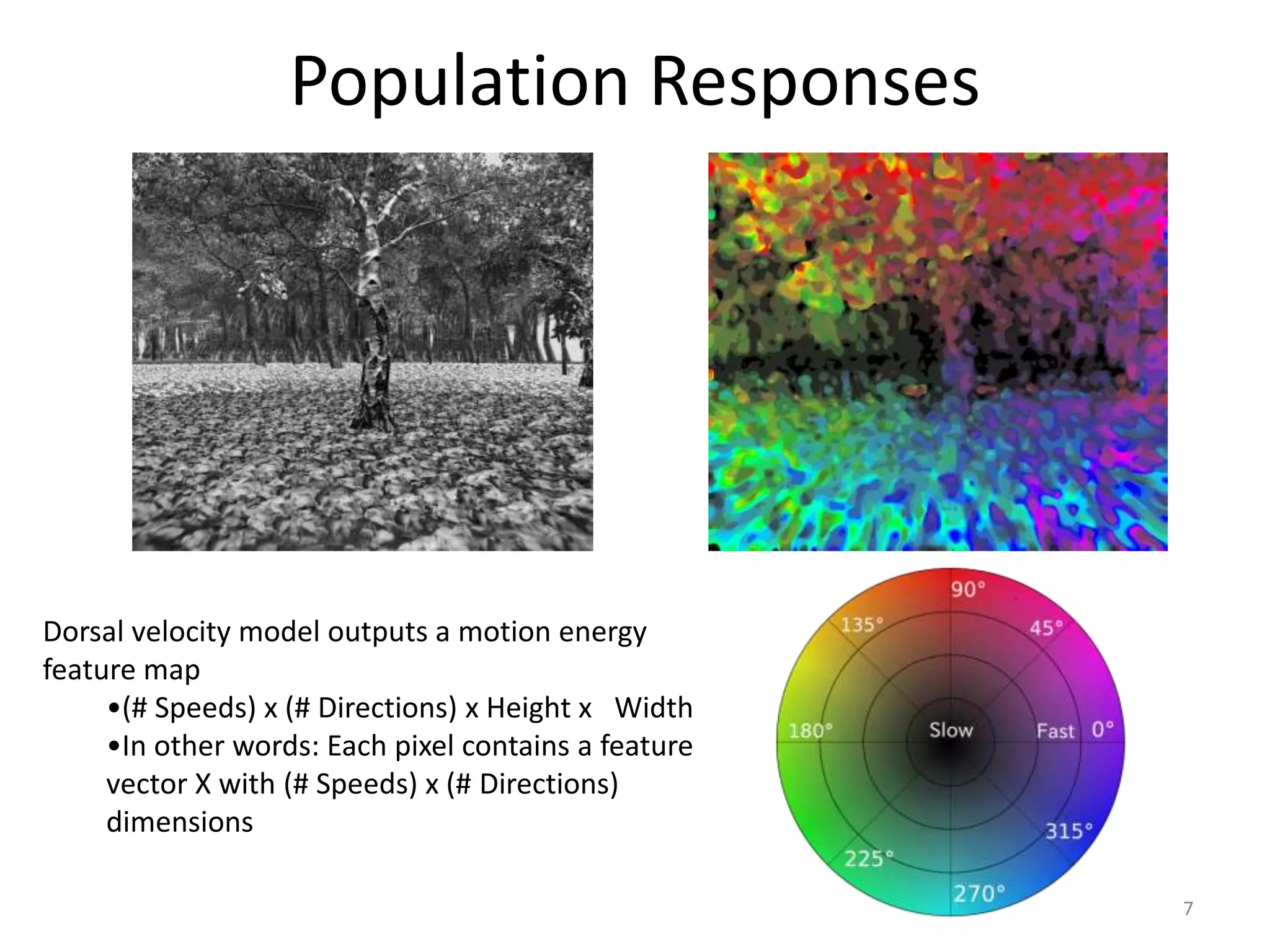
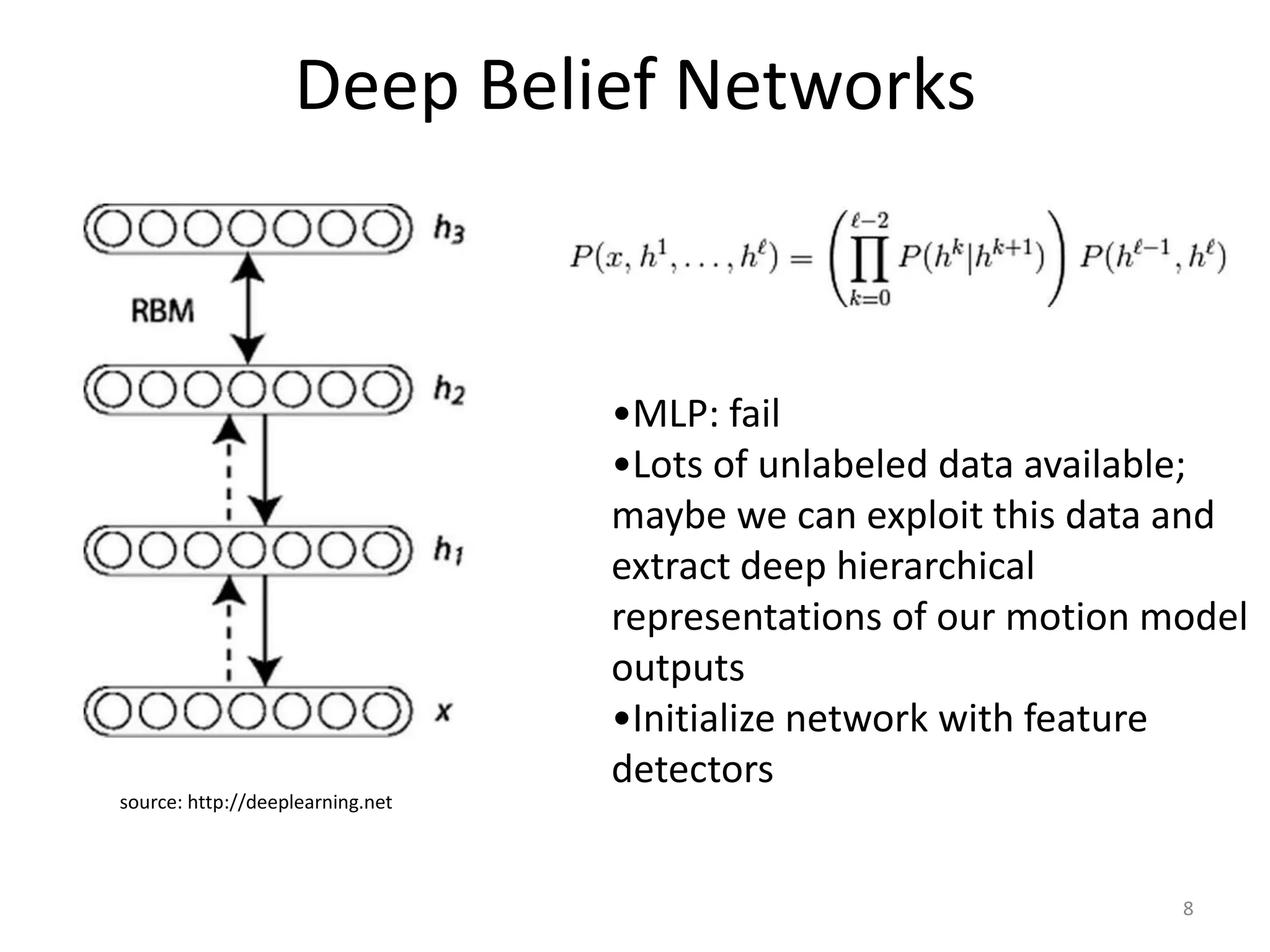
This document proposes using a deep belief network (DBN) to learn depth perception from optical flow information. It describes: 1) Using motion parallax and optical flow cues to perceive depth in humans and insects. 2) Generating labeled training data from 3D graphics scenes to teach the DBN the mapping from motion to depth. 3) The DBN architecture, which takes motion energy maps as input and uses multiple hidden layers and backpropagation to predict depth maps. 4) Test results showing the DBN achieves a higher R^2 score for depth prediction than other models like linear regression.





![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)









































































