Download as PDF, PPTX






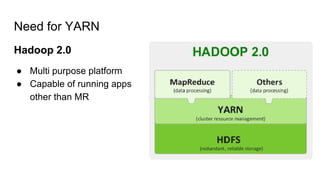
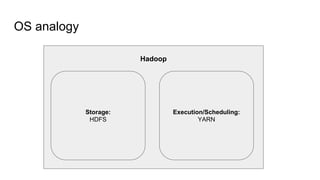

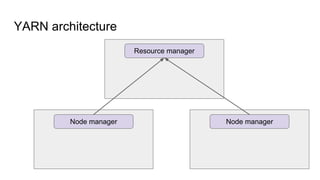
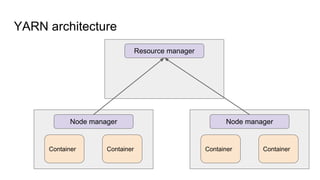
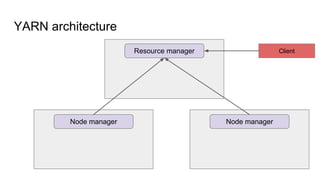
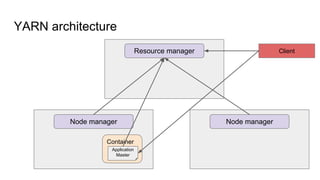
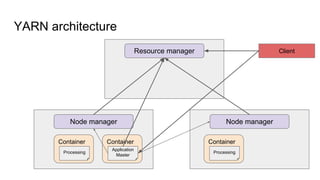

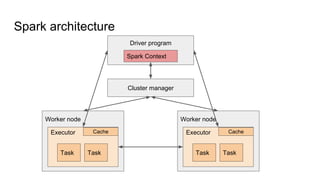


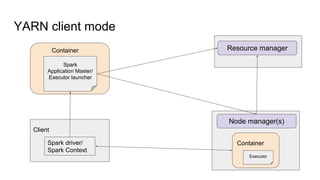

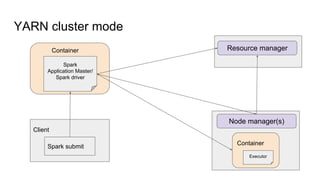



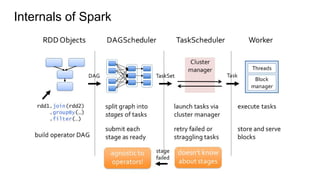
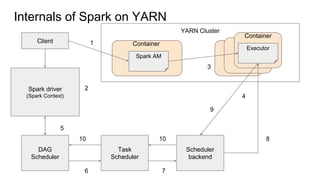






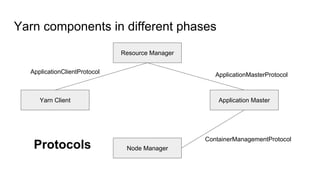






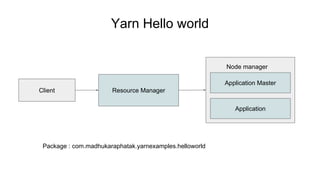


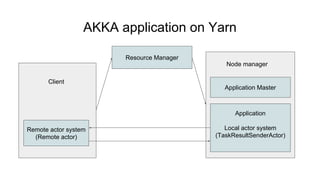



The document provides a comprehensive overview of Apache Spark running on YARN, detailing its architecture, modes (client and cluster), and the necessity for YARN in Hadoop 2.0 as a multi-purpose platform. It discusses Spark's ability to leverage existing clusters, data locality, and resource management, as well as the internals of the Spark-on-YARN execution process. Recent developments include dynamic resource allocation and improving performance through better container management and communication protocols.


















































































![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
