Download as PDF, PPTX


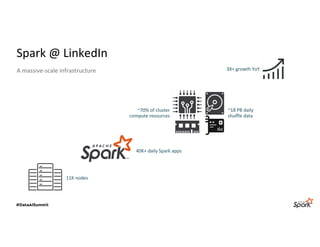
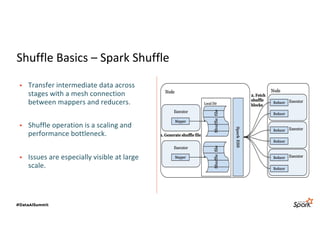



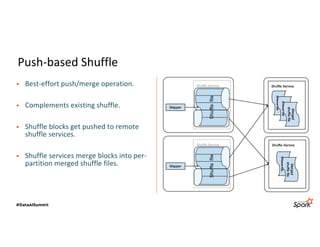
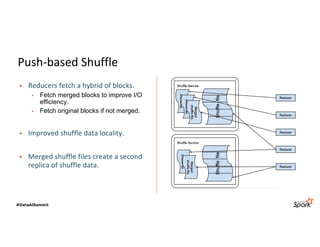

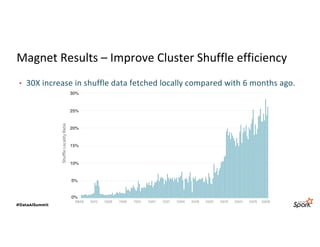
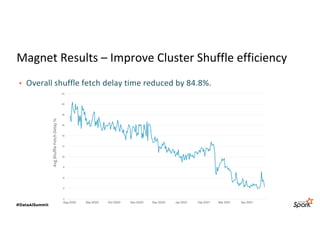

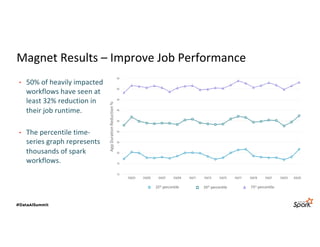
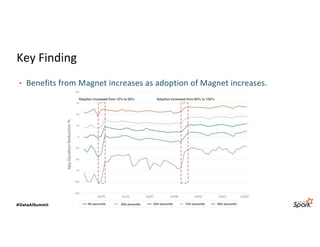


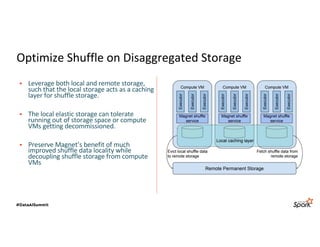




The document discusses LinkedIn's Spark infrastructure and the introduction of the Magnet shuffle service, which addresses significant issues with Spark's shuffle operations by implementing a push-based mechanism to enhance performance and reliability. Magnet has reportedly improved shuffle data efficiency by 30 times and reduced fetch delay time by 84.8%, resulting in notable reductions in job runtimes and resource consumption. Future work includes contributing Magnet back to open-source Spark, optimizing shuffle for disaggregated storage, and supporting Python-centric data processing.























































































