Download as PDF, PPTX









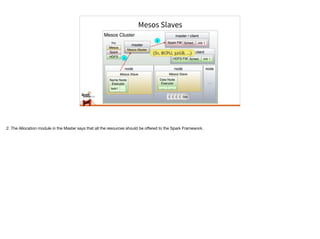
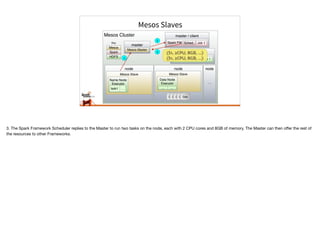
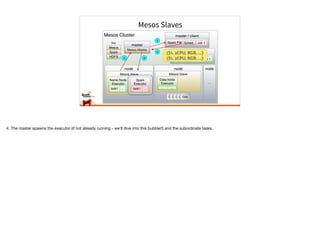


















Typesafe has launched Spark support for Mesosphere's Data Center Operating System (DCOS). Typesafe engineers are contributing to the Mesos support for Spark and Typesafe will provide commercial support for Spark development and production deployment on Mesos. Mesos' flexibility allows many frameworks like Spark to run on top of it. This document discusses Spark on Mesos in coarse-grained and fine-grained modes and some features coming soon like dynamic allocation and constraints.











































































































