Downloaded 166 times








![Local mode
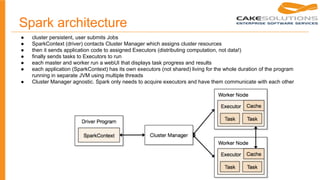
● for application development purposes, no cluster required
● local
○ Run Spark locally with one worker thread (i.e. no parallelism at all).
● local[K]
○ Run Spark locally with K worker threads (ideally, set this to the number of cores on your
machine).
● local[*]
○ Run Spark locally with as many worker threads as logical cores on your machine.
● example local](https://image.slidesharecdn.com/apachespark2-150329135033-conversion-gate01/85/Apache-spark-Installation-9-320.jpg)

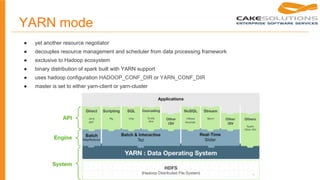










This document provides an overview of installing and deploying Apache Spark, including: 1. Spark can be installed via prebuilt packages or by building from source. 2. Spark runs in local, standalone, YARN, or Mesos cluster modes and the SparkContext is used to connect to the cluster. 3. Jobs are deployed to the cluster using the spark-submit script which handles building jars and dependencies.