The document discusses the derivation and properties of Wiener filters, which are linear filters that minimize the mean square error between the desired signal and the estimate. Specifically:
- It derives the Weiner-Hopf equation, which provides the condition for optimal filter weights to minimize the mean square error.
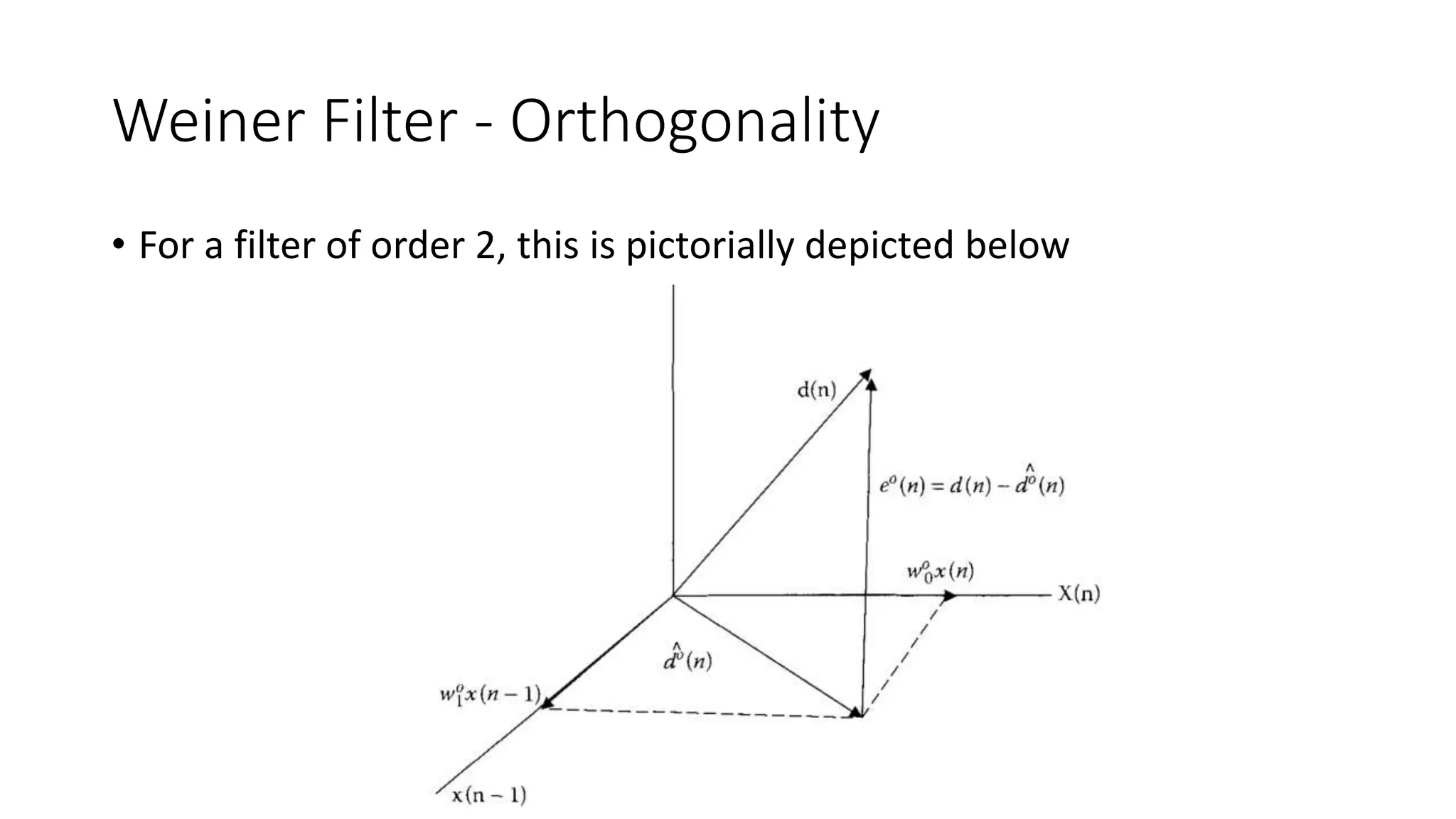
- It shows that the optimal filter output and minimum error are orthogonal.
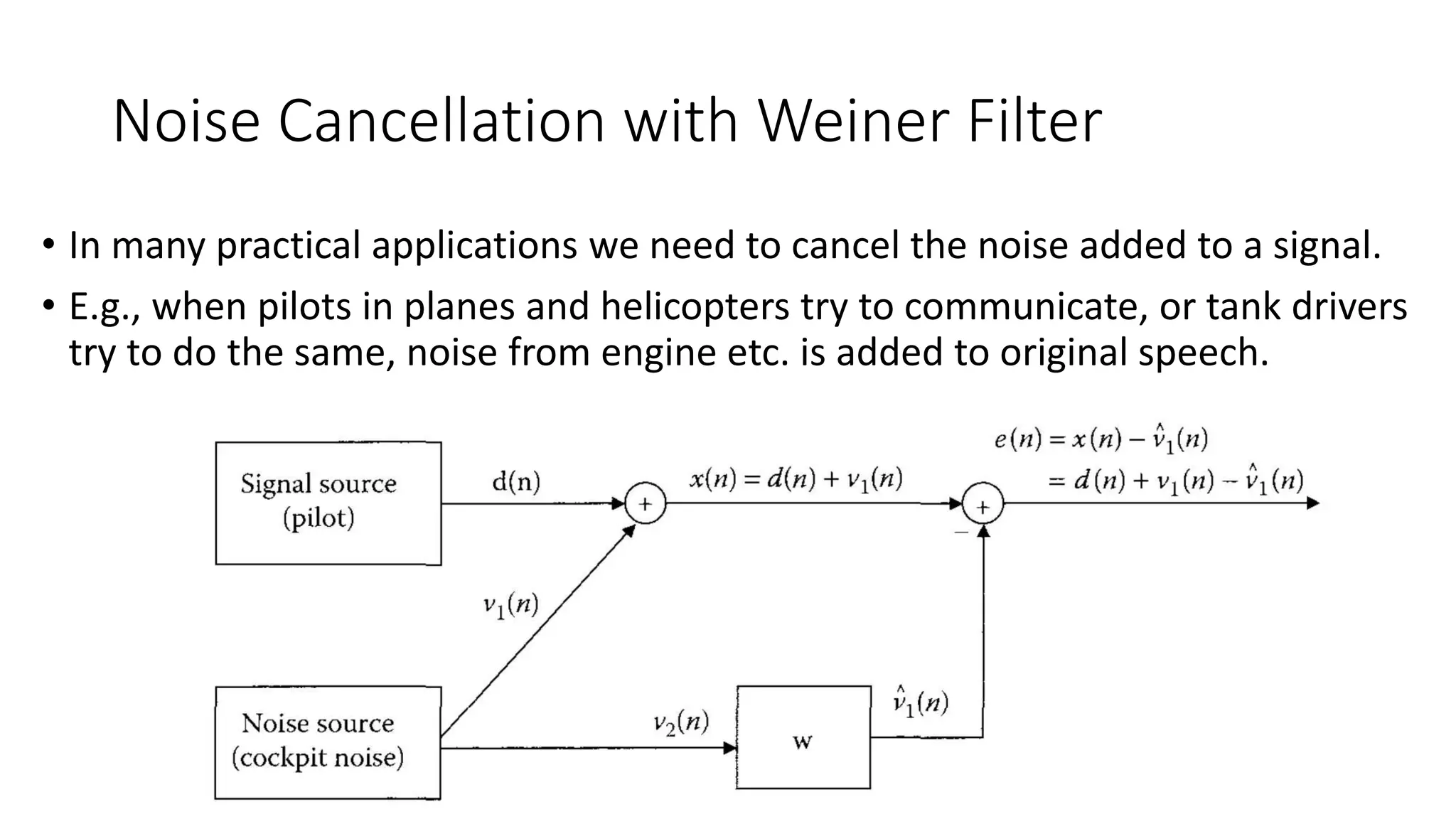
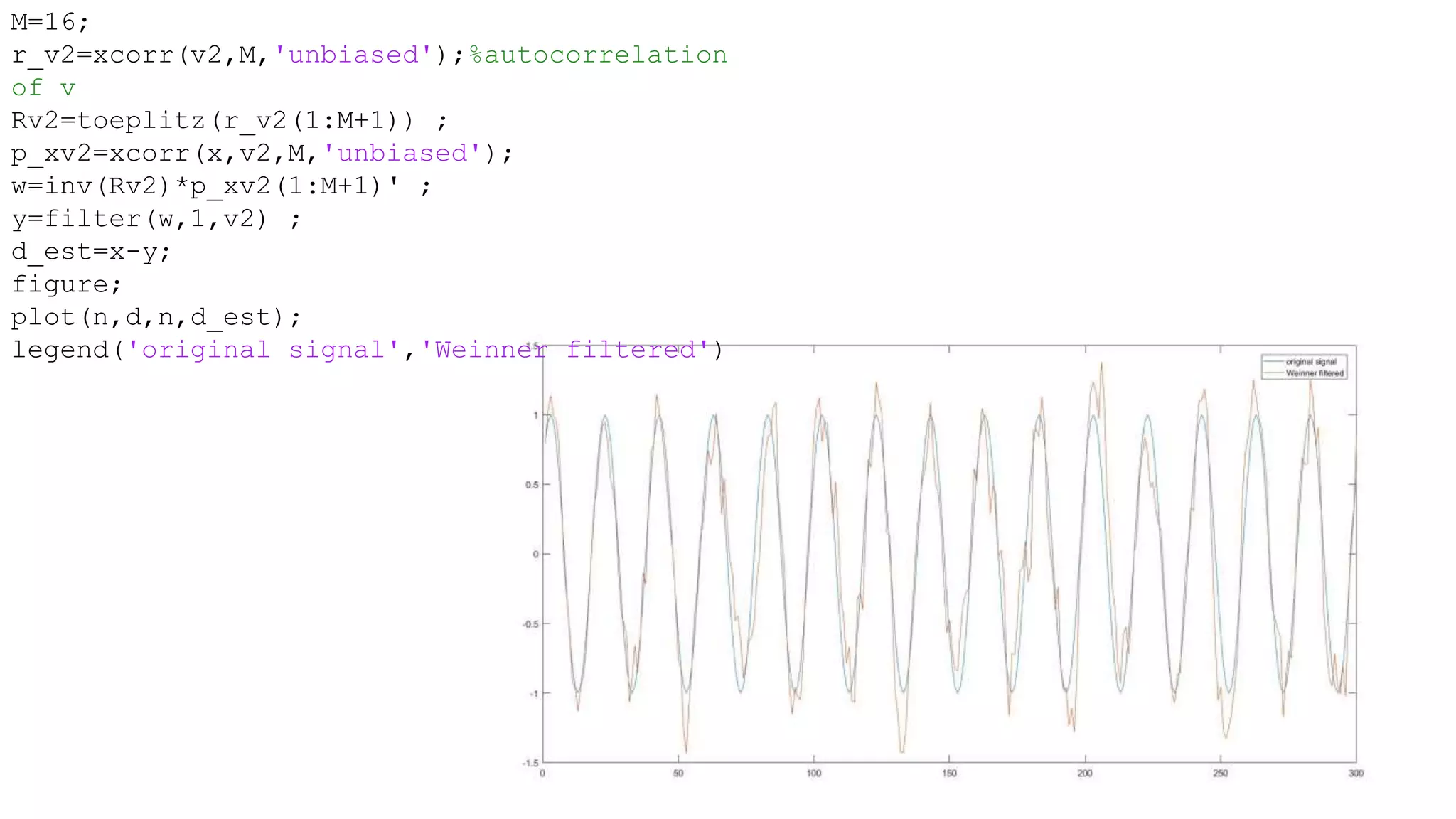
- It discusses how the Weiner filter can be used for applications like noise cancellation by estimating the desired signal using two microphones.
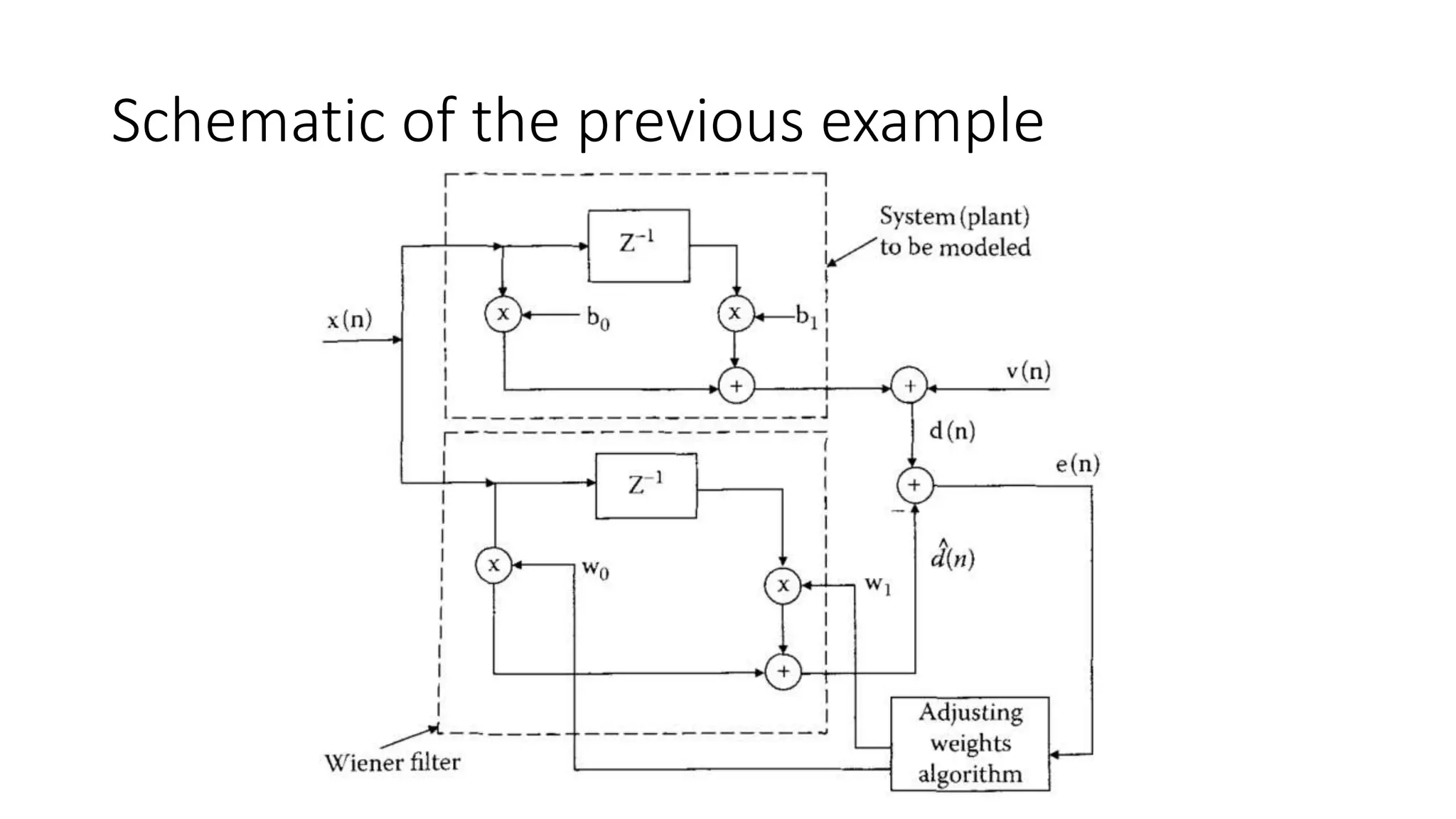
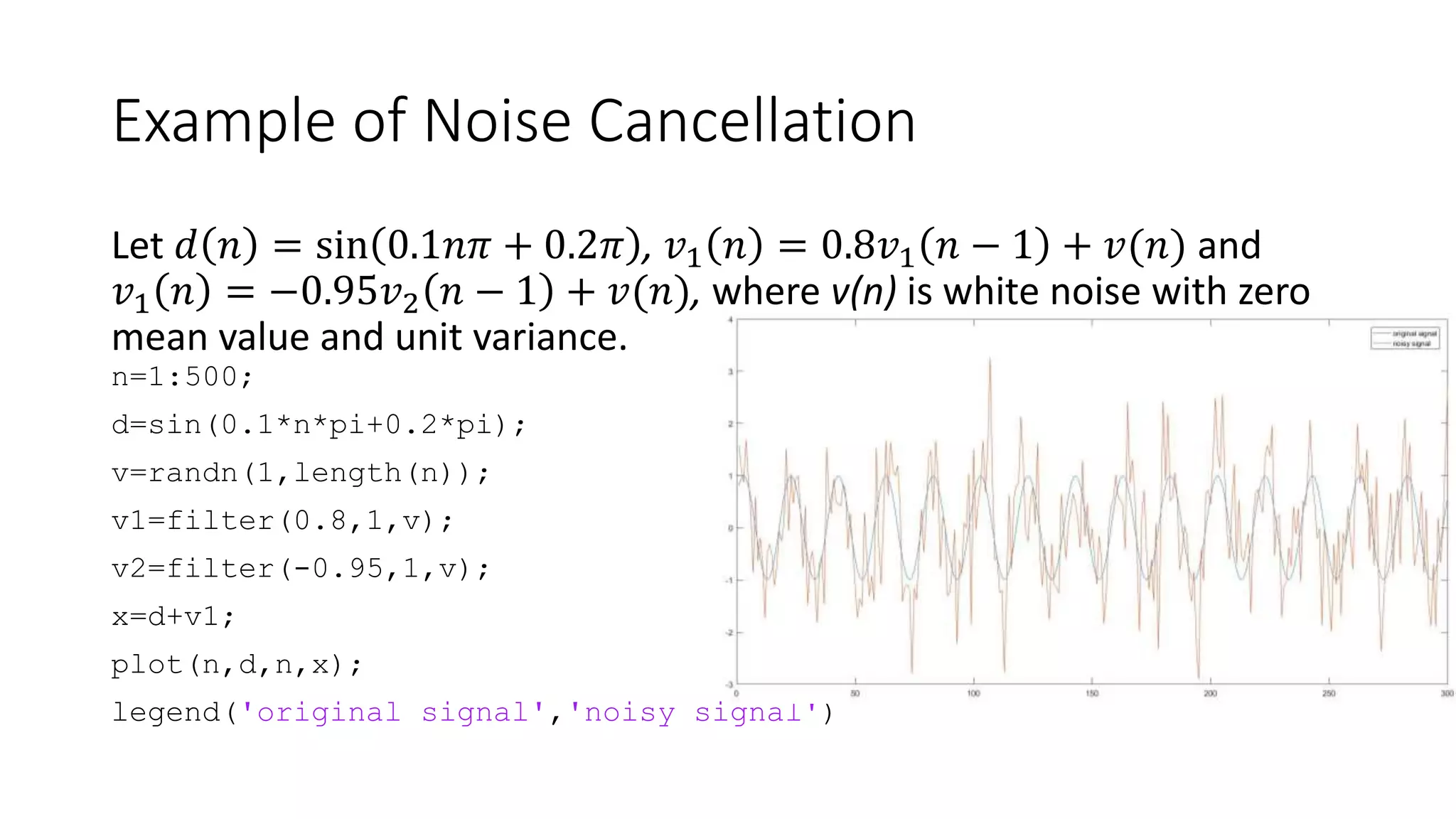
- It provides an example of applying a Weiner filter to cancel noise from a signal measured by two microphones mounted on a pilot's helmet.
![Av-738
Adaptive Filter Theory
Lecture 3- Optimum Filtering
[Weiner Filters]
Dr. Bilal A. Siddiqui
Air University (PAC Campus)
Spring 2018](https://image.slidesharecdn.com/av-738-aft-spr18-lecture03-optimumfilters-weinerwk3-180215235757/75/Av-738-Adaptive-Filtering-Wiener-Filters-wk-3-1-2048.jpg)



![Weiner-Hopf Equation
• Let’s re-write the orthogonality condition in terms of optimal weights (k=0,1,2,…M-1)
𝐸 𝑢 𝑛 − 𝑘 𝑒0
∗
𝑛 = 𝐸 𝑢 𝑛 − 𝑘 𝑑∗
−
𝑙=0
𝑀−1
𝑤𝑙,0 𝑢∗
𝑛 − 𝑙 = 0
Expanding the equation for
𝑙=0
𝑀−1
𝑤𝑙,0 𝐸 𝑢 𝑛 − 𝑘 𝑢∗
𝑛 − 𝑙 = 𝐸 𝑢 𝑛 − 𝑘 𝑑∗
𝑛
Recognizing autocorrelation 𝑟 𝑙 − 𝑘 = 𝐸 𝑢 𝑛 − 𝑘 𝑢∗ 𝑛 − 𝑙 and cross-correlation 𝑝 −𝑘 = 𝐸 𝑢 𝑛 − 𝑘 𝑑∗ 𝑛
𝑙=0
𝑀−1
𝑤𝑙,0 𝑟 𝑙 − 𝑘 = 𝑝 −𝑘
This can be written in matrix form for 𝑢 𝑛 = [𝑢 𝑛 𝑢 𝑛 − 1 … 𝑢 𝑛 − 𝑀 − 1 ], 𝑹 𝒖 = 𝐸 𝑢 𝑛 𝑢 𝐻
𝑛 ,
𝒑 𝒅𝒖 = 𝑝 0 𝑝 1 … 𝑝 𝑀 − 1 and 𝒘 𝟎 = 𝑤0,0 𝑤1,0 … 𝑤 𝑀−1,0
𝒘 𝟎 = 𝑹 𝒖
−𝟏
𝒑 𝒅𝒖
This is known as the Weiner-Hopf equation](https://image.slidesharecdn.com/av-738-aft-spr18-lecture03-optimumfilters-weinerwk3-180215235757/75/Av-738-Adaptive-Filtering-Wiener-Filters-wk-3-6-2048.jpg)

![Example: System Identification
• Find the optimum filter coefficients wo and w1 of the Wiener filter,
which approximates (models) the unknown FIR system with
coefficients bo= 1.5 and b1= 0.5 and contaminated with additive white
uniformly distributed noise of 0.02 variance. Input is white Gaussian
noise of variance 1.
clc;clear;
n =0.5*(rand(1,200)-0.5);%n=noise vector with zero mean and variance 0.02
u=randn(1,200);% u=data vector entering the system
y=filter( [1.5 0.5],1,u); %filter output
d=y + n; % desired output
[ru,lagsru]=xcorr(u,1,'unbiased') ;
Ru=toeplitz(ru(1:2));
[pdu,lagsdu]=xcorr(u,d,1,'unbiased') ;
W_opt=inv(Ru) *pdu(1:2)' ; % optimum Weiner filter weights
sigma2d=xcorr(d,d,0);%autocorrelation of d at zero lag
jmin=mean((d-filter(w_opt,1,u)).^2);](https://image.slidesharecdn.com/av-738-aft-spr18-lecture03-optimumfilters-weinerwk3-180215235757/75/Av-738-Adaptive-Filtering-Wiener-Filters-wk-3-8-2048.jpg)
![Error Surface
w=[linspace(-3*w_opt(1),3*w_opt(1),50);linspace(-9*w_opt(2),9*w_opt(2),50)];
[w1,w2]=meshgrid(w(1,:),w(2,:));
for k=1:length(w1)
for l=1:length(w2)
J(k,l)=mean((d-filter([w1(k,l) w2(k,l)],1,u)).^2);
end
end
surf(w1,w2,J);
xlabel('W_1');ylabel('W_2');zlabel('Cost Function, J');](https://image.slidesharecdn.com/av-738-aft-spr18-lecture03-optimumfilters-weinerwk3-180215235757/75/Av-738-Adaptive-Filtering-Wiener-Filters-wk-3-9-2048.jpg)








![Sensor Fusion Study - Ch15. The Particle Filter [Seoyeon Stella Yang]](https://cdn.slidesharecdn.com/ss_thumbnails/particlefilter-200815094542-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch5. The discrete-time Kalman filter [박정은]](https://cdn.slidesharecdn.com/ss_thumbnails/ch5-200712161939-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch8. The Continuous-Time Kalman Filter [이해구]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter8-thecontinuoustimekalmanfilter-200715035017-thumbnail.jpg?width=640&height=640&fit=bounds)

![Sensor Fusion Study - Ch7. Kalman Filter Generalizations [김영범]](https://cdn.slidesharecdn.com/ss_thumbnails/ch7kalmanfiltergeneralizations-200715034919-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch13. Nonlinear Kalman Filtering [Ahn Min Sung]](https://cdn.slidesharecdn.com/ss_thumbnails/nonlinearkalmanfiltering200717-200815094232-thumbnail.jpg?width=640&height=640&fit=bounds)








































![ME 312 Mechanical Machine Design [Screws, Bolts, Nuts]](https://cdn.slidesharecdn.com/ss_thumbnails/me312-dsulec10-screws-170213050612-thumbnail.jpg?width=640&height=640&fit=bounds)
![ME 312 Mechanical Machine Design - Introduction [Week 1]](https://cdn.slidesharecdn.com/ss_thumbnails/me312-dsulec01-170213050149-thumbnail.jpg?width=640&height=640&fit=bounds)






























