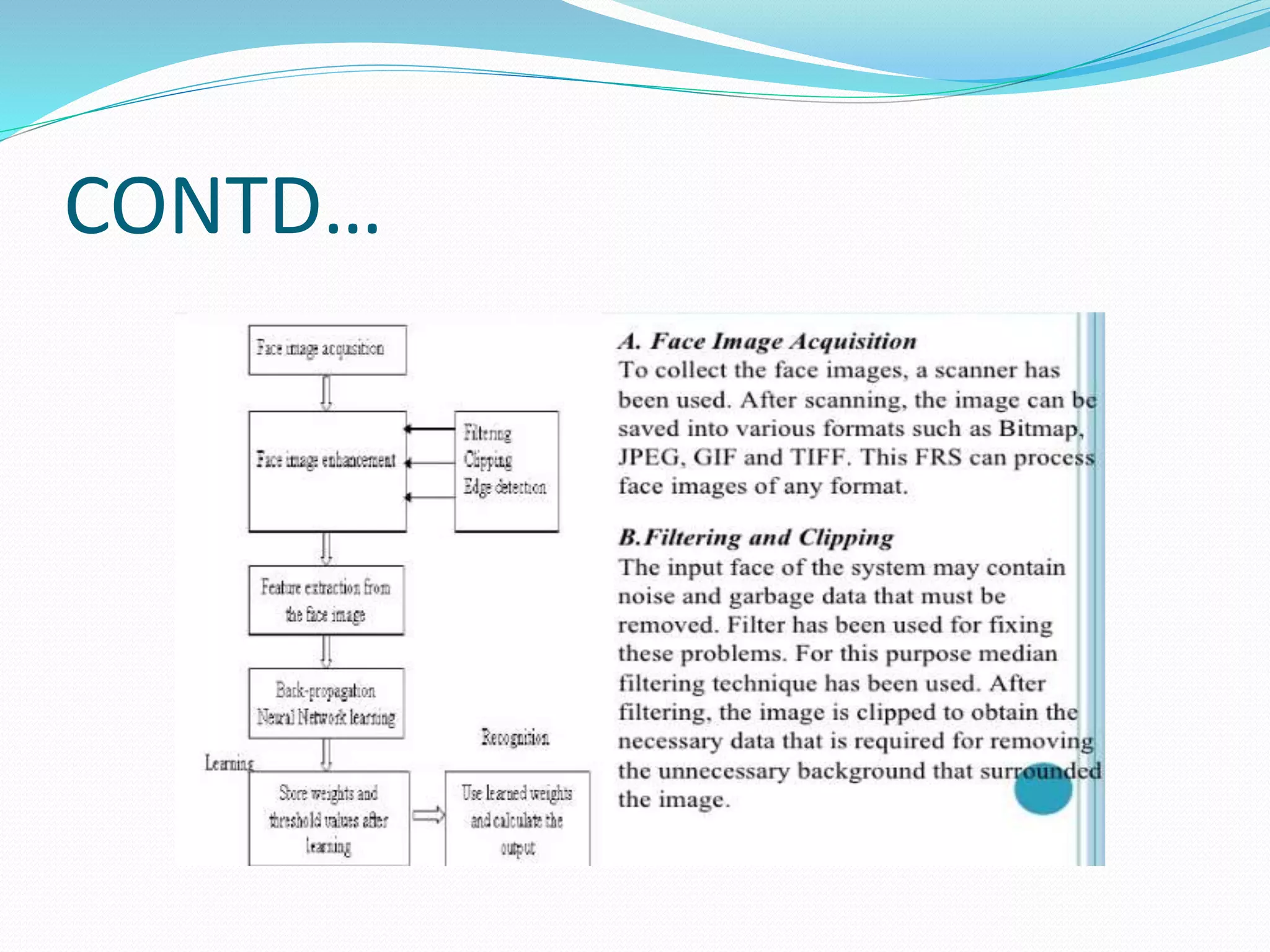
The document describes the backpropagation algorithm for training multilayer neural networks. It discusses how backpropagation uses gradient descent to minimize error between network outputs and targets by calculating error gradients with respect to weights. The algorithm iterates over examples, calculates error, computes gradients to update weights. Momentum can be added to help escape local minima. Backpropagation can learn representations in hidden layers and is prone to overfitting without validation data to select the best model.