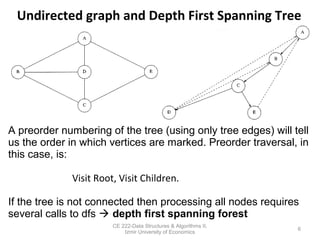
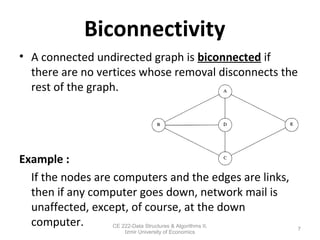
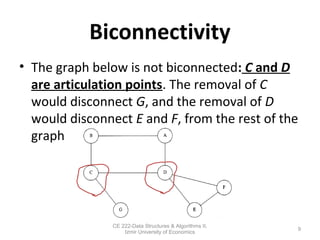
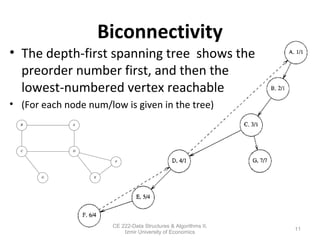
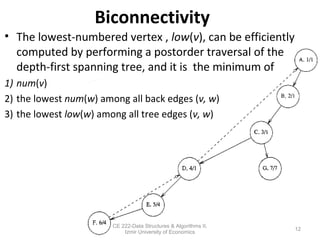
This document discusses depth-first search (DFS) algorithms and their applications to finding spanning trees and articulation points in graphs. It begins by explaining how DFS generalizes preorder tree traversal and avoids cycles in arbitrary graphs by marking visited vertices. DFS takes O(V+E) time on graphs. The document then explains how DFS can be used to find a depth-first spanning tree and identify biconnected components and articulation points via numbering schemes like num(v) and low(v).




![Depth First Search Algorithm
void dfs( vertex v )
{
visited[v] = TRUE;
for each w adjacent to v
if( !visited[w] )
dfs( w );
}
4
Because this
strategy guarantees
that each edge is
encountered only
once, the total time
to perform the
traversal is O(|E| + |
V|), as long as
adjacency lists are
used.
CE 222-Data Structures & Algorithms II,
Izmir University of Economics](https://image.slidesharecdn.com/2-150507095519-lva1-app6892/85/2-5-graph-dfs-4-320.jpg)