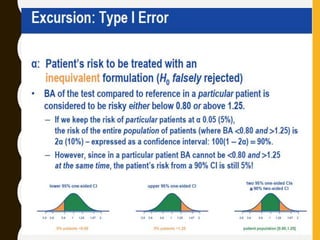
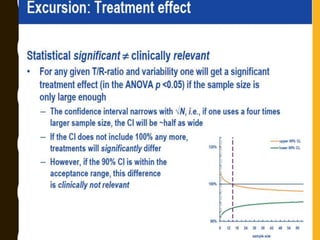
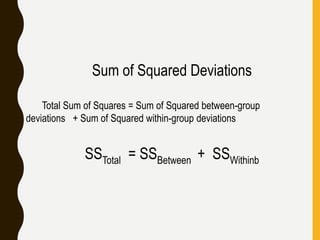
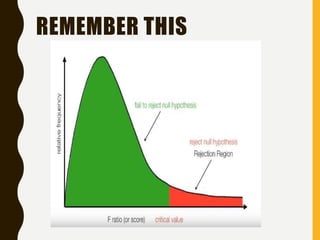
The document discusses statistical methods for determining sample sizes and analyzing pharmacokinetic (PK) measures to assess bioequivalence between test and reference formulations. It emphasizes the importance of hypothesis testing, outlining conventional methods and the inadequacies associated with them, particularly regarding conclusions on equality. Additionally, it details procedures for analyzing data using ANOVA and the factors influencing sample size calculations in bioequivalence studies.








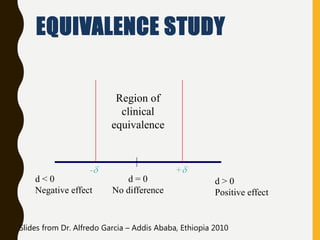
![INTERVAL HYPOTHESIS OR TWO ONE-
SIDED TESTS
Redefine the null hypothesis: How?
Solution: It is like changing the null to the alternative
hypothesis and vice versa.
Alternative hypothesis test: Schuirmann, 1981
This is equivalent to:
H 0 : T - R < D1 or T - R > D2
H A : D1 T - R D2
It is called as an interval hypothesis because the equivalence hypothesis is in
the alternative hypothesis and it is expressed as an interval
bioequivalence
bioinequivalence
T and R population mean for test and reference
formulation respectively
[D1 ; D2] Absolute equivalence
interval
H 0 : T - R < D1
H 0 : T - R > D2
H A : D1 T - R
H A : T - R D2](https://image.slidesharecdn.com/2-211010095251/85/2-0-statistical-methods-and-determination-of-sample-size-8-320.jpg)





















![AN EXAMPLE ANOVA
SITUATION
Subjects: 25 patients with blisters
Treatments: Treatment A, Treatment B, Placebo
Measurement: # of days until blisters heal
Data [and means]:
• A: 5,6,6,7,7,8,9,10 [7.25]
• B: 7,7,8,9,9,10,10,11 [8.875]
• P: 7,9,9,10,10,10,11,12,13 [10.11]
Are these differences significant?](https://image.slidesharecdn.com/2-211010095251/85/2-0-statistical-methods-and-determination-of-sample-size-34-320.jpg)












































































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)









