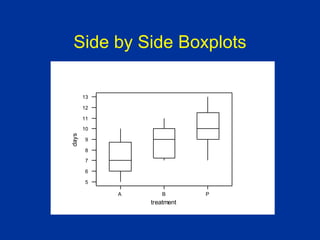
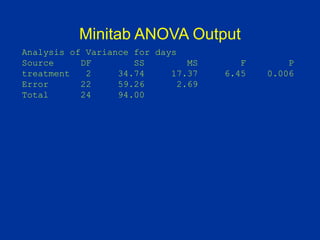
ANOVA (analysis of variance) was used to determine if the healing times of blisters (in days) were significantly different between three treatment groups: Treatment A, Treatment B, and placebo. The data met the assumptions of ANOVA. The ANOVA results showed a significant difference between the groups (p=0.006). Post hoc tests revealed the placebo group took significantly longer to heal than Treatment A, with no other significant differences between the groups.



![An example ANOVA situation
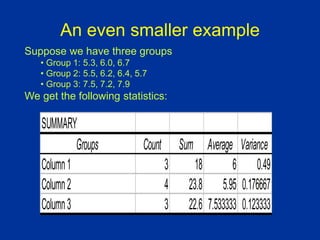
Subjects: 25 patients with blisters
Treatments: Treatment A, Treatment B, Placebo
Measurement: # of days until blisters heal
Data [and means]:
• A: 5,6,6,7,7,8,9,10 [7.25]
• B: 7,7,8,9,9,10,10,11 [8.875]
• P: 7,9,9,10,10,10,11,12,13 [10.11]
Are these differences significant?](https://image.slidesharecdn.com/anovas01-230703170607-d2e10eaa/85/ANOVAs01-ppt-3-320.jpg)










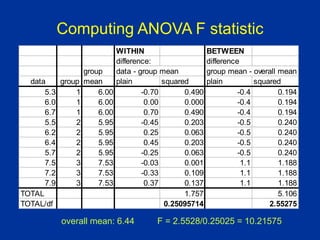





![Connections between SSE, MSE,
and standard deviation
So SS[Within Group i] = (si
2) (dfi )
i
i
i
ij
i
df
i
SS
n
x
x
s
]
Group
Within
[
1
2
2
This means that we can compute SSE from the
standard deviations and sizes (df) of each group:
)
(
)
1
(
]
[
]
[
2
2
i
i
i
i df
s
n
s
i
Group
Within
SS
Within
SS
SSE
Remember:](https://image.slidesharecdn.com/anovas01-230703170607-d2e10eaa/85/ANOVAs01-ppt-23-320.jpg)


![R2 Statistic
SST
SSG
Total
SS
Between
SS
R
]
[
]
[
2
R2 gives the percent of variance due to between
group variation
This is very much like the R2 statistic that we
computed back when we did regression.](https://image.slidesharecdn.com/anovas01-230703170607-d2e10eaa/85/ANOVAs01-ppt-26-320.jpg)



















































