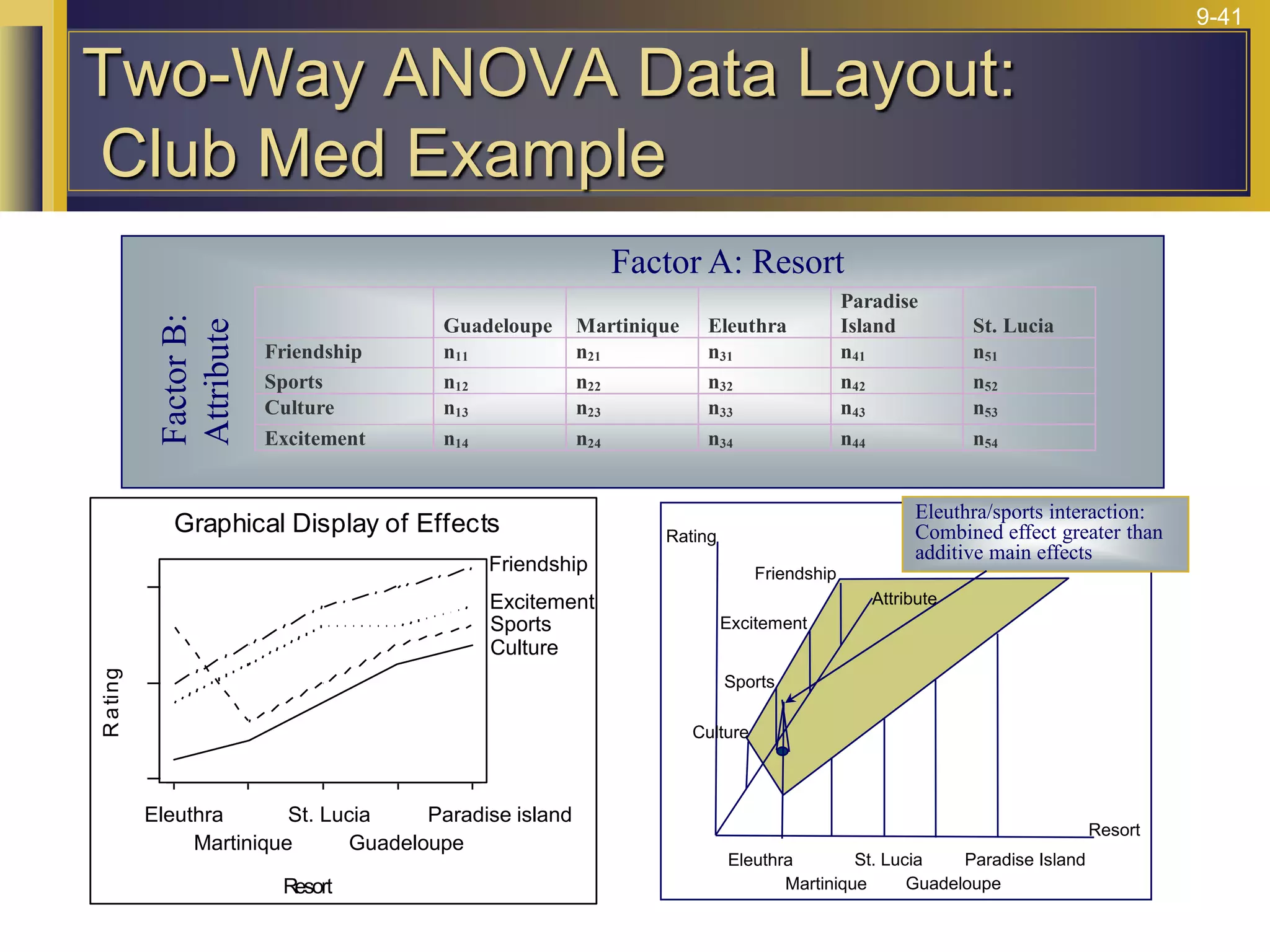
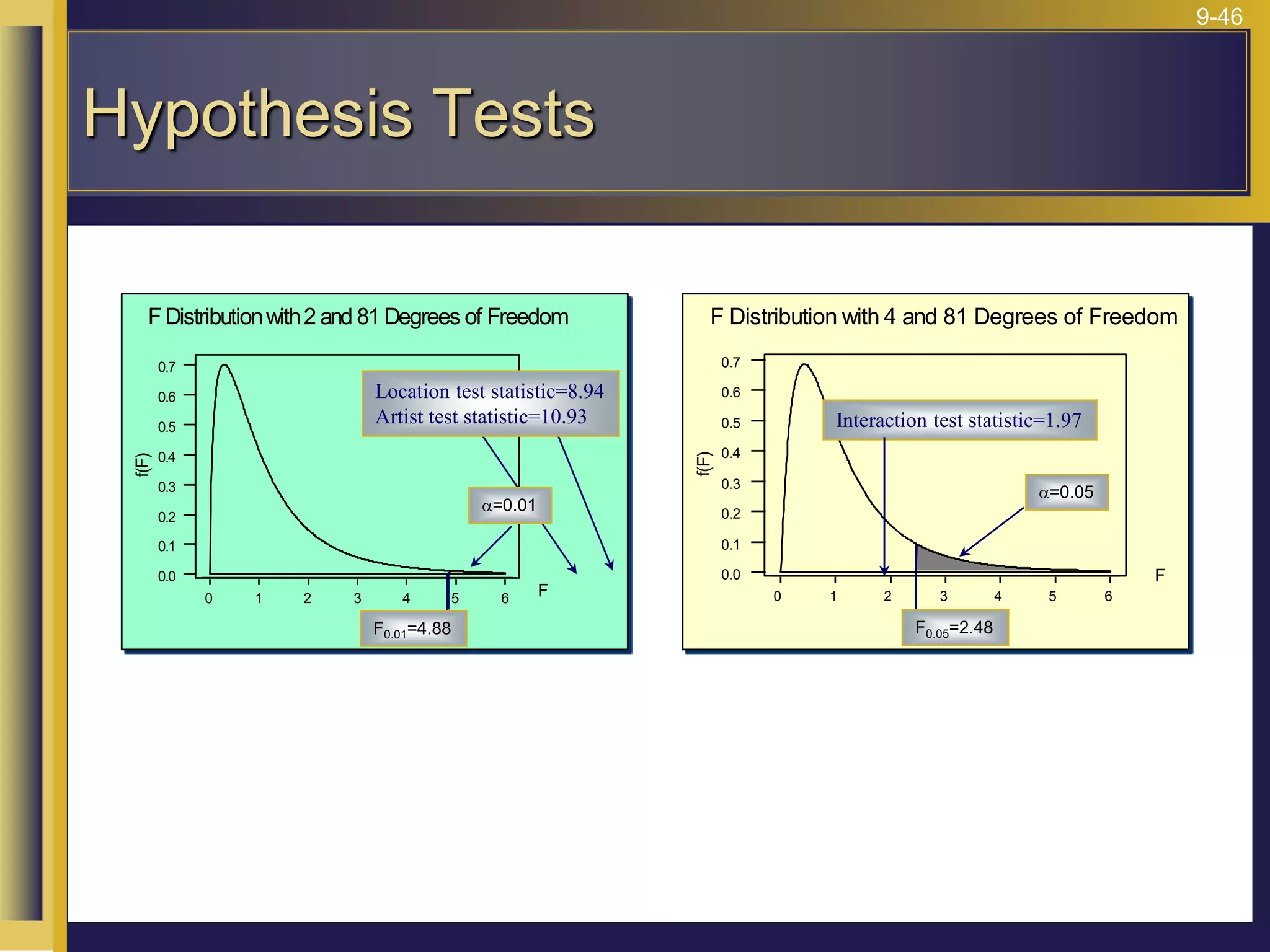
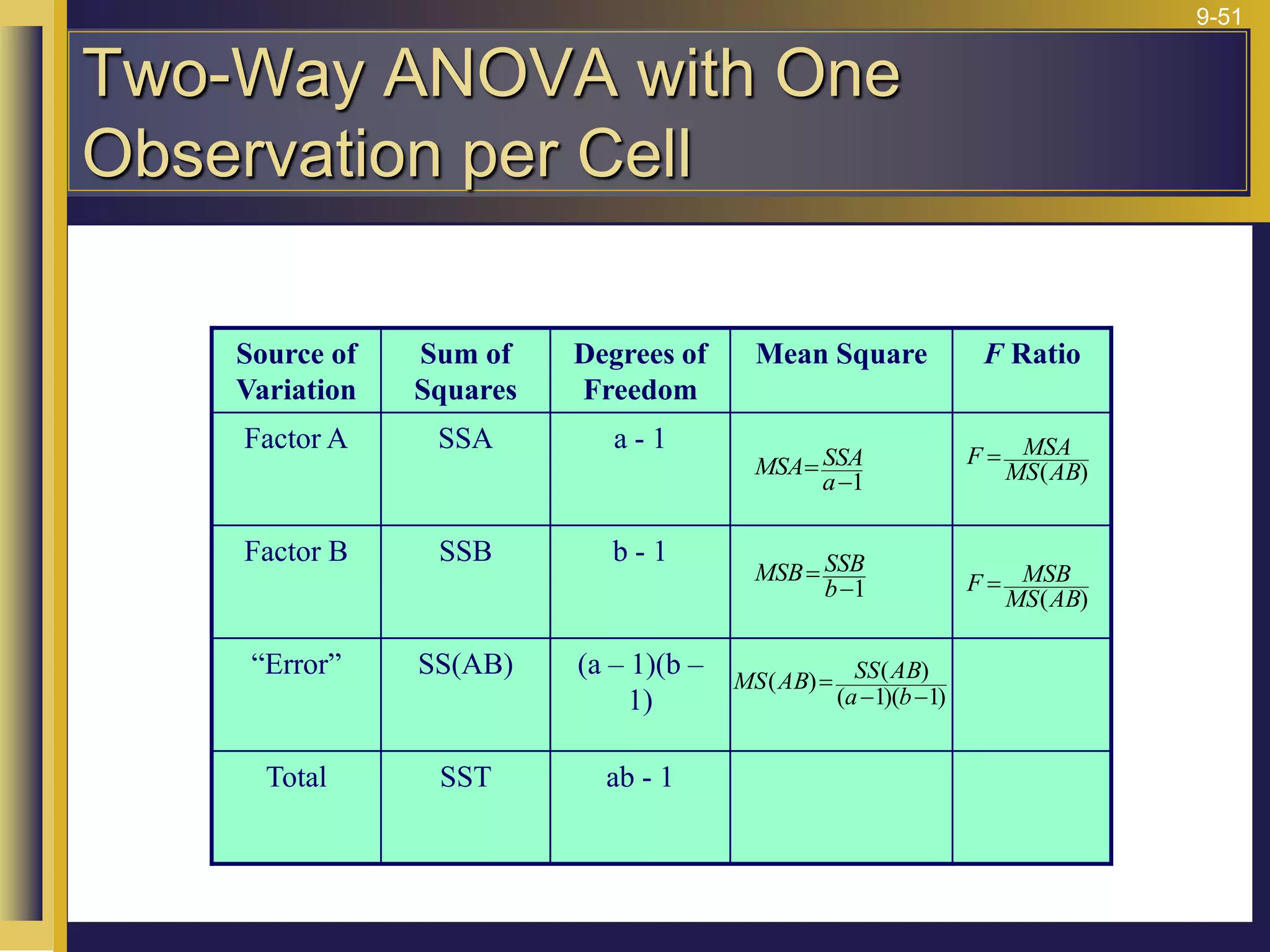
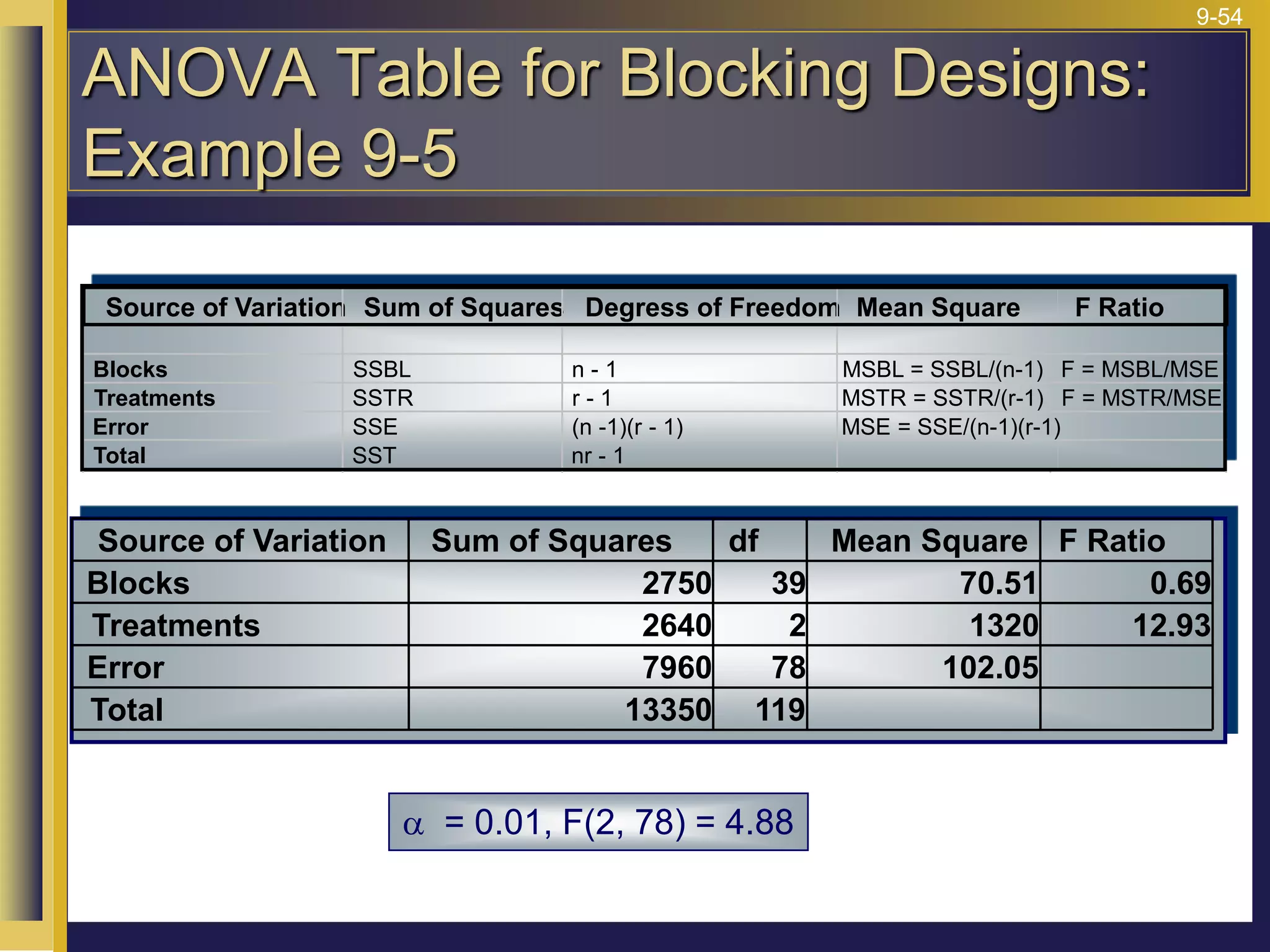
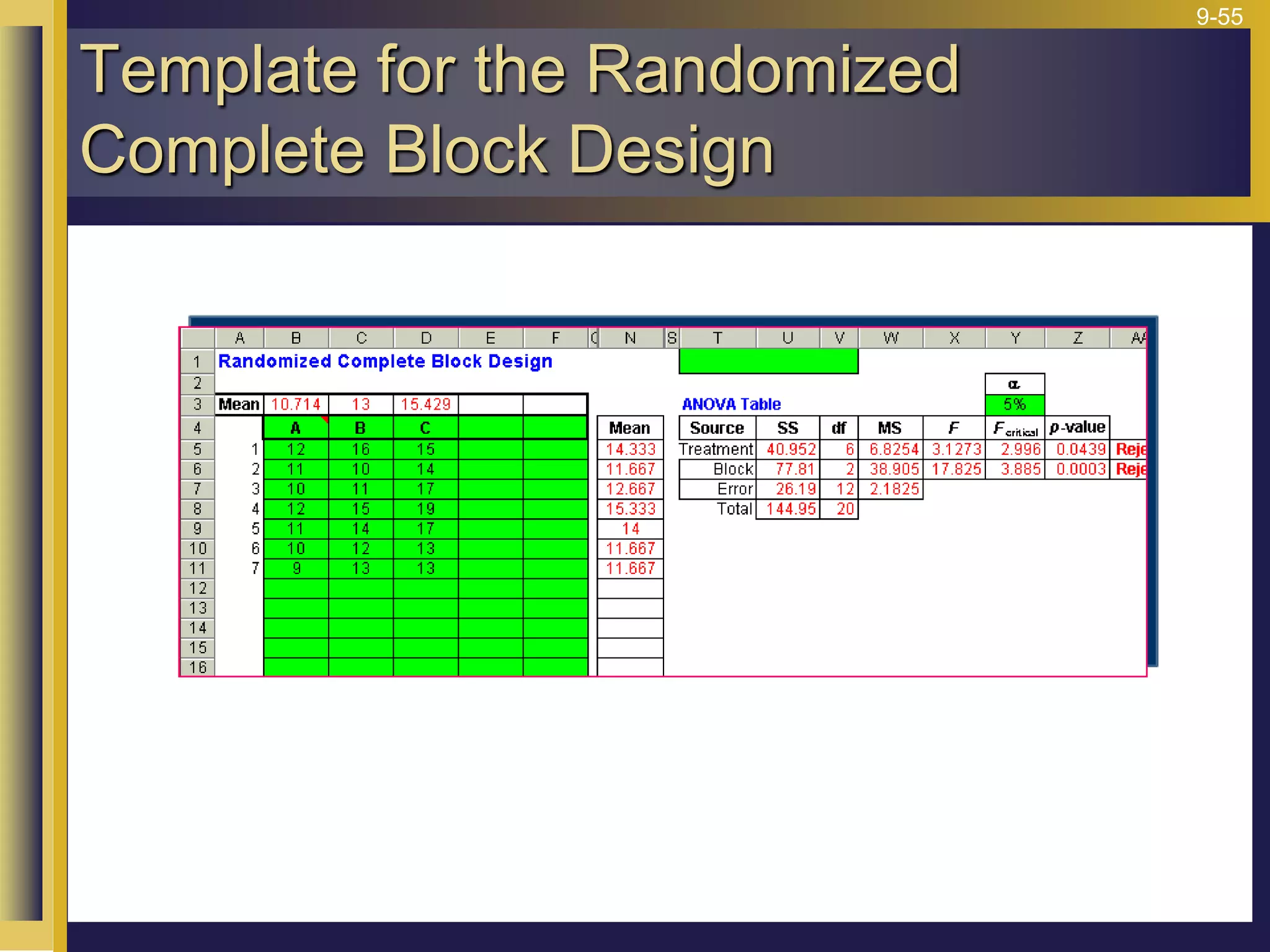
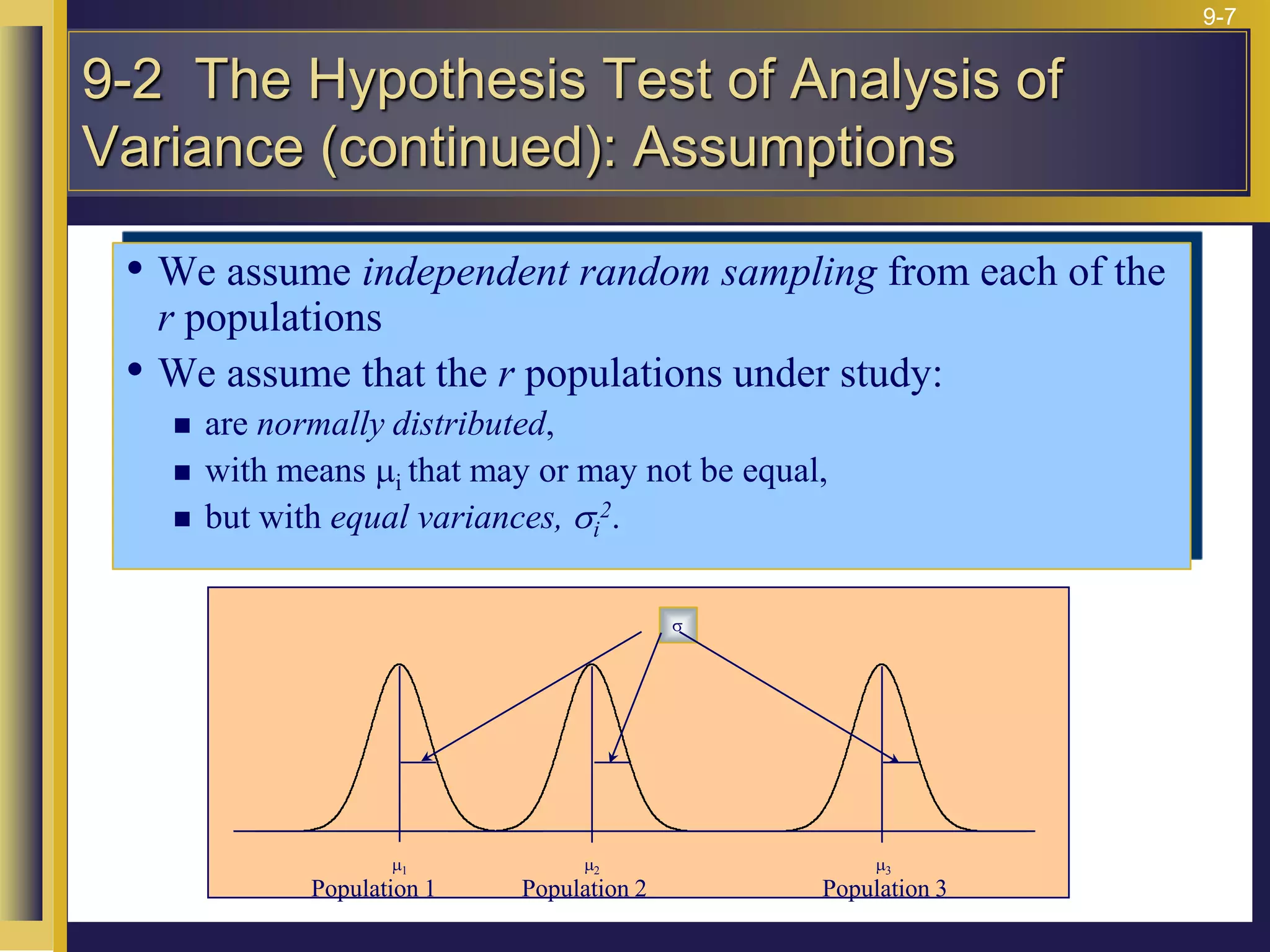
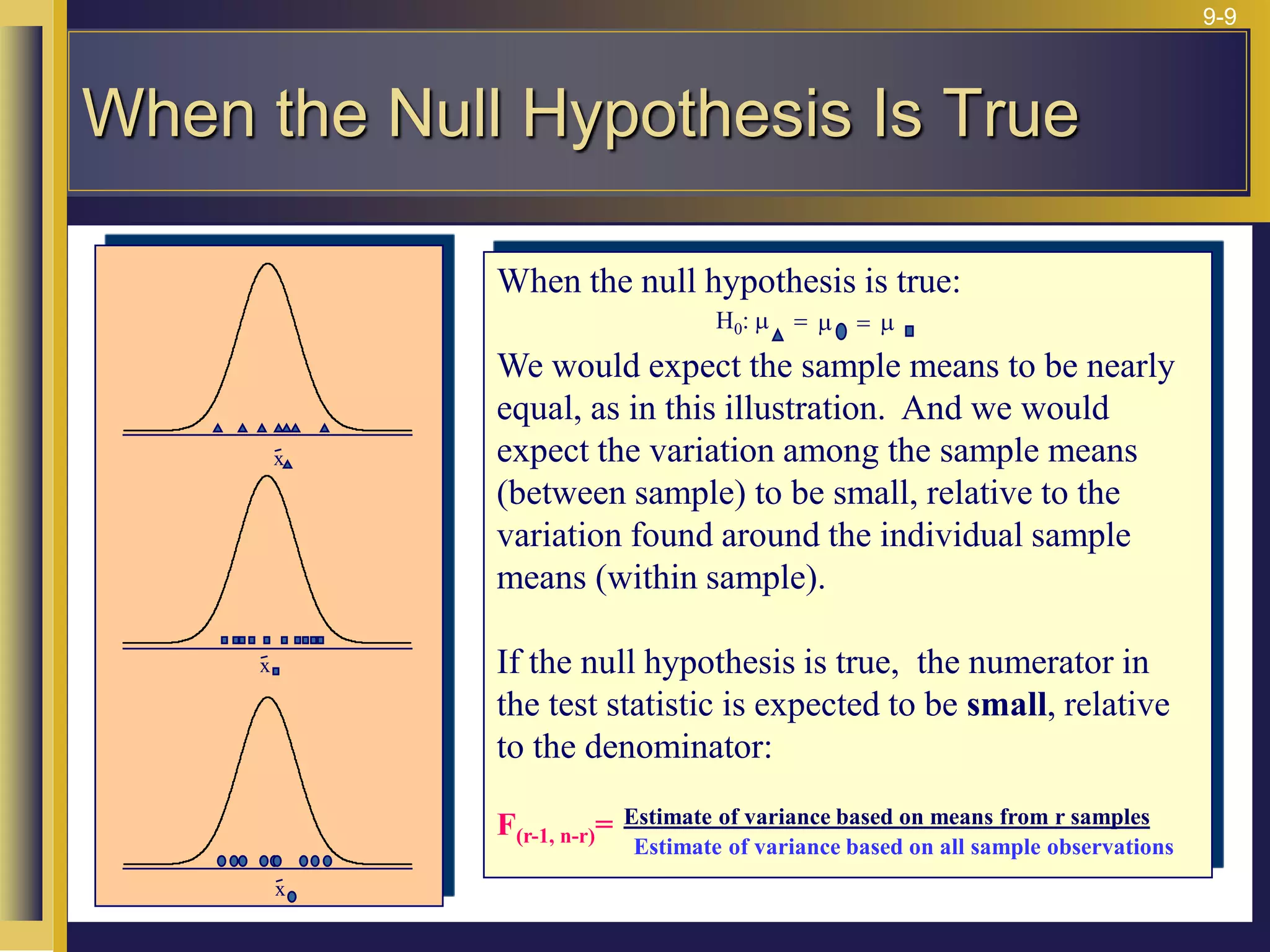
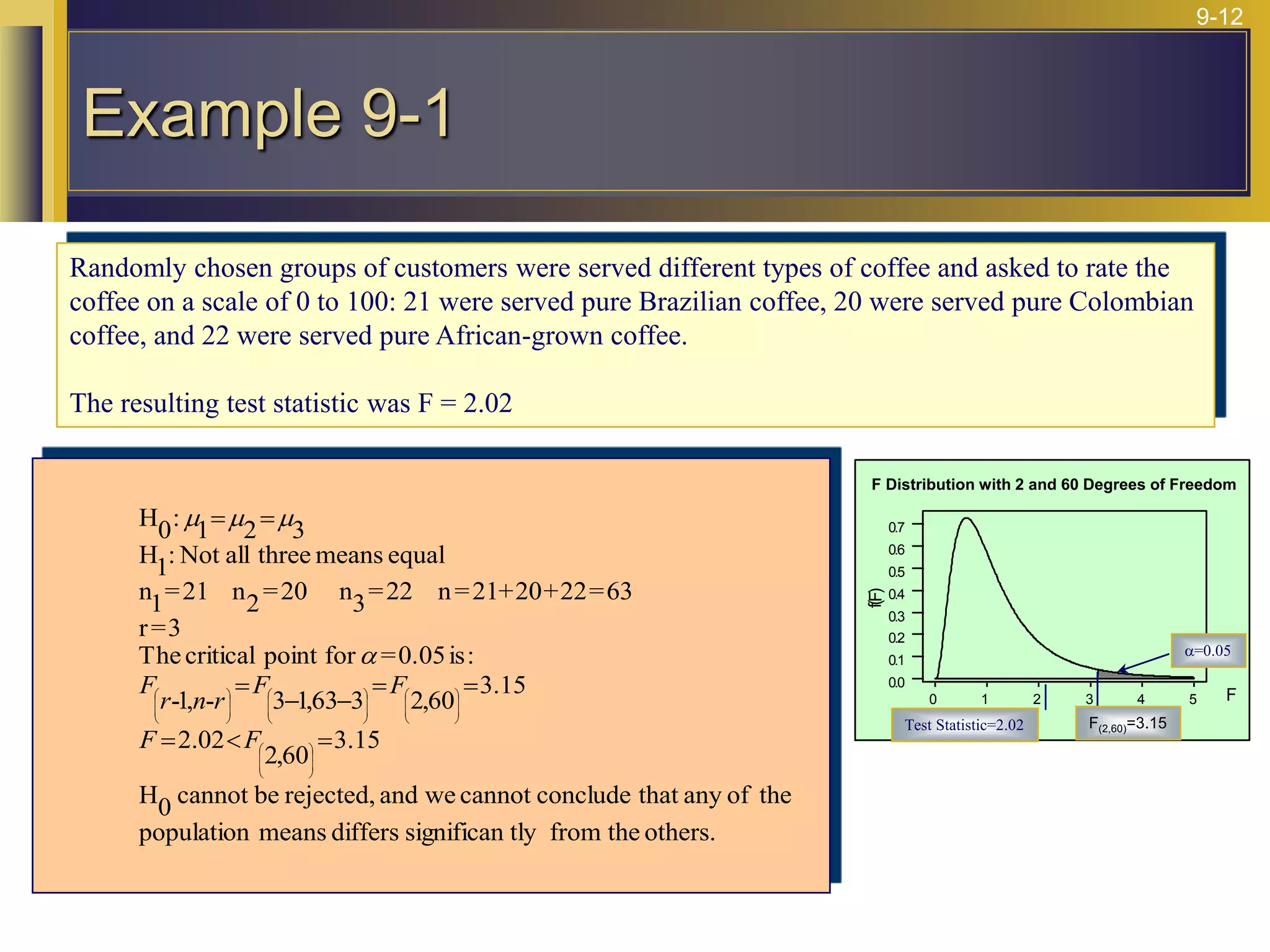
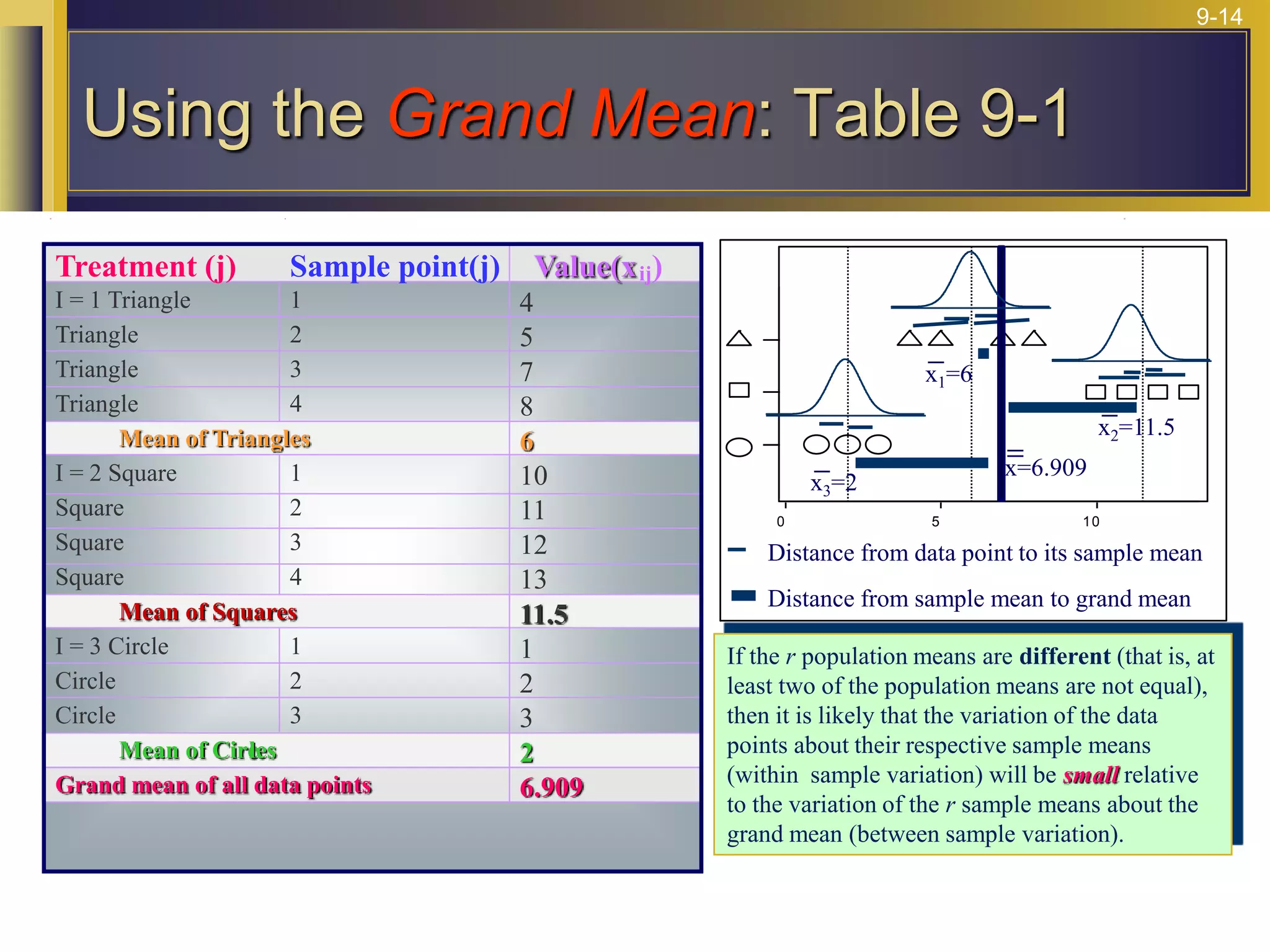
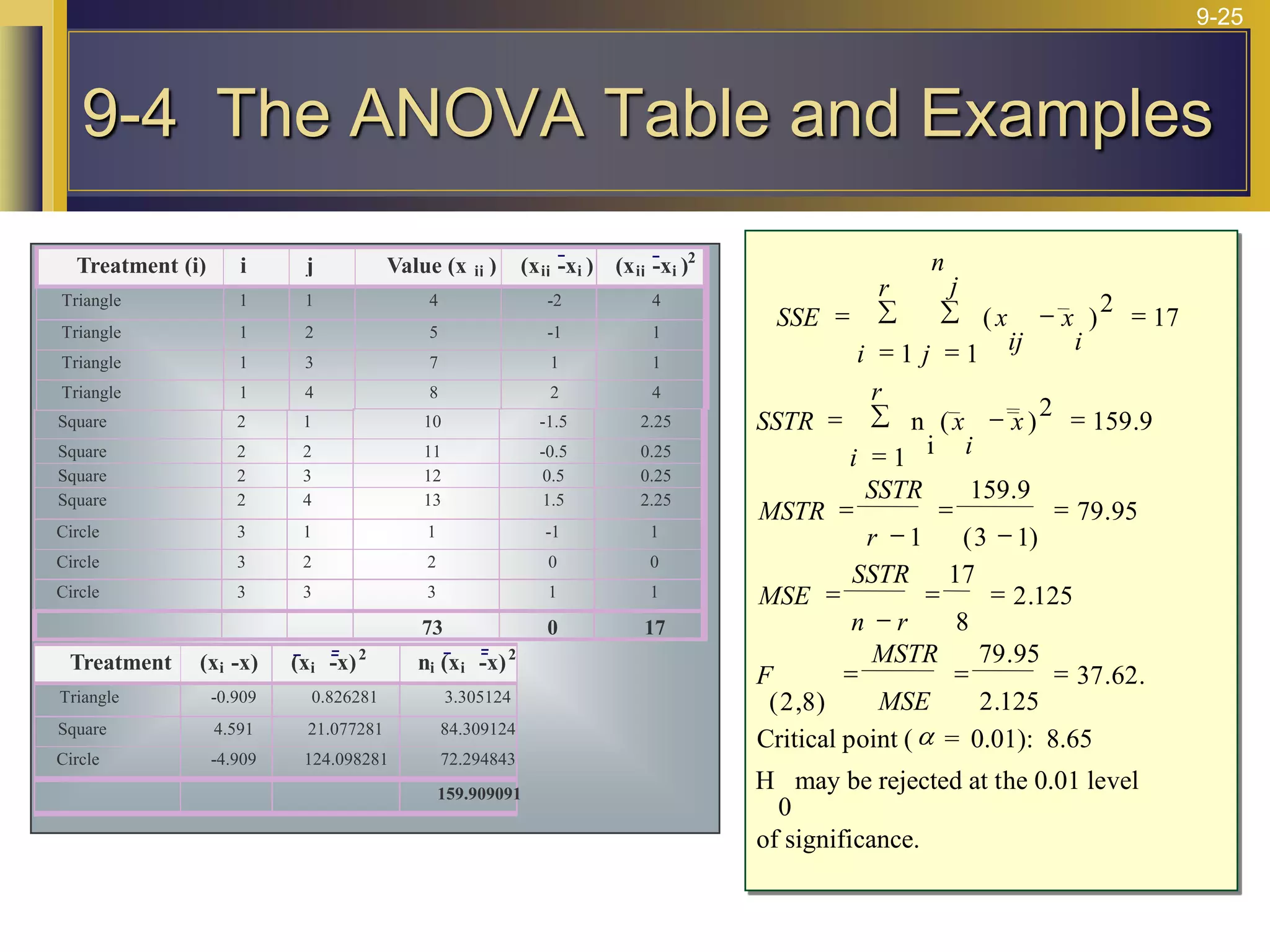
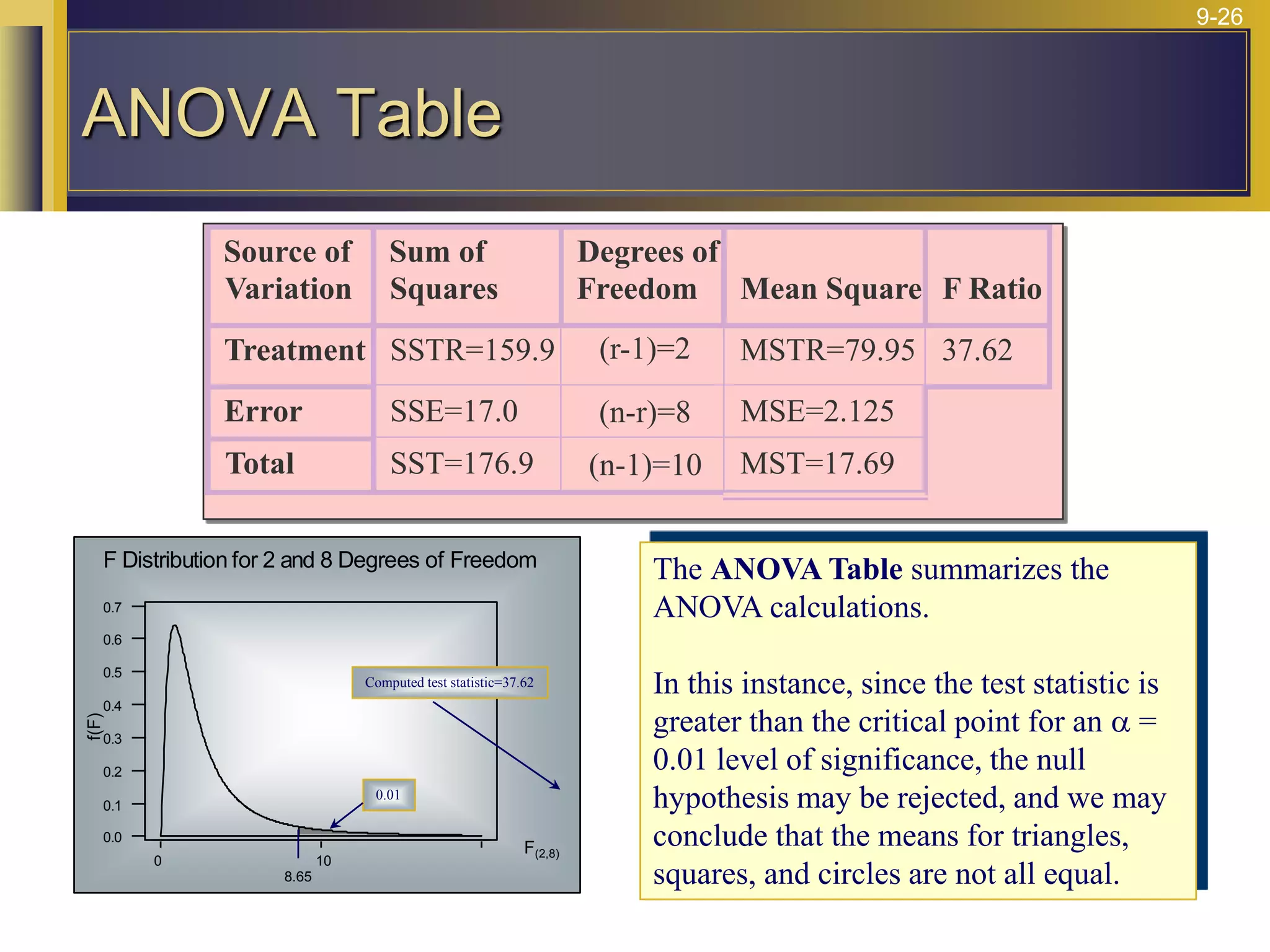
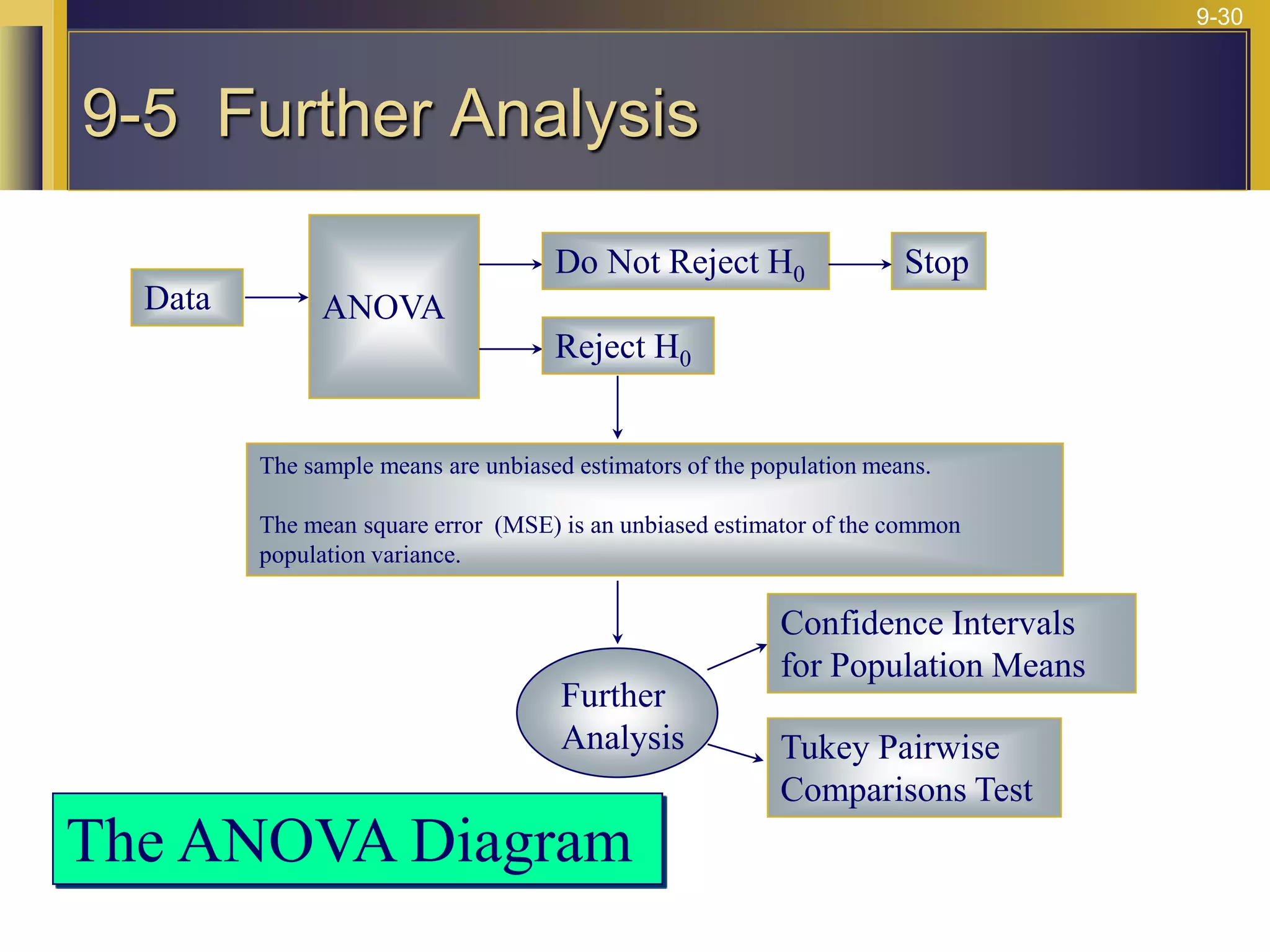
The document provides an overview of analysis of variance (ANOVA) including its purpose, assumptions, computations, and applications. It explains that ANOVA tests whether population means are equal by comparing two estimators of variance - the variation between sample means and the variation within samples. If the null hypothesis that all population means are equal is true, the between-sample variation will be small relative to the within-sample variation. The document outlines the computations and formulas behind ANOVA including definitions of terms like treatment deviations, error deviations, and sums of squares. It also describes how to interpret and report ANOVA results including the F-statistic and ANOVA table.























![9-31
A (1 - ) 100% confidence interval for , the mean of population i:
i
a m
a
a
where t is the value of the distribution with ) degrees of
freedom that cuts off a right - tailed area of
2
.
2
a
x t
MSE
n
i
i
2
t (n- r
x t
MSE
n
x x
i
i
i i
= =
=
=
=
=
=
a
2
1 96
504 39
40
6 96
89 6 96 82 04 95 96]
75 6 96 68 04 81 96]
73 6 96 66 04 79 96]
91 6 96 84 04 97 96]
85 6 96 78 04 91 96]
.
.
.
. [ . , .
. [ . , .
. [ . , .
. [ . , .
. [ . , .
Resort Mean Response (x i)
Guadeloupe 89
Martinique 75
Eleuthra 73
Paradise Island 91
St. Lucia 85
SST = 112564 SSE = 98356
ni = 40 n = (5)(40) = 200
MSE = 504.39
Confidence Intervals for Population
Means](https://image.slidesharecdn.com/10-220823103604-719d040d/75/10-Analysis-of-Variance-ppt-31-2048.jpg)