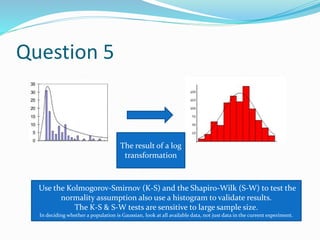
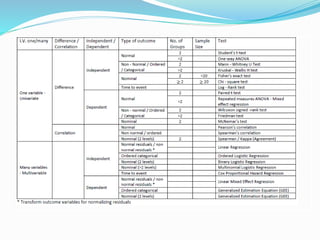
The document discusses sample size estimation and statistical test selection for data analysis in clinical trials. It emphasizes the importance of calculating sample size to achieve study objectives, avoid type I and II errors, and choose appropriate statistical tests based on study design and hypothesis. Various factors affecting sample size, such as effect size, allocation ratio, and the type of outcome, are detailed to guide researchers in their planning and reporting.

































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




