Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
okuraofvegetable
1,077 views
パタヘネゼミ 第6章
3S ゼミ コンピューターの構成と設計 第5版
Devices & Hardware
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 62
2
/ 62
3
/ 62
4
/ 62
5
/ 62
6
/ 62
Most read
7
/ 62
8
/ 62
9
/ 62
10
/ 62
11
/ 62
Most read
12
/ 62
13
/ 62
14
/ 62
15
/ 62
16
/ 62
17
/ 62
18
/ 62
19
/ 62
20
/ 62
21
/ 62
22
/ 62
23
/ 62
24
/ 62
25
/ 62
26
/ 62
27
/ 62
28
/ 62
29
/ 62
30
/ 62
31
/ 62
32
/ 62
33
/ 62
34
/ 62
35
/ 62
36
/ 62
37
/ 62
38
/ 62
39
/ 62
40
/ 62
41
/ 62
42
/ 62
43
/ 62
44
/ 62
45
/ 62
46
/ 62
47
/ 62
48
/ 62
49
/ 62
50
/ 62
51
/ 62
52
/ 62
53
/ 62
54
/ 62
55
/ 62
56
/ 62
57
/ 62
58
/ 62
59
/ 62
60
/ 62
61
/ 62
62
/ 62
More Related Content
PDF
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
できる!並列・並行プログラミング
by
Preferred Networks
PDF
Intro to SVE 富岳のA64FXを触ってみた
by
MITSUNARI Shigeo
PPTX
並列化による高速化
by
sakura-mike
PPTX
[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...
by
Deep Learning JP
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PPTX
[DL輪読会]Real-Time Semantic Stereo Matching
by
Deep Learning JP
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
できる!並列・並行プログラミング
by
Preferred Networks
Intro to SVE 富岳のA64FXを触ってみた
by
MITSUNARI Shigeo
並列化による高速化
by
sakura-mike
[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...
by
Deep Learning JP
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
[DL輪読会]Real-Time Semantic Stereo Matching
by
Deep Learning JP
What's hot
PDF
Stochastic Variational Inference
by
Kaede Hayashi
PPTX
C#メタプログラミング概略 in 2021
by
Atsushi Nakamura
PDF
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
PDF
Transformer 動向調査 in 画像認識(修正版)
by
Kazuki Maeno
PDF
【Unite Tokyo 2019】Understanding C# Struct All Things
by
UnityTechnologiesJapan002
PDF
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
PPTX
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
PPTX
Direct Sparse Odometryの解説
by
Masaya Kaneko
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
PDF
ソフト高速化の専門家が教える!AI・IoTエッジデバイスの選び方
by
Fixstars Corporation
PDF
.NET Core 3.0時代のメモリ管理
by
KageShiron
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
PDF
マーク付き点過程
by
Yoshiaki Sakakura
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PPTX
3次元計測とフィルタリング
by
Norishige Fukushima
PDF
実践QBVH
by
Shuichi Hayashi
PPTX
SSII2014 チュートリアル資料
by
Masayuki Tanaka
PDF
【学会発表】U-Net++とSE-Netを統合した画像セグメンテーションのための転移学習モデル【IBIS2020】
by
YutaSuzuki27
PPTX
G社のNMT論文を読んでみた
by
Toshiaki Nakazawa
PDF
[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series
by
Deep Learning JP
Stochastic Variational Inference
by
Kaede Hayashi
C#メタプログラミング概略 in 2021
by
Atsushi Nakamura
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
Transformer 動向調査 in 画像認識(修正版)
by
Kazuki Maeno
【Unite Tokyo 2019】Understanding C# Struct All Things
by
UnityTechnologiesJapan002
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
Direct Sparse Odometryの解説
by
Masaya Kaneko
明日使えないすごいビット演算
by
京大 マイコンクラブ
ソフト高速化の専門家が教える!AI・IoTエッジデバイスの選び方
by
Fixstars Corporation
.NET Core 3.0時代のメモリ管理
by
KageShiron
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
マーク付き点過程
by
Yoshiaki Sakakura
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
3次元計測とフィルタリング
by
Norishige Fukushima
実践QBVH
by
Shuichi Hayashi
SSII2014 チュートリアル資料
by
Masayuki Tanaka
【学会発表】U-Net++とSE-Netを統合した画像セグメンテーションのための転移学習モデル【IBIS2020】
by
YutaSuzuki27
G社のNMT論文を読んでみた
by
Toshiaki Nakazawa
[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series
by
Deep Learning JP
Similar to パタヘネゼミ 第6章
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
CUDAプログラミング入門
by
NVIDIA Japan
KEY
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
PPTX
GPU-FPGA協調プログラミングを実現するコンパイラの開発
by
Ryuuta Tsunashima
PDF
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針 (Flop/Byte,計算律速,メモリ律速)
by
智啓 出川
PDF
Hello, DirectCompute
by
dasyprocta
PDF
2015年度GPGPU実践プログラミング 第6回 パフォーマンス解析ツール
by
智啓 出川
PDF
CPUの同時実行機能
by
Shinichiro Niiyama
KEY
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
PDF
Cuda
by
Shumpei Hozumi
PDF
20130126 sc12-reading
by
Toshiya Komoda
PDF
CUDA1日(?)体験会 (再アップロード)
by
RinKuriyama
PDF
CUDA1日(?)体験会
by
RinKuriyama
PDF
2015年度先端GPGPUシミュレーション工学特論 第2回 GPUによる並列計算の概念と メモリアクセス
by
智啓 出川
PDF
kagami_comput2016_14
by
swkagami
PDF
2015年度GPGPU実践基礎工学 第8回 並列計算の概念 (プロセスとスレッド)
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
PDF
生物データベース論(並列分散計算フレームワーク)
by
Masahiro Kasahara
PDF
C base design methodology with s dx and xilinx ml
by
ssuser3a4b8c
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
CUDAプログラミング入門
by
NVIDIA Japan
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
GPU-FPGA協調プログラミングを実現するコンパイラの開発
by
Ryuuta Tsunashima
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針 (Flop/Byte,計算律速,メモリ律速)
by
智啓 出川
Hello, DirectCompute
by
dasyprocta
2015年度GPGPU実践プログラミング 第6回 パフォーマンス解析ツール
by
智啓 出川
CPUの同時実行機能
by
Shinichiro Niiyama
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
Cuda
by
Shumpei Hozumi
20130126 sc12-reading
by
Toshiya Komoda
CUDA1日(?)体験会 (再アップロード)
by
RinKuriyama
CUDA1日(?)体験会
by
RinKuriyama
2015年度先端GPGPUシミュレーション工学特論 第2回 GPUによる並列計算の概念と メモリアクセス
by
智啓 出川
kagami_comput2016_14
by
swkagami
2015年度GPGPU実践基礎工学 第8回 並列計算の概念 (プロセスとスレッド)
by
智啓 出川
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
生物データベース論(並列分散計算フレームワーク)
by
Masahiro Kasahara
C base design methodology with s dx and xilinx ml
by
ssuser3a4b8c
More from okuraofvegetable
PDF
直交領域探索
by
okuraofvegetable
PDF
Monadic second-order logic
by
okuraofvegetable
PDF
グレブナー基底
by
okuraofvegetable
PDF
パタヘネゼミ 第2回
by
okuraofvegetable
PDF
LT
by
okuraofvegetable
PDF
NPCA summer 2014
by
okuraofvegetable
PDF
Wrapping potato chips is fun
by
okuraofvegetable
ODP
Lecture2
by
okuraofvegetable
PDF
JOI summer seminar 2014
by
okuraofvegetable
直交領域探索
by
okuraofvegetable
Monadic second-order logic
by
okuraofvegetable
グレブナー基底
by
okuraofvegetable
パタヘネゼミ 第2回
by
okuraofvegetable
LT
by
okuraofvegetable
NPCA summer 2014
by
okuraofvegetable
Wrapping potato chips is fun
by
okuraofvegetable
Lecture2
by
okuraofvegetable
JOI summer seminar 2014
by
okuraofvegetable
パタヘネゼミ 第6章
1.
パタヘネゼミ 第6章 担当 :
奥村真司
2.
並列処理の復習(1~5章) • 2.11節 ▫ 協調動作,同期,排他処理(mutex) •
3.6 節 ▫ データレベル並列性 半語レベル並列性 • 4.10節 ▫ 命令レベル並列性 パイプライン化(潜在的),複数命令発行 • 5.10節 ▫ キャッシュ・コヒーレンス 複数プロセッサの共有資源の利用
3.
6.1 はじめに • コンピュータ設計上の見果てぬ夢 ▫
既存のコンピュータを多数接続して強力なコン ピュータを実現 スケーラビリティ • 強力? ▫ 独立したタスク群へのスループットの高さ タスクレベル並列性,プロセスレベル並列性
4.
6.1 はじめに • コンピュータの性能を決めるものたち ▫
クロック周波数 ▫ CPI • “今後の性能向上は明示的にハードウェアの並列 性を高めることでもたらされるだろう” ▫ マルチコア・マイクロプロセッサ コアの数はMooreの法則に従って増えると予想 ほとんどは共有記憶型マルチプロセッサ(6.5で)
5.
6.1 はじめに
6.
6.2 並列処理プログラム作成の困難さ • 並列処理における難しさ ▫
ハードウェア<ソフトウェア ▫ 同期、負荷の平準化などプログラマが考えるべき ことが多い • スケーラビリティ ▫ Amdahlの法則 効率は(改善前)/(影響を受けない範囲)以上にはなら ない ▫ プロセッサを100倍にして速度を90倍にしたい 逐次処理の部分は0.1%以下しか許容されない
7.
6.2 並列処理プログラム作成の困難さ • 強いスケーリング ▫
問題のサイズを固定して、プロセッサをn倍 n倍速出るか? • 弱いスケーリング ▫ 1プロセッサあたりの問題サイズを固定 時間が変わらないか? • 強いスケーリングのほうが難しいことが多い
8.
6.2 並列処理プログラム作成の困難さ • 負荷の平準化 ▫
どのプロセッサにも均等に仕事を割り振る さもなければ暇になるプロセッサが発生しリソース がもったいない • まとめ ▫ プログラマが考えること多い…
9.
6.3 ベクトル・アーキテクチャ • 並列ハードウェアの分類法 ▫
SISD(single instruction stream, single data stream) ▫ MIMD,SIMD,(MISD)
10.
6.3 ベクトル・アーキテクチャ • MIMD型コンピュータで別々のプログラムを協 調させながら動かせるが… •
通常はすべてのプロセッサで実行される単一の プログラムを作成 ▫ 条件分岐でプログラムの異なる部分を各プロセッ サで実行する ▫ この方式をSPMD(single program multiple data) という
11.
6.3 ベクトル・アーキテクチャ • MISD型コンピュータ ▫
ほとんどない • SIMD型コンピュータ ▫ データのベクトルを操作 ▫ 同期実行 ▫ スループット大 ▫ コードをコピーしなくてよい メッセージ交換型MIMD : コピー要 共有記憶型MIMD : 命令キャッシュ要
12.
6.3 ベクトル・アーキテクチャ • マルチメディア機能拡張 ▫
ベクトル拡張(AVX)やストリーミングSIMD拡張 (SSE)など ▫ 半語並列性の活用
13.
6.3 ベクトル・アーキテクチャ • ベクトル・アーキテクチャ ▫
SIMD,データレベル並列性に立脚 ▫ データをベクトル・レジスタに収集して処理 ▫ ベクトル演算,ベクトル×スカラーなどの演算がで きる ▫ パイプライン化された実行ユニットで逐次処理 アレイプロセッサとの違い • 対して従来のものをスカラ・アーキテクチャと 呼ぶ
14.
6.3 ベクトル・アーキテクチャ
15.
6.3 ベクトル vs
スカラ • ベクトルアーキテクチャでは1命令が大量の作業 を指定(ループ全体を指定することに相当) ▫ 命令数が少ない フェッチ・デコードに必要なバンド幅の大幅削減 • ベクトル演算はベクトル内の要素の計算が独立 していることがわかっている ▫ ハードウェアがデータハザードを検出する必要が ない
16.
6.3 ベクトル vs
スカラ • ベクトル命令間のデータハザードのチェック ▫ 各要素ごとにする必要はない チェック回数が少なくて済む • メモリから隣接するデータをまとめて取り出せ ばメモリ・レイテンシが少なくて済む • 1命令がループ全体を指定するためスカラ・アー キテクチャで起こるループの制御ハザードが起 こらない • 消費電力,エネルギーの面でも優れる
17.
6.3 ベクトル・アーキテクチャ • マルチメディア機能拡張的側面 ▫
複数の操作を指定 指定する作業の数はマルチメディア機能拡張より圧 倒的に多い ▫ データの幅を柔軟に扱える • マルチメディア機能拡張との違い ▫ 扱うデータが隣接している必要がない ストライドアクセス(隣接) インデックス修飾(ばらばら) のどちらもサポートされている
18.
6.3 ベクトル・アーキテクチャ • ベクトル命令は要素ごとに並列 ▫
パイプラインを複数並列にできる データレベル並列性の活用
19.
6.4 ハードウェア・マルチスレッディング • 単一プロセッサの性能改善法 ▫
リソースの有効活用法 • MIMDでは複数のスレッド,プロセスが複数のプ ロセッサ上で動作 • ハードウェア・マルチスレッディングでは複数 スレッドで単一プロセッサ内の機能ユニットを 共有させる ▫ スレッドごとにレジスタファイルやPCのコピー が必要
20.
6.4 ハードウェア・マルチスレッディング • 細粒度マルチスレッディング ▫
命令ごとにスレッドを切り替え ストールしているものは飛ばす クロック・サイクル単位での高速なスレッド切り替 えが必要 ▫ 利点 短時間,長時間のストールによるスループット損失を 隠すことができる ▫ 欠点 個別スレッドの完了が遅い(毎回切り替えるので)
21.
6.4 ハードウェア・マルチスレッディング • 粗粒度マルチスレッディング ▫
長時間のストール発生時のみスレッド切り替え 最終レベルキャッシュミス等 ▫ 利点 高速にスレッドを切り替えられる必要はない 細粒度マルチスレッディングと比較して個別スレッ ドの完了が早い ▫ 欠点 スループットの埋め合わせに限界 切り替え時にパイプラインのリフレッシュ、詰め直し が必要で、時間がかかる
22.
6.4 ハードウェア・マルチスレッディング • 同時マルチスレッディング ▫
複数命令発行,動的スケジューリング・パイプライ ン方式のプロセッサのリソースを活用する • マルチスレッドなしだと… ▫ 命令発行スロットの空きが存在 データレベル並列性の限界 • マルチスレッドを導入すると… ▫ スレッドレベル並列性とデータレベル並列性によ りリソースをフル活用できる!
23.
6.4 ハードウェア・マルチスレッディング • わかりやすい例
24.
6.5 共有記憶型マルチプロセッサ • 並列ハードウェア上でいい感じに実行できるソ フトウェアを容易に書けるようにしたい •
方式1 ▫ 全プロセッサ共有の単一物理アドレス空間を提供 データの”場所”を考慮する必要がなくなる 並列に実行されうることのみ気にすればよい 共有記憶の見え方に一貫性が必要 ハードウェアによるキャッシュ・コヒーレンスの維持
25.
6.5 共有記憶型マルチプロセッサ • 方式2 ▫
プロセッサごとに別のアドレス空間 データのやりとりは明示的に通信する必要がある • 詳しくは6.7節で
26.
6.5 共有記憶型マルチプロセッサ • 共有記憶型マルチプロセッサ
27.
6.5 共有記憶型マルチプロセッサ • 共有記憶型マルチプロセッサの種類 •
均等メモリアクセス(uniform memory access : UMA)型 ▫ メモリ中の語へのアクセス時間がプロセッサによ らない • 非均等メモリアクセス(NUMA)型 ▫ メモリに近いプロセッサほどアクセスが早い
28.
6.5 共有記憶型マルチプロセッサ • 単一アドレス空間でデータの共有ができる ▫
同期の必要性 lock等を用いる • OpenMP ▫ 共有記憶型マルチプロセシングのためのAPI ▫ ループの並列化 均等にプロセッサに割り振る ▫ 簡約 複数プロセッサでの結果を統合 ▫ などがサポートされている
29.
6.6 GPUの概要 • GPU(Graphics
Processing Unit) ▫ グラフィックス処理改善のために登場 コンピュータ・ゲーム産業の影響 ▫ マイクロプロセッサの汎用処理よりも速いペース で性能が上がった
30.
6.6 GPUの概要 • GPUとCPUの特性の違い ▫
GPUはCPUを補完するアクセラレータ CPUができること全てをできる必要はない • GPUとCPUのアーキテクチャの違い ▫ CPUはメモリのレイテンシを下げるために階層的 キャッシュを用いるが,GPUは利用しない ハードウェア・マルチスレッディングによってメモ リのレイテンシを隠す GPUのメモリはデータ幅,バンド幅重視
31.
6.6 GPUの概要 • 汎用の計算を行うにはCPUメモリとGPUメモリ 間でデータ転送が必要 •
GPUは高度にマルチスレッド化されたプロセッ サがたくさん入っている
32.
6.6 GPUの概要 • GPUはもともと狭い分野用に開発 ▫
Cとかでプログラムがかけない ▫ つらい • NVIDIAのCUDA ▫ Compute Unified Device Architecture ▫ 制限はあるもののGPU上で動作するCプログラム を書くことができる • CUDAスレッド ▫ 最下位レベルのプログラミング・プリミティブ ▫ POSIXスレッドとは全くの別物なので注意
33.
6.6 NVIDIA GPUアーキテクチャ •
GPUはマルチスレッド方式のSIMDプロセッサで 構成されるMIMD ▫ ベクトル・プロセッサより並列ユニット数が多い
34.
6.6 NVIDIA GPUアーキテクチャ •
SIMDスレッド ▫ SIMD命令のみのスレッド ▫ 独自のPCを保持 • SIMDスレッド・スケジューラ ▫ SIMDプロセッサ内 ▫ 実行すべきSIMDスレッドをスケジュール コントローラで実行準備のできたスレッドを選び、 ディスパッチユニットに送る
35.
6.6 NVIDIA GPUアーキテクチャ •
スレッド・ブロック・スケジューラ ▫ スレッドブロックをSIMDプロセッサに割り当て る • SIMD命令の幅は32 ▫ 各スレッドは32要素の計算をする • SIMDプロセッサ内には並列機能ユニット(6.3節) ▫ SIMDレーン
36.
6.6 NVIDIA GPUメモリの構造 •
ローカル・メモリ ▫ マルチスレッド方式SIMDプロセッサ内 ▫ SIMDレーン間で共有 SIMDプロセッサ間では共有されない • GPUメモリ ▫ チップ外のDRAM ▫ GPU全体及び全てのスレッドブロックで共有
37.
6.6 NVIDIA GPUメモリの構造
38.
6.6 NVIDIA GPUメモリの構造 •
GPUでの処理はワーキングセットが大きい ▫ マルチコア・マイクロプロセッサの最下位レベル のキャッシュに収まりきらない • マルチスレッディングでDRAMのレイテンシを 隠す ▫ 小規模なストリーミングキャッシュのみ 最新のGPUは追加のキャッシュを備えているらしい …?
39.
6.6 GPUまとめ • マルチスレッド方式のSIMDプロセッサ複数で構 成される •
SIMDプロセッサ内には並列機能ユニットSIMD レーンが複数ある ▫ 6.3節と似ている • SIMDプロセッサではハードウェア・マルチス レッディングでDRAMのレイテンシを隠す • 最小単位CUDAスレッド ▫ そのまとまりがスレッドブロック
40.
6.7 メッセージ交換型マルチプロセッサ • 共有記憶型と異なり、各プロセッサが固有の物 理アドレス空間を持つマルチプロセッサ
41.
6.7 メッセージ交換型マルチプロセッサ • 明示的なメッセージ交換(message
passing)を 行う必要がある ▫ メッセージ送/受信ルーチン • 高性能なメッセージ交換ネットワークをベース に大規模なコンピュータの開発 ▫ スパコンなど 特製のネットワークを使用 ▫ ネットワークのコストが非常に高い 高性能コンピューティングの分野以外では厳しい
42.
6.7 クラスタ • クラスタ ▫
普通のネットワークで結合されたコンピュータの 集合体で単一のメッセージ交換型マルチプロセッ サとして機能するもの 通常のネットワークなので低コスト ▫ 各々のコンピュータをノードという
43.
6.7 クラスタ • 各ノードでは別個のOSのコピーが稼働 •
主記憶が分散している ▫ システムの信頼性の面では嬉しい • 障害発生時にシステムを停止させずにノードを 取り替えることができる ▫ 信頼性が高い ▫ 共有記憶型だと難しい • 逆にクラスタ上のアプリケーションを停止させ ずにシステムを拡張することも容易に可能
44.
6.7 クラスタ • 大規模共有記憶型マルチプロセッサと比較して 通信性能は劣る •
低コスト、高可用性、拡張のしやすさ ▫ Google等検索エンジンで利用 何万台ものサーバーで構成されるクラスタからなる データセンターが世界各地に
45.
6.7 ウエアハウス・スケール・コンピュータ • 何万台ものコンピュータからなるクラスタを収 容し給電、冷却、さらに運用するのは非常に難 しい •
大規模クラスタのサーバー群をウエアハウス・ スケール・コンピュータ(WSC)と呼ぶ
46.
6.7 ウエアハウス・スケール・コンピュータ • WSCで処理をするためのフレームワーク ▫
MapReduce ▫ 初心者でも30分程度で何千台ものサーバー上での タスク処理が書ける ▫ すごい
47.
6.8 ネットワーク・トポロジ • すでに見たとおりネットワークの性能は重要 •
ネットワークはグラフ ▫ 枝はリンク ▫ 頂点はスイッチもしくはプロセッサ • トポロジ ▫ グラフの形、繋がり方 • 例 : リング
48.
6.8 ネットワーク・トポロジ • ネットワークバンド幅 ▫
トポロジの性能評価の尺度 • 総合的ネットワークバンド幅 ▫ 各リンクのバンド幅×リンクの数 ▫ ピーク時、最も効率よくネットワークが使われるとき の伝達量 • 2分割バンド幅 ▫ 頂点を2グループに分割し、グループをまたぐリンク のバンド幅の和 2分割の仕方は最悪の場合を取る 一方のグループの各点からもう一方の各点に送信したい ときの伝達量に対応
49.
6.8 ネットワーク・トポロジ • 全結合ネットワーク ▫
完全グラフ ▫ ネットワークの性能は高いがコストも高い • 実際に商用の並列プロセッサに使用されている トポロジ
50.
6.8 ネットワーク・トポロジ • マルチステージ・ネットワーク ▫
間にスイッチだけのノードを配置 ▫ スイッチは小さいので高密度に集積できる ノードの間隔を狭くできる
51.
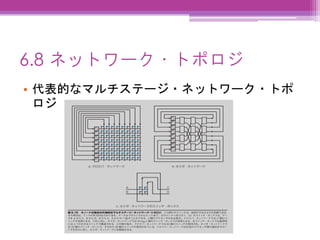
6.8 ネットワーク・トポロジ • 代表的なマルチステージ・ネットワーク・トポ ロジ
52.
6.10 マルチプロセッサのベンチマーク • ベンチマーキング・システムには注意が必要 ▫
意味のある指標か? アルゴリズムやデータ構造の力で勝っても仕方ない • マルチプロセッサのベンチマーク ▫ 色々ある Linpack(線形代数ルーチン集合体) Yahoo! Cloud Serving Benchmark(YCSB) クラウドデータサービスの性能比較
53.
6.10 マルチプロセッサのベンチマーク • 性能モデル ▫
算術強度(arithmetic intensity) 浮動小数点演算の回数をアクセスされたメモリのバ イト数で割ったもの ▫ 性能は何に縛られるか? ハードウェアの計算能力の限界 記憶システムの限界
54.
6.10 ルーフラインモデル • ルーフライン・モデル ▫
横軸を算術強度(FLOP/byte) ▫ 縦軸を1秒間の演算回数(GFLOP/sec) ▫ としたグラフ 屋根のようになる
55.
6.10 ルーフラインモデル • ルーフラインの屈折点 ▫
屈折点のx座標が小さいほど、様々なプログラム が性能を最大限引き出せる
56.
6.10 ルーフラインモデル • 例
: 2世代のOpteronの比較
57.
6.10 ルーフラインモデル • あるプログラムで性能が上限より低い… ▫
どのような最適化をすればよいかの判断にルーフ ラインが役立つ • 有効な最適化 ▫ 演算能力がボトルネックのとき 浮動小数点演算ミックス 乗算と加算をセットにするほうがよい 命令レベル並列性の改善とSIMDの適用 ループアンローリングなど
58.
6.10 ルーフラインモデル • 有効な最適化 ▫
メモリがボトルネックのとき ソフトウェア・プリフェッチ データが必要になるまで待たずに予測に基づいてアクセス メモリ近接化 メモリの同じ位置を参照する命令はなるべく同じプロセッ サで処理 • 算術強度は一般には固定ではない ▫ 問題サイズによって算術強度が変わる場合、最適化が 難しい 強いスケーリングが弱いスケーリングより難しい!
59.
6.10 ルーフラインモデル
60.
6.11実例 • Intel Core
i7 960とNVIDIA Telsa GPUのベンチ マークテスト結果の比較 • 結果をルーフラインモデルを用いて分析してい る • 詳しくは読んでみてください
61.
6.12 行列乗算の高速化 • 行列乗算のコードをOpenMPを用いて複数プロ セッサ上で動くように変更 ▫
1行足すだけ • 16コアの上で動かしてみる ▫ 14倍 ▫ すごい
62.
6.13 誤信と落とし穴 • 誤信 ▫
Amdahlの法則は並列コンピュータには適用できない できるので ▫ ピーク性能は現実の性能を反映する ピーク性能を出すのは難しい ましてや複数プロセッサならなおさら • 落とし穴 ▫ マイクロプロセッサ・アーキテクチャに最適化したソ フトウェアを開発しないこと 複数プロセッサ用のソフトウェアの開発は難しい ユニプロセッサ用のものを移植する際など注意
Download


































































![[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Real-Time Semantic Stereo Matching](https://cdn.slidesharecdn.com/ss_thumbnails/real-timesemanticstereomatching-sugisakihiroaki-191213003224-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series](https://cdn.slidesharecdn.com/ss_thumbnails/190118nonakadlhacks-190118005053-thumbnail.jpg?width=640&height=640&fit=bounds)




























