More Related Content

PDF
大規模ソーシャルゲーム開発から学んだPHP&MySQL実践テクニック 
PPTX

PDF

PDF

PDF
200,000 Req/sec をさばく広告入札システムを支えるパフォーマンスチューニング術 #jjug_ccc #ccc_g6 
PDF
サーバー未経験者がソーシャルゲームを通して知ったサーバーの事 
PDF

PDF
What's hot

PDF

PDF

PPTX

PDF
Python 3.9からの新定番zoneinfoを使いこなそう 
PDF

PPTX

PDF
Bitbucketを活用したコードレビュー改善事例 
PDF

PDF
アプリ屋もDockerをドカドカ使おう ~ Docker入門 
PPTX

PPTX
コンテナ基盤であるLXC/LXDを 本番環境で運用する話 
PPTX

PDF

ODP

PDF
AlmaLinux と Rocky Linux の誕生経緯&比較 
PDF

PDF

PPTX

PDF

PDF
強いて言えば「集約どう実装するのかな、を考える」な話 Viewers also liked

PDF

PPTX

PDF

PDF

PPTX
AtCoder Regular Contest 016 解説 
PDF
H231126 統計および確率を利用した予測と判断rev1 
PDF

PPTX

PDF
カップルが一緒にお風呂に入る割合をベイズ推定してみた 
PDF
2015年度先端GPGPUシミュレーション工学特論 第15回 CPUとGPUの協調 
PPTX

PDF

PPTX
仕事の流儀 Vol1 基本編_ver1.1_外部公開ver 
PDF

PDF

PDF

PDF

PDF

PDF
10年効く分散ファイルシステム技術 GlusterFS & Red Hat Storage 
PPTX
Similar to EthernetやCPUなどの話

PDF

PDF
Open-FCoE_osc2011tokyofall_20111119 
PDF

PDF

PDF

PDF

PDF
L2 over L3 ecnaspsulations 
PDF

PDF

PDF

PDF
動的ネットワークパス構築と連携したエッジオーバレイ帯域制御 
PPTX
JAWS-UG HPC #17 - HPC on AWS @ 2019 
PDF

PDF

KEY
20120519 #qpstudy インターフェース入門 
PDF

PDF

PDF

PDF
ITpro EXPO 2014: Cisco UCSによる最新VDIソリューションのご紹介 
PDF
巨大ポータルを支えるプライベート・クラウド構築事例から学べ!~攻める情シスのためのインフラ構築、その極意とは?~ More from Takanori Sejima

PDF
NAND Flash から InnoDB にかけての話(仮) 
PDF

PDF

PDF

PDF
さいきんの InnoDB Adaptive Flushing (仮) 
PDF

PDF

PDF
binary log と 2PC と Group Commit 
PDF
MySQL5.7 GA の Multi-threaded slave 
PDF

PDF

PDF

PDF

PDF
EthernetやCPUなどの話
- 1.
- 2.
- 3.
自己紹介
- そこそこ MySQLでご飯食べてます
- いまの会社に入る前は、MMORPGのDB設計
などもしてまして
- 一時期は Resource Monitoring や KVS にも
力入れてました
- Linuxとハードウェアは嗜む程度
- disk I/O にはむかしから興味あります
- 4.
さて今回は
- Linux を前提に
-サーバサイドエンジニアの観点から、 Ethernet
などのサーバの I/O に関する状況を見渡して
- これから先のことを考えてみることにします
- マサカリ歓迎します
- 5.
先ず参考書籍
- 最近、今年の6月に和訳された 詳説イーサネッ
ト 第2版 を読んだんですが
- すべてのインフラエンジニアやサーバサイドエン
ジニアが、この書籍を読む必要性があるかとい
うと、微妙
- MMORPGみたいに、ネットワークの要件が厳し
いコンテンツ作る人は、読んでいいかも
- 6.
先ず振り返ってみましょう
- Ethernet はどれくらい進化してきたのか?
- 100Base-TX は 90年代、 GbE が普及してきた
のは 21世紀に入ってきてからかな?
- 2010年代、現代においては、 サーバでは
10GbE がだいぶ普及してきたという実感がある
- 十年周期くらいの進歩と捉えたら、2020年代に
は、やっぱ次の規格が普及するんじゃん?
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
今後は
- 100GbE まではすでに製品がある
-流石に100GbEはツイストペアケーブルやらないらしい
- 400GbE は2017年に仕様決まるらしい
- 40GbE はいまのところ光ファイバーのみだけ
ど、 40GBASE-T を実現するための Category
8 Cable がいま作成中とのこと
- (月並みだけど)Category 8 が来るころには、
40GbE の普及率上がってくるんじゃない?
- 13.
40GBASE-Tが普及するのって
- 10GBASE-T のときは、2006 年に標準化完了
して、2009年にはアキバに出回り始めた
- 実際にデータセンターで普及し始めたのは、
2010年に入ってからとしても
- 40GBASE-Tが2016年くらいに標準化完了し
て、もし同じペースで普及するとしたら、2020年
あたりから出回り始めるんじゃないかなぁ
- 14.
- 15.
と、いうわけで
- いま10GbE で動いてるところが、2020年代に
は4倍以上帯域が太くなってる可能性がありま
す。いま GbE なら40倍以上です
- 40GbEはすでにある技術ですが、例によって、
Web業界のサーバには、他所である程度普及
した後、お下がりのようにやってくると思います
- 40GBASE-T がWeb業界に来るのに備えて、
それを活かす準備をしたいものです
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
RSS意識するときは注意しよう
- I350のデータシート P.45の表を見てみると、
I350 はRSSのキューが 8 つまで、 82599 は
16 まで。つまり、NICがサポートしてるキューの
数までしか、CPUのCore分散できない。
- また、 最近のXeonは選択肢が数多くあるの
で、 Xeon E5-2637 v3 のようにクロック高いけ
ど Core が少ないCPUでは、16個もキューが
あっても使い切れない
- 22.
- 23.
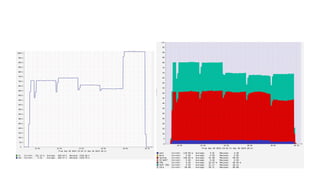
では、 10GbE でどれくらいCPU使うのか
-むかし同僚に教えてもらった uperf と
- 次の組み合わせで試しました
- Xeon E5-2630 v3
- 10GbE(Intel 82599)
- 保守的にMTU1500で
- Ubuntu 14.04.3 LTS
- kernel 3.13 x86_64
- glibc 2.19
- gcc 4.8.4
- 24.
めも
- uperf 1.0.4をビルドするのにここだけいじりまし
た
- https://gist.github.
com/sejima/c5207d539969c56ca6d0
- あとは
- $ ./configure --disable-sctp --enable-cpc
- 25.
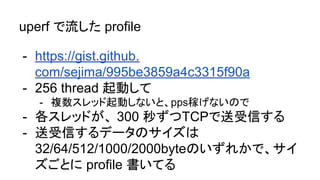
uperf で流した profile
-https://gist.github.
com/sejima/995be3859a4c3315f90a
- 256 thread 起動して
- 複数スレッド起動しないと、pps稼げないので
- 各スレッドが、 300 秒ずつTCPで送受信する
- 送受信するデータのサイズは
32/64/512/1000/2000byteのいずれかで、サイ
ズごとに profile 書いてる
- 26.
CPU Scaling Governorなど
- scaling_governor は performance と
ondemand で比較します
- あと、 kernel の boot parameter でintel_idle.
max_cstate=1
- 27.
- 29.
- 31.
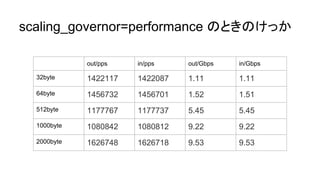
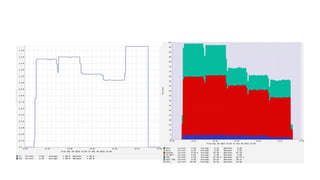
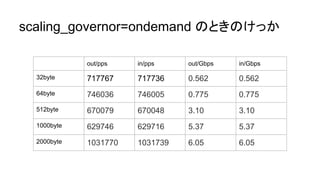
さいきんは TurboBoostも重要
- clock次第で NIC の性能引き出せないことも
- scaling_governor=performance にして 2.6GHz まで
引き上げた状態だと、 9.5Gbps までスループット出せて
る。ほぼワイヤースピード
- しかし、ondemand だと 6 Gbps 程度しか出なかったり
する
- このへんはワークロードに依存するところもあるだろうけ
ど、NIC酷使したいなら TurboBoost 意識する方が無難
- 32.
まず TurboBoost の用途として
-アプリケーションサーバなどCPUバウンドなもの
でも TurboBoost 有効ですけど、それ以外では
- 現時点では、ネットワークの性能改善に使うの
がよさそう
- RSS用にキューたくさんあるNICなら、どうせた
くさんCore使うんだから、ぜんぶのCoreの
clock を引き上げてしまえばいい
- 33.
ただ、気をつけてください
- Brendan Greggのスライド を見ると、彼は
rdmsr で温度もとってますよね?
- そうです、いまの TurboBoost は、温度次第な
んです
- CPUに温度センサーついてて、 TCase の範囲
内で clock 上げるのが、現在の TurboBoost
2.0 なんです
- 34.
なので TurboBoost 酷使したい人は
-CPU の温度もモニタリングするのがオススメ
- できれば常時観測しましょう
- scaling_governor=performance にすると、
clock は上がりますが、C1 state (Halt)に入る
と、温度下がります
- C0 のときにだけ温度上がる == Core ぶん回っ
てるときだけ温度上がるので、ちゃんと排熱でき
てるか観測するのがよいです
- 35.
閑話休題・1
- Ubuntu はデフォルトで/etc/init.d/ondemand
が起動時に実行されるそうな
- ネットワークの性能が大事なら、無効化しましょ
う
- 参考: http://askubuntu.com/questions/3924/disable-
ondemand-cpu-scaling-daemon
- 36.
閑話休題・2
- Skylake ではSpeedShift っていう新しい省電
力機構が来るのですが
- CPU側で自動制御するとか、OS側といろいろ
協調するとか、今までと比べてクロック/電圧制
御が拡張されてるようなので
- Xeon に SpeedShift が来たときに備えて、OS
側でクロックなど制御するのに、慣れといたほう
がいいかなと思ってます
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
ブロックデバイスの進化はめざましい
- Fusion-IO がioDrive をリリースしてから「CPU
がボトルネックになった」と言われましたが
- 3D NAND が実用化されたので、 NAND flash
のバイト単価はこれからも下がり続けます
- PCI-e SSD はシーケンシャルリードが数
GB/secの時代に突入し、 3D Xpoint があれ
ば、 NVMe のインターフェースのままで、
NAND Flash の 7 倍の性能が出るように
- 48.
- 49.
- 50.
個人的な見解としては
- 40GbE になったら、Jumbo Frame 標準化され
てないけど、使わないと活かせないかも
- 何が遅いってDRAMが遅いから、サーバはそん
なにたくさんのフレームを捌けない
- 40GbEの時代になってもオンプレミス環境を持
つならば、そのへんを意識した方がいいかも
- 一方、AWSはすでにMTU9001の世界に行って
いる
- 51.
- 52.
- 53.
- 54.
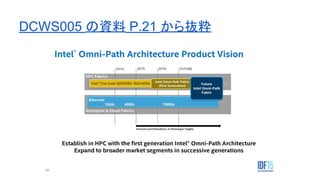
Omni-Path?
- こちらの記事 などを参考に
-2014-2015年あたりからデータセンターに
40GbE が導入されるという予測はさておき
- Omni-Path で、最初はHPC向けのインターコネ
クトを InfiniBand から置き換えて、最終的に
Ethernet も一部置き換えたいみたい
- 10GBASE-T がしんどかったんですかねぇ
- 55.
- 56.
40Gbps までは Ethernetだとしても
- 私見ですが、そこから先は、別のものでも良い
んじゃないでしょうか?
- 少なくとも、データセンター内は
- ブロックデバイスでHDDの代わりが見つかった
ように
- 少なくとも、ツイストペアケーブルだとエラーレー
ト高くて効率悪いし、FCSが4byteだから、あまり
大きなフレームは扱いにくい
- 57.
2020年あたりを想定すると
- NAND Flashの次として、 (インターフェースが
NVMeでも)7倍以上速い3D Xpoint が実用化
できそう
- 10GBASE-Tの次として、4倍以上の帯域をもつ
40GBASE-Tか何かが実用化できそう
- では、CPUやDRAMは4倍以上の進化をとげる
ことができるのか?
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
いまでこそEC2で10Gbps普通だけど
- かつて 10Gbpsのインスタンスは HPC向け
だった
- いまでこそ普及して、 ここで挙げられてるような
HPC以外の用途 でも活用されてるだろうけど
- 40Gbps 以上のインターフェースが付けば、
EC2でHPCやる人が増えて、結果として、そう
いうインスタンスが当たり前になるかもしれない
- 64.
- 65.
- 66.
- 67.