以前アップロードした "CUDA 1日(?)体験会 https://www2.slideshare.net/RinKuriyama/cuda1" の日本語が抜け落ちていたため、修正して再アップロードしました。 所属研究室で主催したCUDAによるGPUを用いたプログラミングチュートリアル資料。「並列計算とは」に始まり、「GPU、CUDAの構造の関係」、「ベクトル計算の並列化」、そして「神経回路計算におけるCUDAプログラミング基礎」まで。








![10
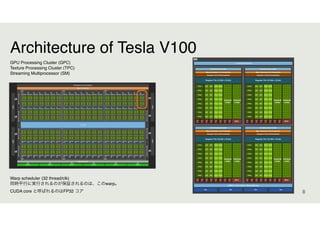
CUDAとは
GPGPUにNVIDIA GPUを活用するための
並列計算プラットフォームかつプログラミングモデル
C, C++ 文法で書ける (CUDA Fortran もあるらしい)
__global__ void vec_add( float *a, float *b, float *c, int n ){
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) c[i] = a[i] + b[i];
}
…
int main(){
…
vec_add<<< numBlocks, ThreadsPerBlock >>>( d_a, d_b, d_c, N);
…
}
ベクトルの足し算の例: c = a + b](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-10-320.jpg)
![11
ちょっとプログラム解説
__xxx__ : 関数識別子
__global__
ホストから呼び出されるカーネル
1スレッドが実行する操作を定義
__host__
ホスト側の関数(普通のやつ)
__device__
カーネル内から呼ばれるデバイス関数
__global__ void vec_add( float *a, float *b, float *c, int n ){
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) c[i] = a[i] + b[i];
}
…
int main(){
…
vec_add<<< numBlocks, ThreadsPerBlock >>>( d_a, d_b, d_c, N);
…
}](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-11-320.jpg)
![12
Block 0 Block 1 Block 2
Block 3 Block 4 ……
Thread Block Grid
<<< numBlocks, ThreadsPerBlock >>>
カーネルで1スレッドの動作を定義
呼び出し時に
"ブロック数" : numBlocks
"1ブロックあたりのスレッド数" : ThreadsPerBlock
を決めて呼び出す*
*実際はdim3という型で3次元に分割されるが、ここでは扱わない。
__global__ void vec_add( float *a, float *b, float *c, int n ){
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) c[i] = a[i] + b[i];
}
…
int main(){
…
vec_add<<< numBlocks, ThreadsPerBlock >>>( d_a, d_b, d_c, N);
…
}
Hierarchy of CUDA](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-12-320.jpg)






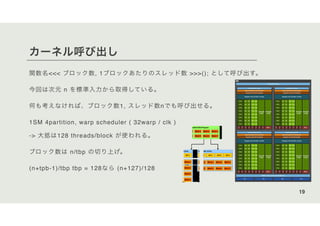









![ベクトル計算 (内積) の逐次実装
次は内積
基本は加算と同様。
i要素同士を掛けてから全て足す。
(今回はc[0]のゼロ初期化をサボるので、c[0]の値は内積*trialになる)
c0 =
n−1
∑
i=0
aibi
29
a0
a1
:
an-2
an-1
b0
b1
:
bn-2
bn-1
c0・ =](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-29-320.jpg)
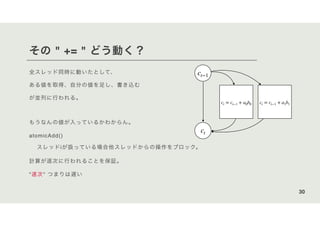


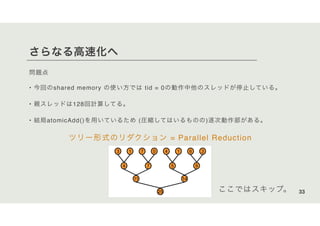




![まずはGPU側にデータをコピーする
• Neuron d_neurons[],
• connectivity d_connections[]
• cudaMalloc
• cudaMemcpy
38](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-38-320.jpg)

![二重ポインタ(& 構造体)の罠
このままではupdate関数でエラーが発生する。
update内部の g[ch][i] が原因。
d_neuron->g[ch] はGPU側のアドレスを指している。
d_neuron->g はCPU側のアドレスを指している。
つまり、d->g[ch] というCPU側のデータにアクセスしたときにセグフォが起きる。
40](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-40-320.jpg)
![解決策
• update関数の引数を増やす。
• g, dg のデータ構造を変更する
• g[ch][i] から g[ch*n + i] へ。
• 引数は一つで済む。今後チャネルが増えても対応可
• syn_propagation には &(g[ch*n]) と渡せば良い。
(個人的に見た目がいいのは後者。ただ時間の関係上今回は前者で対処。)
41](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-41-320.jpg)


![グローバルメモリへのアクセス回数を減らす
syn_propagation カーネル内部
dg[i] に毎回アクセスしているのは無駄。最後に一度更新すればよい。
カーネル内で "T tmp"を宣言。ループ文の中の dg[i] を tmp に置き換え。
ループ後にdg[i] += tmp; とする
44](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-44-320.jpg)


![ボトルネックを探す: nvprof
% nvprof [options] ./<prog> [args]
で実行することでお手軽に関数ごとの全体に占める割合等を確認できる。
細かい結果をファイル出力すれば、NVIDIA Visual Profiler (nvvp) で結果を可視化、分析
できる。
syn_propagation がボトルネック <= 無駄な計算が多い
47](https://image.slidesharecdn.com/cudaonedayadobe-201117041304/85/CUDA1-47-320.jpg)
















![[DL輪読会] Hybrid computing using a neural network with dynamic external memory](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawadnc-161220014044-thumbnail.jpg?width=640&height=640&fit=bounds)




































