Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Toshiya Komoda
PPTX, PDF
427 views
2012 1203-researchers-cafe
Presented in the researchers cafe @Hongo, the University of Tokyo.
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 6
2
/ 6
3
/ 6
4
/ 6
5
/ 6
6
/ 6
More Related Content
PDF
モバイル(エッジ)向け ニューラルネットワーク推論エンジンの紹介
by
kcnguo
PDF
2015年度先端GPGPUシミュレーション工学特論 第14回 複数GPUの利用
by
智啓 出川
PDF
2015年度先端GPGPUシミュレーション工学特論 第15回 CPUとGPUの協調
by
智啓 出川
PDF
2015年度先端GPGPUシミュレーション工学特論 第1回 先端シミュレーションおよび産業界におけるGPUの役割
by
智啓 出川
PDF
Introduction to argo
by
Shunya Ueta
PDF
[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也
by
Preferred Networks
PDF
CUDAプログラミング入門
by
NVIDIA Japan
PPTX
Cho Bachelor Thesis
by
pflab
モバイル(エッジ)向け ニューラルネットワーク推論エンジンの紹介
by
kcnguo
2015年度先端GPGPUシミュレーション工学特論 第14回 複数GPUの利用
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第15回 CPUとGPUの協調
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第1回 先端シミュレーションおよび産業界におけるGPUの役割
by
智啓 出川
Introduction to argo
by
Shunya Ueta
[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也
by
Preferred Networks
CUDAプログラミング入門
by
NVIDIA Japan
Cho Bachelor Thesis
by
pflab
What's hot
PDF
2015年度GPGPU実践基礎工学 第1回 学際的分野における先端シミュレーション技術の歴史
by
智啓 出川
PDF
2015年度GPGPU実践基礎工学 第15回 GPGPU開発環境 (OpenCL)
by
智啓 出川
PPTX
Deep Learning Lab - Microsoft Machine Learning meetup 2018/06/27 - 推論編
by
Daiyu Hatakeyama
PDF
2015年度GPGPU実践基礎工学 第5回 ハードウェアによるCPUの高速化技術
by
智啓 出川
PDF
GCPUG-FUKUOKA データ加工&可視化ハンズオン
by
Wasaburo Miyata
PDF
Yu Sasaki Bachelor Thesis
by
pflab
PDF
2015年度GPGPU実践基礎工学 第14回 GPGPU組込開発環境
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
PDF
Junnosuke Mizutani Bachelor Thesis
by
pflab
PDF
KubeCon 2021 NA Recap - Scheduler拡張事例最前線 / Kubernetes Meetup Tokyo #47 / #k8sjp
by
Preferred Networks
PDF
How to Schedule Machine Learning Workloads Nicely In Kubernetes #CNDT2020 / C...
by
Preferred Networks
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介
by
Preferred Networks
PPTX
EC2に対するcloudwatchのアクション設定がポリシーで使えないときの代替策
by
Daisuke Nagao
PDF
2015年度GPGPU実践基礎工学 第4回 CPUのアーキテクチャ
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第6回 パフォーマンス解析ツール
by
智啓 出川
PDF
2015年度先端GPGPUシミュレーション工学特論 第11回 数値流体力学への応用 (支配方程式,CPUプログラム)
by
智啓 出川
PDF
2015年度GPGPU実践基礎工学 第6回 ソフトウェアによるCPUの高速化技術
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第15回 GPU最適化ライブラリ
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第11回 画像処理
by
智啓 出川
PDF
2015年度GPGPU実践基礎工学 第12回 GPUによる画像処理
by
智啓 出川
2015年度GPGPU実践基礎工学 第1回 学際的分野における先端シミュレーション技術の歴史
by
智啓 出川
2015年度GPGPU実践基礎工学 第15回 GPGPU開発環境 (OpenCL)
by
智啓 出川
Deep Learning Lab - Microsoft Machine Learning meetup 2018/06/27 - 推論編
by
Daiyu Hatakeyama
2015年度GPGPU実践基礎工学 第5回 ハードウェアによるCPUの高速化技術
by
智啓 出川
GCPUG-FUKUOKA データ加工&可視化ハンズオン
by
Wasaburo Miyata
Yu Sasaki Bachelor Thesis
by
pflab
2015年度GPGPU実践基礎工学 第14回 GPGPU組込開発環境
by
智啓 出川
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
Junnosuke Mizutani Bachelor Thesis
by
pflab
KubeCon 2021 NA Recap - Scheduler拡張事例最前線 / Kubernetes Meetup Tokyo #47 / #k8sjp
by
Preferred Networks
How to Schedule Machine Learning Workloads Nicely In Kubernetes #CNDT2020 / C...
by
Preferred Networks
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介
by
Preferred Networks
EC2に対するcloudwatchのアクション設定がポリシーで使えないときの代替策
by
Daisuke Nagao
2015年度GPGPU実践基礎工学 第4回 CPUのアーキテクチャ
by
智啓 出川
2015年度GPGPU実践プログラミング 第6回 パフォーマンス解析ツール
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第11回 数値流体力学への応用 (支配方程式,CPUプログラム)
by
智啓 出川
2015年度GPGPU実践基礎工学 第6回 ソフトウェアによるCPUの高速化技術
by
智啓 出川
2015年度GPGPU実践プログラミング 第15回 GPU最適化ライブラリ
by
智啓 出川
2015年度GPGPU実践プログラミング 第11回 画像処理
by
智啓 出川
2015年度GPGPU実践基礎工学 第12回 GPUによる画像処理
by
智啓 出川
Viewers also liked
PDF
GPU ソリューションラボならびに検証/導入事例のご紹介
by
Dell TechCenter Japan
PDF
1090: NVIDIA プロフェッショナルビジュアリゼーション
by
NVIDIA Japan
PPTX
CUDA & OpenCL GPUコンピューティングって何?
by
Toshiya Komoda
PDF
2014年12月13日 アカリクITイベント 川原尚人_スライド
by
nkawahara
PDF
2015年度先端GPGPUシミュレーション工学特論 第2回 GPUによる並列計算の概念と メモリアクセス
by
智啓 出川
PDF
グラフィックスの仮想化を実現する NVIDIA GRID™ ~仮想マシンからの GPU の利用方法と、今後の展開~
by
Dell TechCenter Japan
PDF
NVIDIA GRID が実現する GPU 仮想化テクノロジー
by
NVIDIA Japan
PDF
エヌビディア GPU が加速するディープラーニング
by
NVIDIA Japan
PPTX
HPCフォーラム2015 基調講演 HPテクニカルコンピューティング最前線 ~HP Apollo Systemディープダイブと、世界の採用事例~ Ed T...
by
日本ヒューレット・パッカード株式会社
PDF
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
PDF
45分で理解する 最近のスパコン事情 斉藤之雄
by
Yukio Saito
PDF
1000: 基調講演
by
NVIDIA Japan
PDF
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法
by
Kentaro Sano
PDF
Gpu vs fpga
by
Yukitaka Takemura
PDF
なぜGPUはディープラーニングに向いているか
by
NVIDIA Japan
PPTX
ディープラーニングにおける学習の高速化の重要性とその手法
by
Yuko Fujiyama
PPTX
企業の人工知能 AI
by
NVIDIA Japan
PPTX
人工知能 AI 時代の幕開け~新たなコンピューティング モデル、GPU ディープラーニングが火付け役に~
by
NVIDIA Japan
GPU ソリューションラボならびに検証/導入事例のご紹介
by
Dell TechCenter Japan
1090: NVIDIA プロフェッショナルビジュアリゼーション
by
NVIDIA Japan
CUDA & OpenCL GPUコンピューティングって何?
by
Toshiya Komoda
2014年12月13日 アカリクITイベント 川原尚人_スライド
by
nkawahara
2015年度先端GPGPUシミュレーション工学特論 第2回 GPUによる並列計算の概念と メモリアクセス
by
智啓 出川
グラフィックスの仮想化を実現する NVIDIA GRID™ ~仮想マシンからの GPU の利用方法と、今後の展開~
by
Dell TechCenter Japan
NVIDIA GRID が実現する GPU 仮想化テクノロジー
by
NVIDIA Japan
エヌビディア GPU が加速するディープラーニング
by
NVIDIA Japan
HPCフォーラム2015 基調講演 HPテクニカルコンピューティング最前線 ~HP Apollo Systemディープダイブと、世界の採用事例~ Ed T...
by
日本ヒューレット・パッカード株式会社
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
45分で理解する 最近のスパコン事情 斉藤之雄
by
Yukio Saito
1000: 基調講演
by
NVIDIA Japan
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法
by
Kentaro Sano
Gpu vs fpga
by
Yukitaka Takemura
なぜGPUはディープラーニングに向いているか
by
NVIDIA Japan
ディープラーニングにおける学習の高速化の重要性とその手法
by
Yuko Fujiyama
企業の人工知能 AI
by
NVIDIA Japan
人工知能 AI 時代の幕開け~新たなコンピューティング モデル、GPU ディープラーニングが火付け役に~
by
NVIDIA Japan
Similar to 2012 1203-researchers-cafe
PDF
【A-1】AIを支えるGPUコンピューティングの今
by
Developers Summit
PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10)
by
Ryuuta Tsunashima
PPTX
GPU-FPGA協調プログラミングを実現するコンパイラの開発
by
Ryuuta Tsunashima
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
PDF
20170421 tensor flowusergroup
by
ManaMurakami1
PDF
2012-03-08 MSS研究会
by
Kimikazu Kato
PDF
Cuda
by
Shumpei Hozumi
DOC
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
PDF
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PDF
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
PDF
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢
by
Insight Technology, Inc.
PDF
200625material naruse
by
RCCSRENKEI
PDF
Hello, DirectCompute
by
dasyprocta
PDF
GPGPU Education at Nagaoka University of Technology: A Trial Run
by
智啓 出川
KEY
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
KEY
GTC2011 Japan
by
Takuro Iizuka
PDF
インテルFPGAのDeep Learning Acceleration SuiteとマイクロソフトのBrainwaveをHW視点から比較してみる Intel編
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
GPUディープラーニング最新情報
by
ReNom User Group
KEY
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究
by
Yuichi Yoshida
【A-1】AIを支えるGPUコンピューティングの今
by
Developers Summit
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10)
by
Ryuuta Tsunashima
GPU-FPGA協調プログラミングを実現するコンパイラの開発
by
Ryuuta Tsunashima
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
20170421 tensor flowusergroup
by
ManaMurakami1
2012-03-08 MSS研究会
by
Kimikazu Kato
Cuda
by
Shumpei Hozumi
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢
by
Insight Technology, Inc.
200625material naruse
by
RCCSRENKEI
Hello, DirectCompute
by
dasyprocta
GPGPU Education at Nagaoka University of Technology: A Trial Run
by
智啓 出川
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
GTC2011 Japan
by
Takuro Iizuka
インテルFPGAのDeep Learning Acceleration SuiteとマイクロソフトのBrainwaveをHW視点から比較してみる Intel編
by
Deep Learning Lab(ディープラーニング・ラボ)
GPUディープラーニング最新情報
by
ReNom User Group
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
Halide, Darkroom - 並列化のためのソフトウェア・研究
by
Yuichi Yoshida
More from Toshiya Komoda
PDF
5分で分かるselenium conference berlin 2017
by
Toshiya Komoda
PDF
Introduce Machine Learning into UI Tests
by
Toshiya Komoda
PDF
selenimu commiter day 2017: Methods to Sustain Long Term Operations of E2E Au...
by
Toshiya Komoda
PDF
Isca13 study
by
Toshiya Komoda
PPTX
Micro12勉強会 20130303
by
Toshiya Komoda
PDF
20130126 sc12-reading
by
Toshiya Komoda
5分で分かるselenium conference berlin 2017
by
Toshiya Komoda
Introduce Machine Learning into UI Tests
by
Toshiya Komoda
selenimu commiter day 2017: Methods to Sustain Long Term Operations of E2E Au...
by
Toshiya Komoda
Isca13 study
by
Toshiya Komoda
Micro12勉強会 20130303
by
Toshiya Komoda
20130126 sc12-reading
by
Toshiya Komoda
2012 1203-researchers-cafe
1.
CPU・GPU
ハイブリッドコンピューティング 薦田 登志矢システム情報学専攻 博士3年 komoda@hal.ipc.i.u-tokyo.ac.jp 1 2012 12/3 リサーチャーズカフェ 2012/12/5
2.
並列計算機としてのGPU
GPU is Everywhere Top 500 super computers 52/500 のスパコンにGPUが搭載 (ICS, 2012) ラップトップ・モバイル端末 GPUが搭載されているのが普通 AMD Radeon 汎用的な並列処理をGPU上で実行 (GPUコンピューティング) 科学技術計算 データマイニング 動画像処理 NVIDIA Tesla 2 2012 12/3 リサーチャーズカフェ 2012/12/5
3.
ヘテロジニアスシステム上の タスクスケジューリング
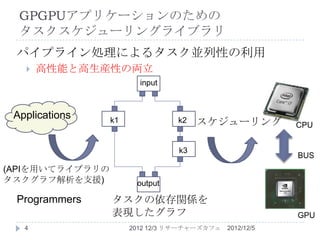
実用的なGPGPUアプリケーション 「CPU処理」・「GPU処理」・「データ転送 処理」が 混在 GPU上でデータ並列性だけを利用するだ けでは不十分. 粒度の大きなタスク並列性の利用 CPU・GPU・データ転送バスという異なるデバ イス上 3 で異なるタスクを並列実行したい 2012/12/5 2012 12/3 リサーチャーズカフェ
4.
GPGPUアプリケーションのための タスクスケジューリングライブラリ
パイプライン処理によるタスク並列性の利用 高性能と高生産性の両立 input Applications k1 k2 スケジューリング CPU k3 BUS (APIを用いてライブラリの タスクグラフ解析を支援) output Programmers タスクの依存関係を 表現したグラフ GPU 4 2012 12/3 リサーチャーズカフェ 2012/12/5
5.
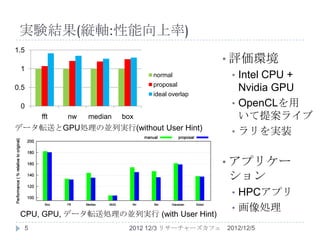
実験結果(縦軸:性能向上率) 1.5
• 評価環境 1 normal • Intel CPU + proposal 0.5 ideal overlap Nvidia GPU 0 • OpenCLを用 fft nw median box いて提案ライブ データ転送とGPU処理の並列実行(without User Hint) • ラリを実装 • アプリケー ション • HPCアプリ • 画像処理 CPU, GPU, データ転送処理の並列実行 (with User Hint) 5 2012 12/3 リサーチャーズカフェ 2012/12/5
6.
今後の課題
大規模なアプリケーションへの提案ライブラリ の適用 複数アクセラレータの並列実行 低消費電力技術との融合 動的電圧周波数制御とタスクスケジューリングの強調 GPUアプリケーションの 消費電力測定系 6 2012 12/3 リサーチャーズカフェ 2012/12/5
Download










![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)













![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)














