背景(GPUの欠点)
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 2
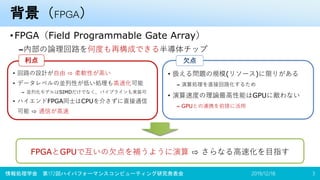
•条件分岐
• データレベルの並列性が低い処理
• 通信が多い処理(データ交換、制御など)
GPUの苦手な処理
GPUの苦手な処理をFPGAにより高速化
• 宇宙物理分野におけるLocally Essential Tree (LET) 生成のFPGAオフロード
– 計算+通信のオフロードにより、CPU実行に対し7.2倍高速化
[Tsuruta, C. et al, Off-loading let generation to peach2: A switching hub for high performance gpu
clusters. HEART, 2015]



![背景(GPUの欠点)
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 2
• 条件分岐
• データレベルの並列性が低い処理
• 通信が多い処理(データ交換、制御など)
GPUの苦手な処理
GPUの苦手な処理をFPGAにより高速化
• 宇宙物理分野におけるLocally Essential Tree (LET) 生成のFPGAオフロード
– 計算+通信のオフロードにより、CPU実行に対し7.2倍高速化
[Tsuruta, C. et al, Off-loading let generation to peach2: A switching hub for high performance gpu
clusters. HEART, 2015]](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-3-320.jpg)




![既存のプログラミング環境(続き)
•CUDAとOpenCLの組み合わせにより、GPUとFPGAを一つのプロセス
から利用する
–我々はこの手法が実現可能であることを確認している
[中道安祐未. et al, GPU・FPGA 混載ノードにおけるヘテロ演算加速プログラム環境に関する研究, HPC168, 2019]
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 8
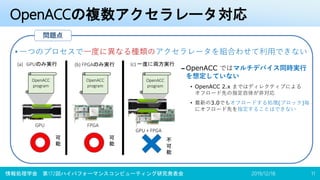
• それぞれ全く異なる言語で記述しなければならない
– 2つの言語のプログラミングスキルが必要
– ますますハードルが上がる
• CUDA、OpenCL 両方のホストプログラムの用意が必要
– 記述量が膨大になりかなりユーザーの負担が大きい
• OpenCLに挙げた問題点は依然として残っている
問題点CUDA OpenCL
object object
実行
ファイル
リンク
分割
コンパイル
GPU FPGA](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-9-320.jpg)

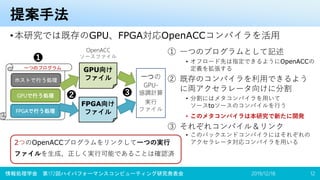
![OpenACCのアクセラレータ対応状況
•対応アクセラレータはコンパイラの実装次第
–GPU、メニーコアCPUに対応したものが一般向けに存在
• 特にPGI CompilerはNVIDIA社の傘下の企業が開発しており、CUDAに迫る性能を実現可能
–FPGAには研究用コンパイラのみ対応
• 米国 Oak Ridge National Laboratory (ORNL) で開発中の OpenARC
[Lee, S. et al., OpenACC to FPGA: A Directive-Based High-Level Programming Framework for
High-Performance Reconfigurable Computing, SC18, 2018]
2019/12/18 10
本研究ではOpenACCを用いた統一プログラミング環境を提案
情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-11-320.jpg)

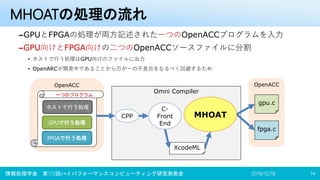

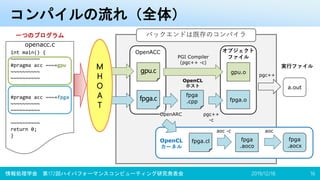
![オフロード先の指定
•#pragma accomn ondevice(デバイス名)
–独自のOpenACC拡張ディレクティブを定義
• Omni Compiler内の拡張であるため accomn
–デバイス名のところにenum型の GPU、FPGA
をどちらか一方記述
–現実装ではこのディレクティブが書かれた関数
ごと、デバイスに対応するそれぞれのファイル
に出力される
–よって、以下の制限がある
• main関数以外の関数の中に記述が必要
• 関数内の先頭に一つだけしか記述できない
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 17
void fpga() {
#pragma accomn ondevice(FPGA)
{
#pragma acc data copy(a, b)
{
#pragma acc kernels loop independent
for(i=0; i < N; i++)
a[i] = a[i] + b[i];
}
}
}](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-18-320.jpg)
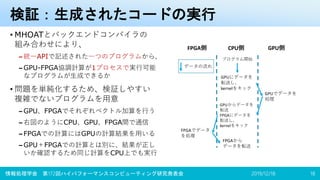

![実験環境(CCS Cygnus)
• CPU0上でGPU、FPGAをそれぞれ1台ずつ使用
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 20
ハードウェア構成
CPU
Intel Xeon Gold 6126
(12C / 2.6GHz) x2
Host Memory DDR4-2666 16GiB x12
GPU
NVIDIA Tesla V100
(32GiB HBM2 PCIe 3.0 x16) x4
FPGA
Intel Stratix 10 GX 2800
(BittWare 520N[22]
PCIe Gen3 x16) x2
ソフトウェア構成
OS CentOS 7
GPU + Host
Compiler
PGI Compiler 19.1
FPGA Compiler OpenARC V0.17 (Oct, 2019)
OpenCL
Compiler
Intel FPGA SDK for OpenCL
19.1.0.240
CPU
0
CPU
1
PCIenetwork(switch)
PCIenetwork(switch)
GPU
GPUGPU
GPU
SINGLE NODE
(with FPGA)
HCA
FPGA
HCA
FPGA
HCA
HCA
Networkswitch(100Gbpsx2)
Networkswitch(100Gbpsx2)
Inter-FPGA
direct network
(100Gbps x4)
Inter-FPGA
direct network
(100Gbps x4)
Cygnus構成図](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-21-320.jpg)
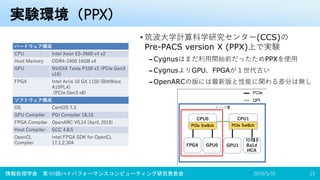
![MHOAT変換結果(GPU側)
• OpenACC以外のコンパイラ指示文は省略、連続する波括弧は一行に圧縮
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 21
void funcGPU(float * a, float * b, float * d, int size)
{
{
int j;
#pragma acc data copyin ( a [ 0 : size ] , b [ 0 :
size ] ) copyout ( d [ 0 : size ] )
{
#pragma acc kernels loop independent gang worker
( 16 )
for(j = (0); j < size; j++) {
{
(*(d + j)) = ((*(a + j)) + (*(b + j)));
}}}}}
void funcGPU(float* a, float* b, float* d, int size) {
#pragma accomn ondevice(GPU)
{
int j;
#pragma acc data copyin(a[0:size], b[0:size])
copyout(d[0:size])
{
#pragma acc kernels loop independent gang
worker(16)
for (j = 0; j < size; j++) {
d[j] = a[j] + b[j];
}
} } }
入力ファイル(抜粋) 出力ファイル(抜粋)](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-22-320.jpg)
![MHOAT変換結果(FPGA側)
• OpenACC以外のコンパイラ指示文は省略、連続する波括弧は一行に圧縮
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 22
void funcFPGA(float * a, float * b, int size)
{
{
int j;
#pragma acc data copyin ( a [ 0 : size ] ) copyout ( b [ 0 :
size ] )
{
#pragma acc kernels
{
#pragma acc loop independent
for(j = (0); j < size; j++) {
{
(*(b + j)) = ((*(a + j)) + ((float)(j)));
}}}}}}
void funcFPGA(float *a, float *b, int size) {
#pragma accomn ondevice(FPGA)
{
int j;
#pragma acc data copyin(a[0:size]) copyout(b[0:size])
{
#pragma acc kernels
{
#pragma acc loop independent
for (j = 0; j < size; j++) {
b[j] = a[j] + (float)j;
}
} } } }
出力ファイル(抜粋)入力ファイル(抜粋)](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-23-320.jpg)





![今後の展望
•我々が実装中のGPU-FPGA間DMAをOpenACCから行えるようにす
る
–現在OpenCLでの呼び出しに対応
–本報告ではGPU-FPGA間のデータ転送にホストのメモリを一旦介していた
–現状、GPU上とFPGA上の変数は全く別のスコープなので、ホストでしかデータ
をコピーできない
–まず、両デバイスの変数を同一スコープで扱える必要がある
•XcalableACC*での本手法の包括
–ディレクティブ形式の分散メモリ環境用言語XcalableMP*をOpenACCで拡張
した言語(理研と共同研究中)
–複数プロセス並列、同一デバイスの複数利用にも対応するようにする
*[Nakao, M, et al., Evaluation of XcalableACC with Tightly Coupled Accelerators/InfiniBand Hybrid
Communication on Accelerated Cluster, 2019]
2019/12/18情報処理学会 第172回ハイパフォーマンスコンピューティング研究発表会 32](https://image.slidesharecdn.com/hpc172ver2-191220184806/85/GPU-FPGA-33-320.jpg)













![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)
































