Downloaded 76 times




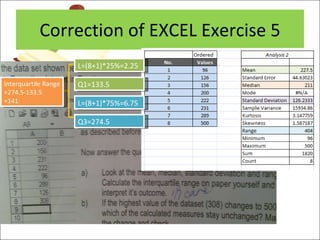
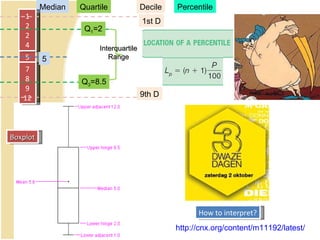
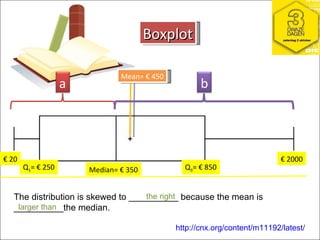
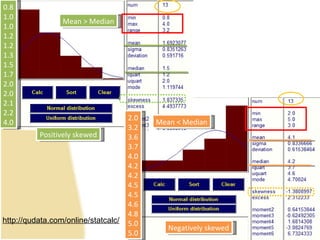





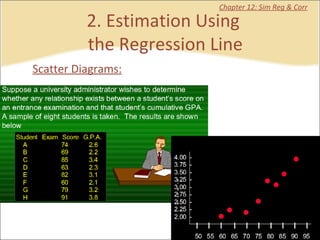
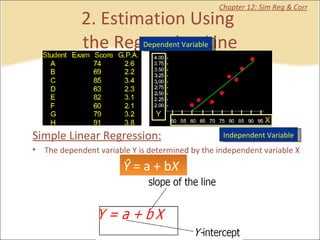



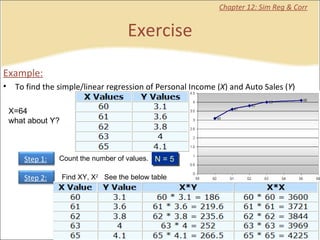
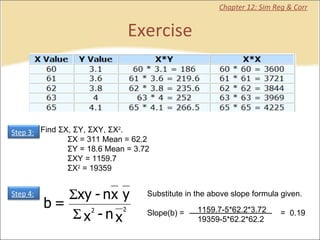

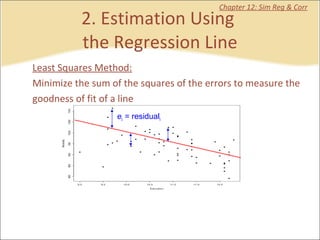

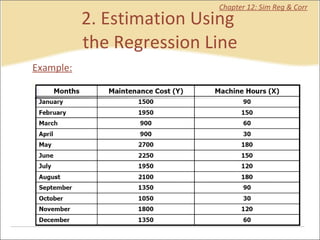




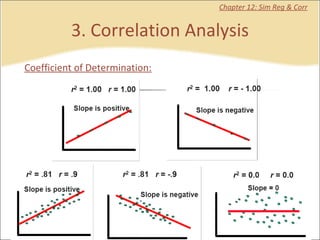
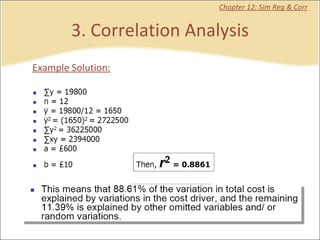
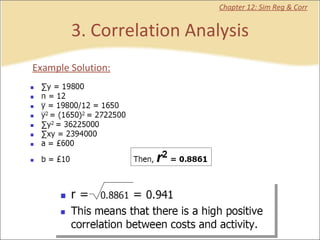


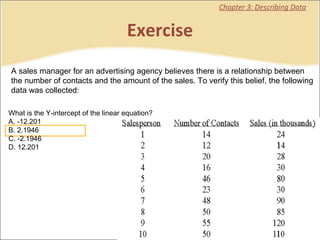

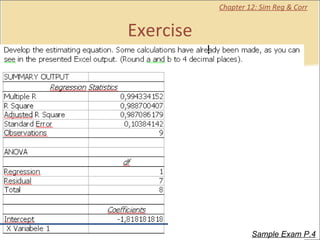
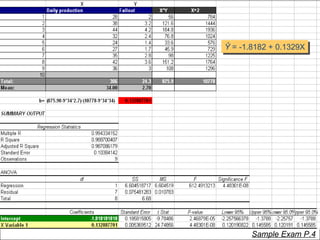


This document contains summaries and examples of key concepts in regression analysis and correlation from Chapter 12, including: - Regression analysis is used to estimate relationships between variables and predict future values of dependent variables based on independent variables. - Correlation analysis describes the strength of the linear relationship between two variables from 0 to 1. - The least squares method is used to fit a regression line that minimizes the squared errors between observed and predicted values.











































































































