This document outlines the schedule and topics for an advanced econometrics and Stata training course taking place in Beijing from November 17-26, 2019. The course will cover topics including introduction to econometrics and Stata, single and multiple regression, hypothesis testing, time series models, panel data models, and frontier analysis. Sessions are planned each morning and evening, with exercises and practice sessions interspersed.















































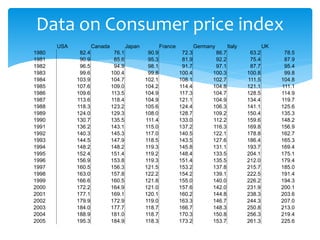
![Q2: Inflation rate
This is an excel based exercise
Using table below, compute the inflation rate for 7
industrialized countries.
Subtract from the current year’s CPI the CPI of the
previous year, divide the difference by the previous
year’s CPI, and multiply the result by 100.
For example, the inflation rate for Canada for 1981 is
[(85.6-76.1)/76.1]*100=12.48%](https://image.slidesharecdn.com/advancedeconometricsl3-4-240128102442-58a0f1f1/85/Advanced-Econometrics-L3-4-pptx-58-320.jpg)