Downloaded 22 times




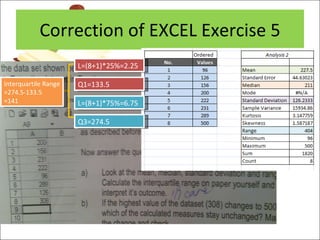
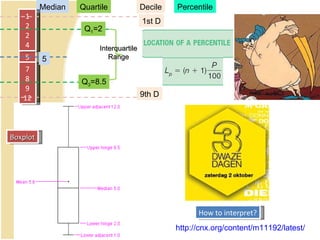
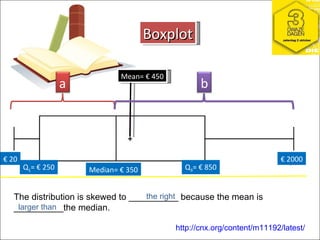
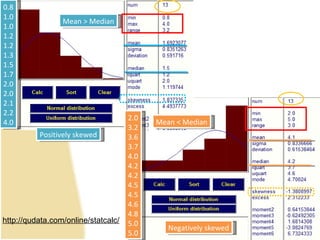
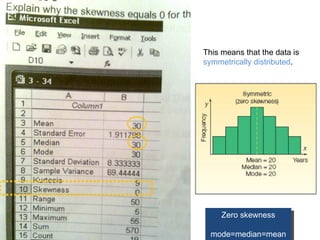


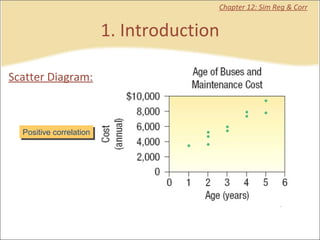


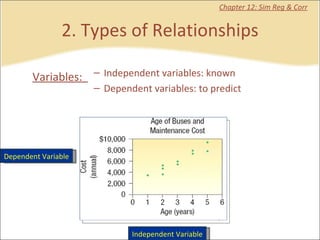
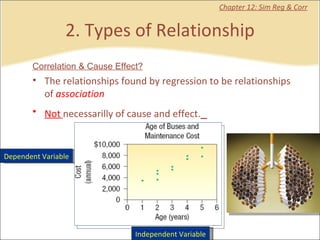

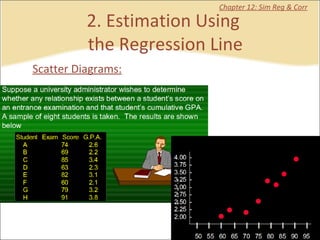
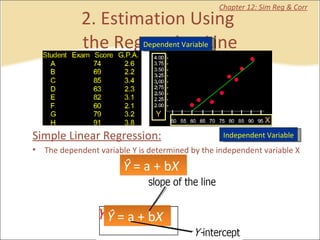



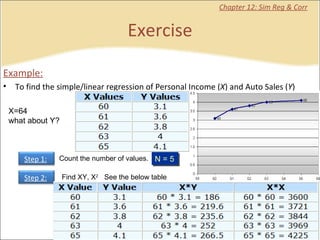
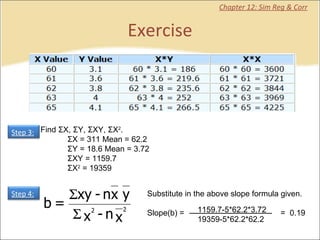

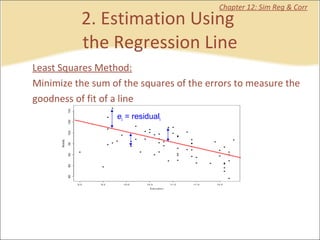

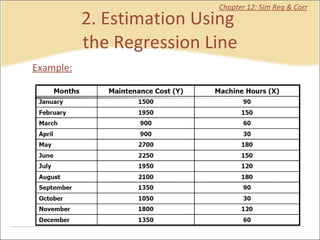




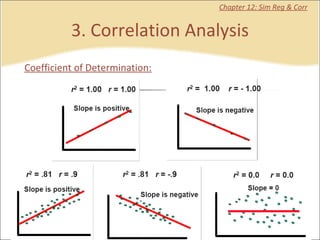
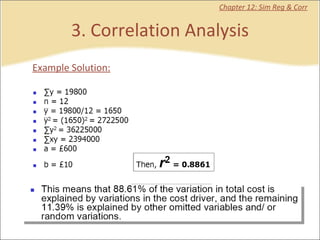
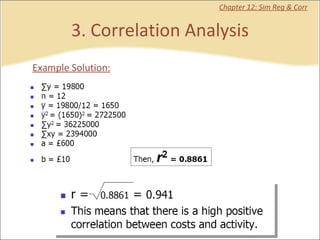


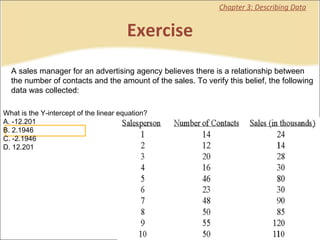

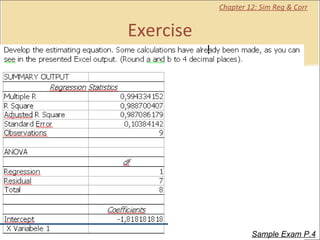
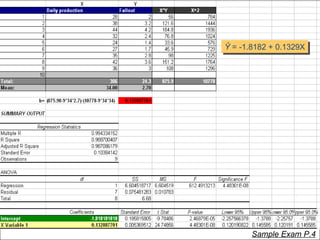


This document provides a summary of key concepts from chapters on simple regression and correlation analysis. It defines regression analysis as determining the nature and strength of relationships between variables. Scatter plots are used to visualize these relationships. The regression line estimates the relationship between an independent and dependent variable. Correlation analysis describes the degree of linear relationship between variables using the coefficient of determination and coefficient of correlation. Examples are provided to demonstrate calculating the regression equation and correlation coefficient.























































































