Download as PDF, PPTX


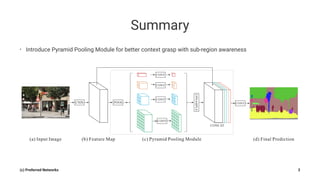



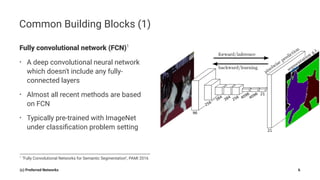

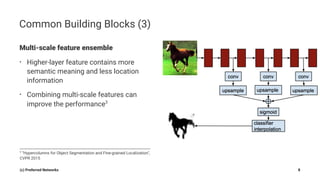
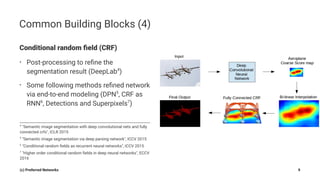
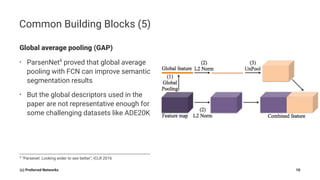




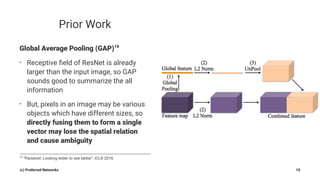
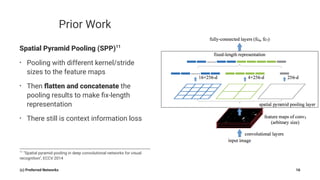
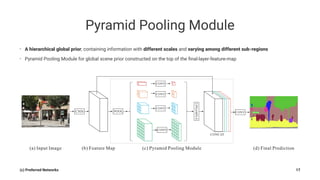
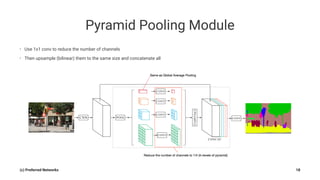




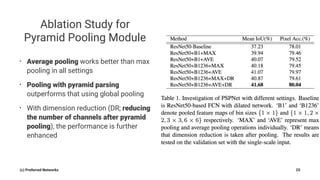

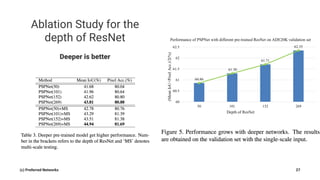
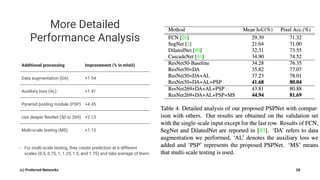

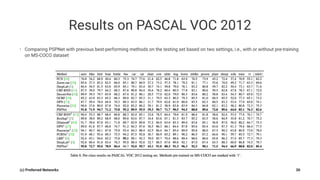
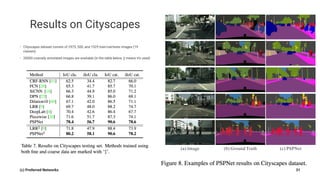


Pyramid Scene Parsing Network introduces the Pyramid Pooling Module to improve semantic segmentation. The module captures context at different regions and scales by performing average pooling at different pyramid levels on the final convolutional feature map. Experiments on ADE20K and PASCAL VOC datasets show the Pyramid Pooling Module improves mean Intersection-over-Union by over 4% compared to global average pooling, achieving state-of-the-art performance.






















![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[5 minutes LT] Brief Introduction to Recent Image Recognition Methods and Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/fashion-tech-2017-06-06-170626055616-thumbnail.jpg?width=640&height=640&fit=bounds)




























