DeepPose: Human Pose Estimation via Deep Neural Networks
1.
DeepPose: Human PoseEstimation
via Deep Neural Networks
発表:齋藤 俊太**
**慶應義塾大学大学院理工学研究科 後期博士課程
Alexander Toshev*, Christian Szegedy*
* Google
2.
DeepCNNで姿勢推定
• ILSVRC 2014でトップだったGoogLeNetチーム(の一部の人)が書いたDeepCNNによる姿勢推定の論文
•LSP (Leeds Sports Pose) Dataset, FLIC (Frames Labeled In Cinema) Datasetを用いて学習・テスト
• ILSVRC 2012でトップだったAlexNet(proposed by Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, 全員現
Googler)のアーキテクチャをそのまま利用
• 投稿時点(arXiv初出 17 Dec 2013)ではstate-of-the-art
• DeepCNNを使って回帰問題として姿勢推定を解いた最初の論文で,以降のベンチマーク的手法
• その後グラフィカルモデルと合わせてこれを改善した論文がいくつか発表されている
DeepPose: Human Pose Estimation via Deep Neural Networks
図:Toshev, A. et al., “DeepPose: Human Pose Estimation via Deep Neural Networks” より
3.
Introduction
• 人間は隠れている関節の位置も他の部位のようすやその対象人物の動きなどから推測することができる
• つまり「全体的に見て推測する(holisticreasoning)」ことが重要
• Deep Neural Network (DNN) ならこの辺をうまくやってくれそう
• パーツごとに検出して,あとでパーツ間の関係を考慮する手法は大量に提案されてきたが,あり得るパーツ間
の相互関係のうちの小さな部分集合を考慮に入れることしかできていない
• DNNを用いると特徴量を設計しなくてよいしパーツ検出器もデザインしなくてよい上に関節間の相互関係な
どのモデルさえ用意しなくてよい
• DeepPoseでは複数のDNNを直列につなげる
• まずおおまかに各関節の初期位置を推定するDNNを使い,推定された各関節位置のまわりの画像を元画像か
ら取ってきなおして,その関節まわりの高解像度なパッチを次のDNNに入力する
図:Toshev, A. et al., “DeepPose: Human Pose Estimation via Deep Neural Networks” より
4.
図:Ramanan, D. “Learningto parse images of articulated bodies” より
Related Work
• 関節構造のある物体は一般的に構成パーツのグラフとして表される
• Pictorial Structureという手法ではパーツ間の位置関係の変化に対するコストと各パーツの見えに対するコスト
の和を最小化するように事前に定義しておいたパーツのグラフ(木構造等)をフィッティングする
• このアプローチを改善していくためにはパーツ検出器を強化するかより複雑な関節間の関係を表現できるよ
うにするか,という2つの道しかない
• パーツ検出器をリッチにしたもの,Latent SVMとPictorial Structureを組合せてより複雑な関係を表現できる
ようにしたものなどが提案された
図:Huttenlocher, D. “Object Recognition Using Pictorial Structures” スライドより
人体を「パーツが連結されたもの」として考える手法
図:Yang, Y. et al. "Articulated Human Detection with Flexible Mixtures of Parts” より
5.
Related Work
• 色々な姿勢の人を色々な視点から撮ったときの画像(exampler)を用意し
て関節位置のラベルをつけておく
•新しい画像が得られたら事前に用意したexamplerのどれと近いかを調べる
• これを高速化した手法や,腕だけに注目して「腕部分の姿勢」を事前に何
パターンも用意しておき,腕あたりを切り出した入力画像に対して,各姿勢
に該当する/しないを判断する分類器をたくさん用意しておく手法など
人体姿勢を部分に分けず全体的に推定する(=Holisticな)手法
図:Mori, G. et al. “Recovering 3d Human Body Configurations Using Shape Contexts” より
図:Gkioxari, G. et al. “Articulated Pose Estimation using
Discriminative Armlet Classifiers” より
パーツベースだと終わる例
Gkioxari,G.etal.“ArticulatedPose
EstimationusingDiscriminative
ArmletClassifiers”より
6.
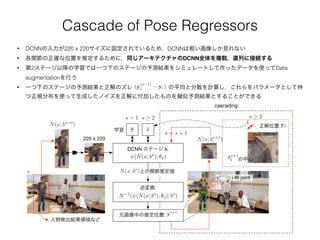
Deep Learning Modelfor Pose Estimation
• 姿勢は「各関節の位置座標値を一列に連結したベクトル」で表す→
• よってラベル付き画像とは「画像 x と姿勢ベクトル y 」の組となる
• 普通データセット上では各関節の位置座標は画像上の絶対座標で表されているので,人物領域をくくっ
た bounding box b の中心からの相対的な位置を表すように正規化しておく↓
y = (. . . , yT
i , . . . )T
, i 2 {1, . . . , k}
N(yi; b) =
1/bw 0
0 1/bh
!
(yi bc)
• この正規化姿勢ベクトルを N(y; b) と表し,また元画像から同じ
bounding boxの領域を切り出した画像を N(x; b) と書くことにする
• 以降この人物領域 box b で正規化することを N(・) と書く
データセット中の元画像(関節位置ラベルが付随する)
bh
bw
bc
yi
正規化画像 N(x; b)
図:FLICデータセット より
7.
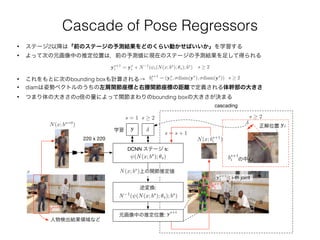
Pose Estimation asDNN-based Regression
• 元画像 x を姿勢ベクトル y に回帰する関数 を学習したい (k: 関節の数)(x; ✓) 2 R2k
• 元画像 x 中の関節位置 y* を予測するというのは,正規化画像を ψ に入れて正規化姿勢ベクトルを得て,
これを元画像の座標系に変換しなおすということなので
y⇤
= N 1
( (N(x); ✓))
• ψを事前に決めておいたサイズ(220 x 220)の3チャンネル入力画像 (=N(x)) を入力にとり,2k次元の連
続値ベクトル y* を出力するDeep Convolutional Neural Networkで近似する
• DeepCNNのアーキテクチャとしてはAlexNetをそのまま使う(ただし最終層は1000 unitsではなく2k
unitsにする)
➡ AlexNetは,C(55 x 55 x 96) - LRN - P - C(27 x 27 x 256) - LRN - P - C(13 x 13 x 384) - C(13 x 13 x
384) - C(13 x 13 x 256) - P - F(4096) - F(4096) - F(2k) からなる13層のアーキテクチャ.ただし学習
可能パラメータを持っているのはC(convolutional)層とF(fully-connected)層だけ(パラメータ数は約
4000万)なので「7層NN」
➡ 活性化関数には全てReLUを使用
➡ C層のフィルタサイズは下から順に
11x11, 5x5, 3x3, 3x3, 3x3
• It’s truly holistic!!
• 姿勢推定用のモデルを設計しなくてよい
図:Toshev, A. et al., “DeepPose: Human Pose Estimation via Deep Neural Networks” より






















![[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170821onodeepposepresentation-170928100207-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19](https://cdn.slidesharecdn.com/ss_thumbnails/190816dlseminar3dhpe-190816032821-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Human Pose Estimation @ ECCV2018](https://cdn.slidesharecdn.com/ss_thumbnails/180928dlseminarposeestimationeccv2018-180928031032-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera](https://cdn.slidesharecdn.com/ss_thumbnails/dl2018216vnect1-180323034835-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL Hacks 実装]Representation Learning by Rotating Your Faces](https://cdn.slidesharecdn.com/ss_thumbnails/representaitonlearningbyrotatingyourface1-171120115059-thumbnail.jpg?width=640&height=640&fit=bounds)



![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)

![[5 minutes LT] Brief Introduction to Recent Image Recognition Methods and Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/fashion-tech-2017-06-06-170626055616-thumbnail.jpg?width=640&height=640&fit=bounds)







