Download as PDF, PPTX








![PointNet Modifications Architecture #1: Uncertainty estimation?
https://arxiv.org/pdf/1703.04977.pdf
http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html
[in classification
pipeline only] not in
segmentation part](https://image.slidesharecdn.com/3dv2017initreport-170503031811/85/PointNet-11-320.jpg)



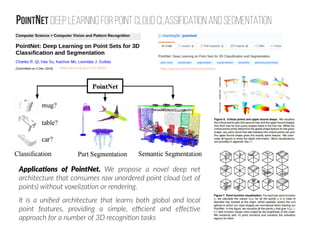
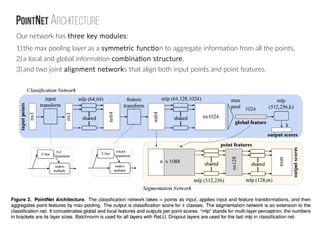
The document discusses the application of deep learning techniques to 3D point cloud data, emphasizing its significance in fields such as augmented reality and autonomous driving. It highlights ongoing research efforts, such as workshops aimed at fostering interdisciplinary collaboration to improve 3D data processing, and introduces PointNet, a novel architecture for classification and segmentation of unordered point clouds. The document also outlines the architectural components and performance metrics of PointNet, including pooling operations and potential applications in various domains.





![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pyramid Stereo Matching Network](https://cdn.slidesharecdn.com/ss_thumbnails/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] Google Cloud で実現するバックアップ ディザスタリカバリのベストプラクティス 2019年4月25日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0425-190425095700-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Approximating CNNs with Bag-of-local-Features models works surprisingl...](https://cdn.slidesharecdn.com/ss_thumbnails/bagnet-190719032153-thumbnail.jpg?width=640&height=640&fit=bounds)

![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)














![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_240611]Graph R-CNN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240611graphr-cnn-240704112605-f42276be-thumbnail.jpg?width=640&height=640&fit=bounds)





































