Download as PDF, PPTX



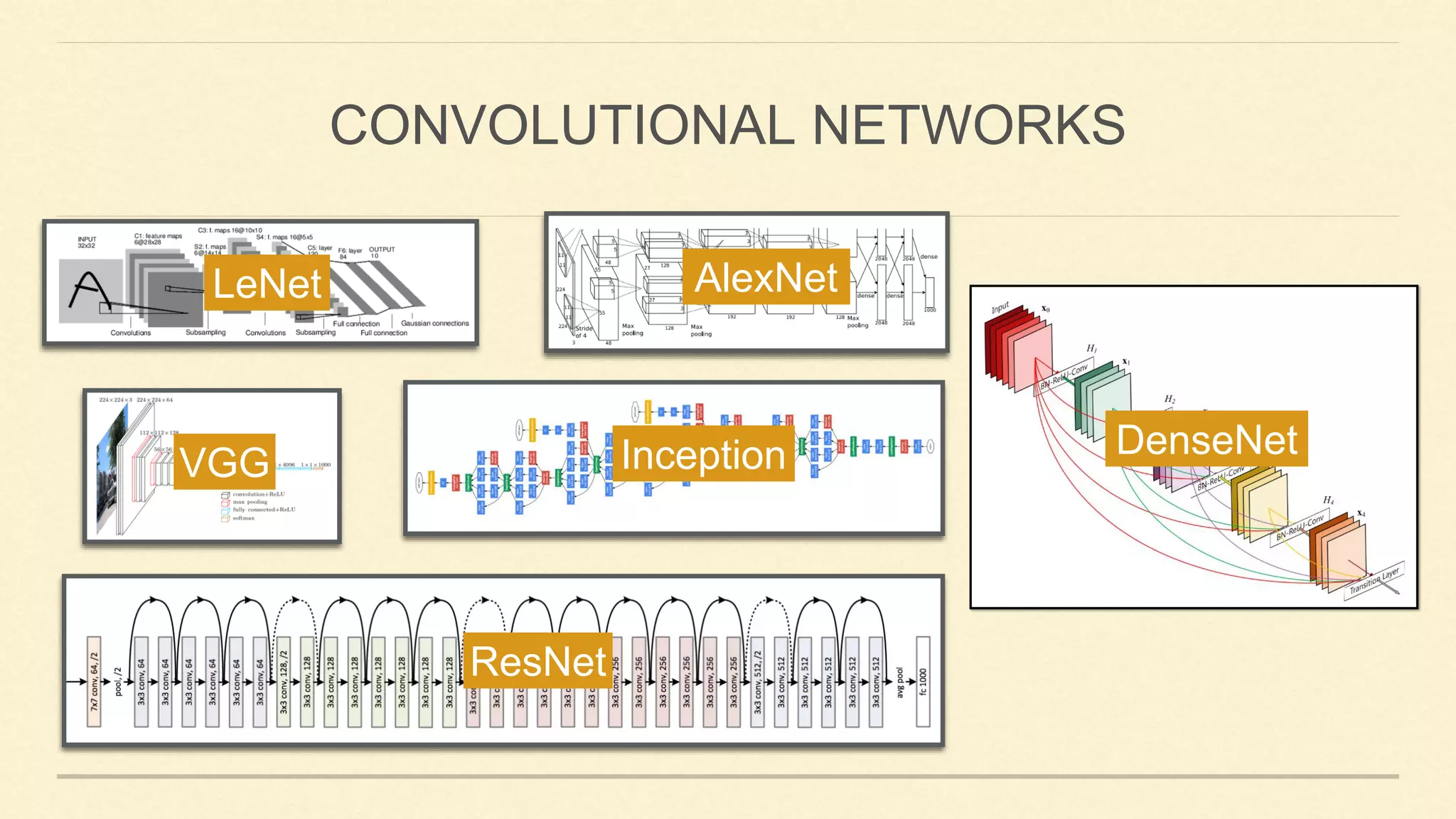
![Main Ideas:
✓ Convolution, local receptive fields, shared weights
✓ Spatial subsampling
LENET [LECUN ET AL. 1998]](https://image.slidesharecdn.com/gaohuang-190826085652/75/Architecture-Design-for-Deep-Neural-Networks-I-5-2048.jpg)
![Main Ideas:
✓ ReLU (Rectified Linear Unit)
✓ Dropout
✓ Local Response Normalization, Overlapping Pooling
✓ Data Augmentation, Multiple GPUs
ALEXNET [KRIZHEVSKY ET AL. 2012]](https://image.slidesharecdn.com/gaohuang-190826085652/75/Architecture-Design-for-Deep-Neural-Networks-I-6-2048.jpg)
![Main Idea:
✓ Skip connection: promotes gradient propagation
RESNET [HE ET AL. 2016]
Identity mappings promote gradient propagation.
: Element-wise addition](https://image.slidesharecdn.com/gaohuang-190826085652/75/Architecture-Design-for-Deep-Neural-Networks-I-7-2048.jpg)
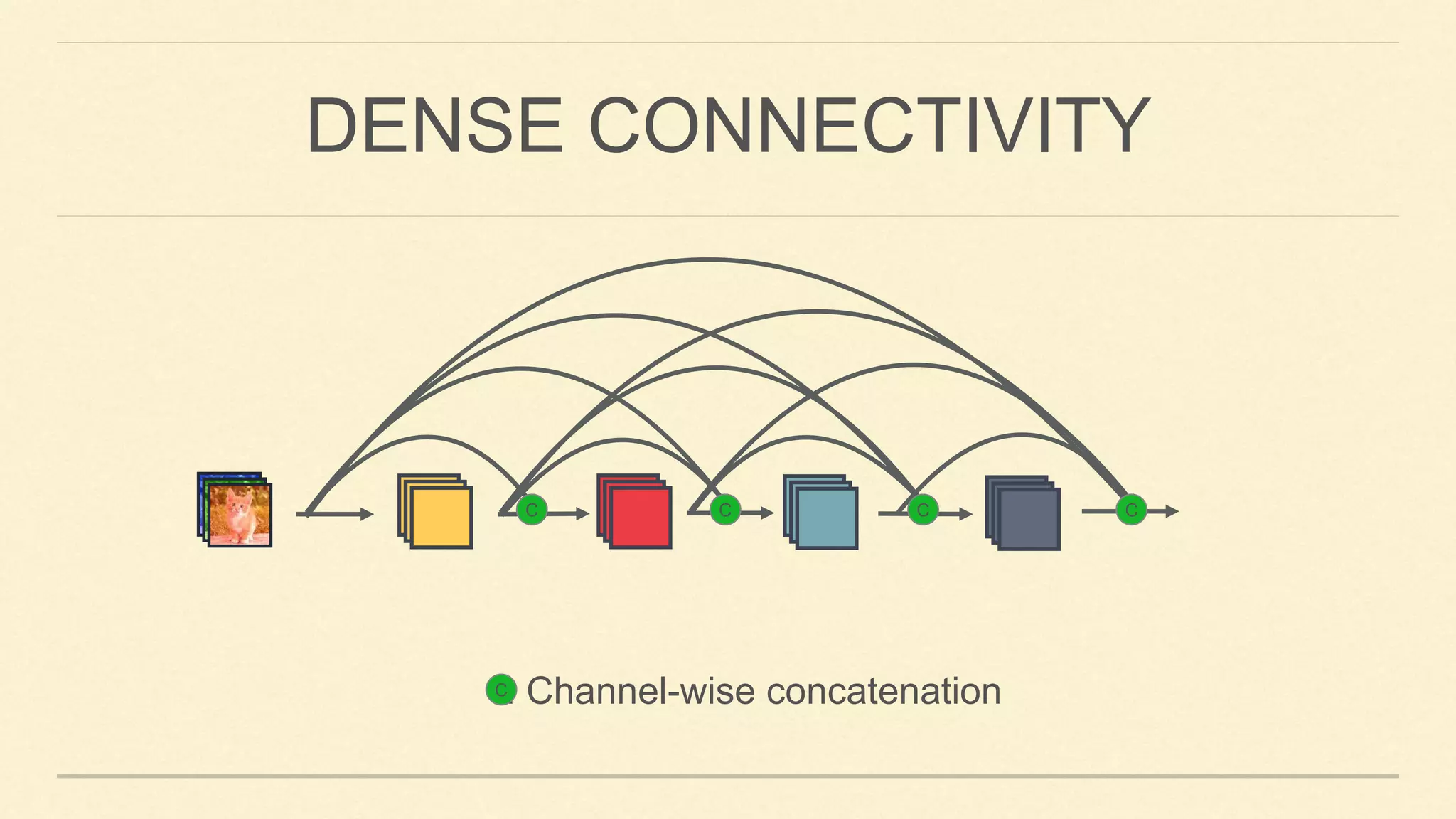
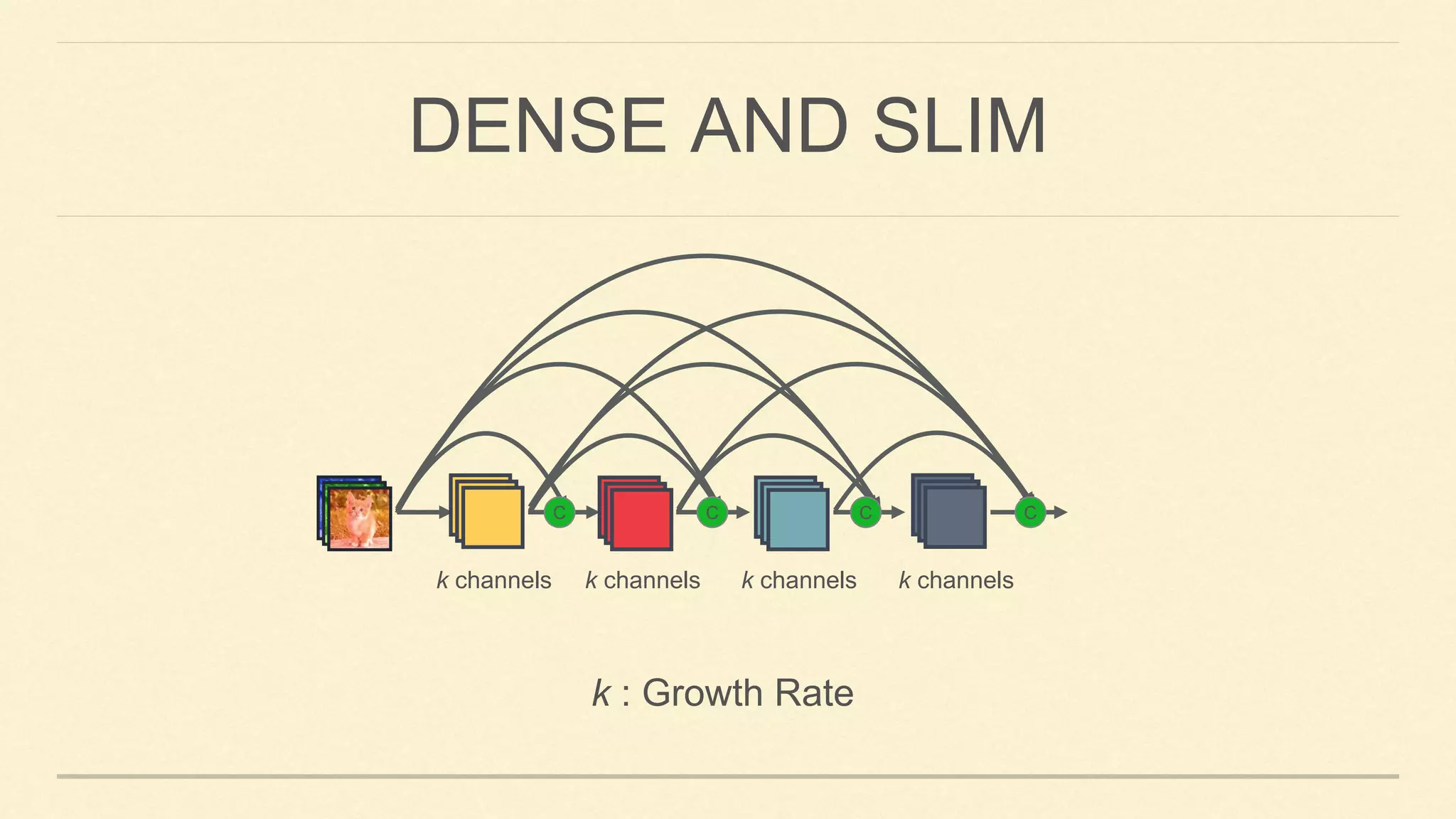
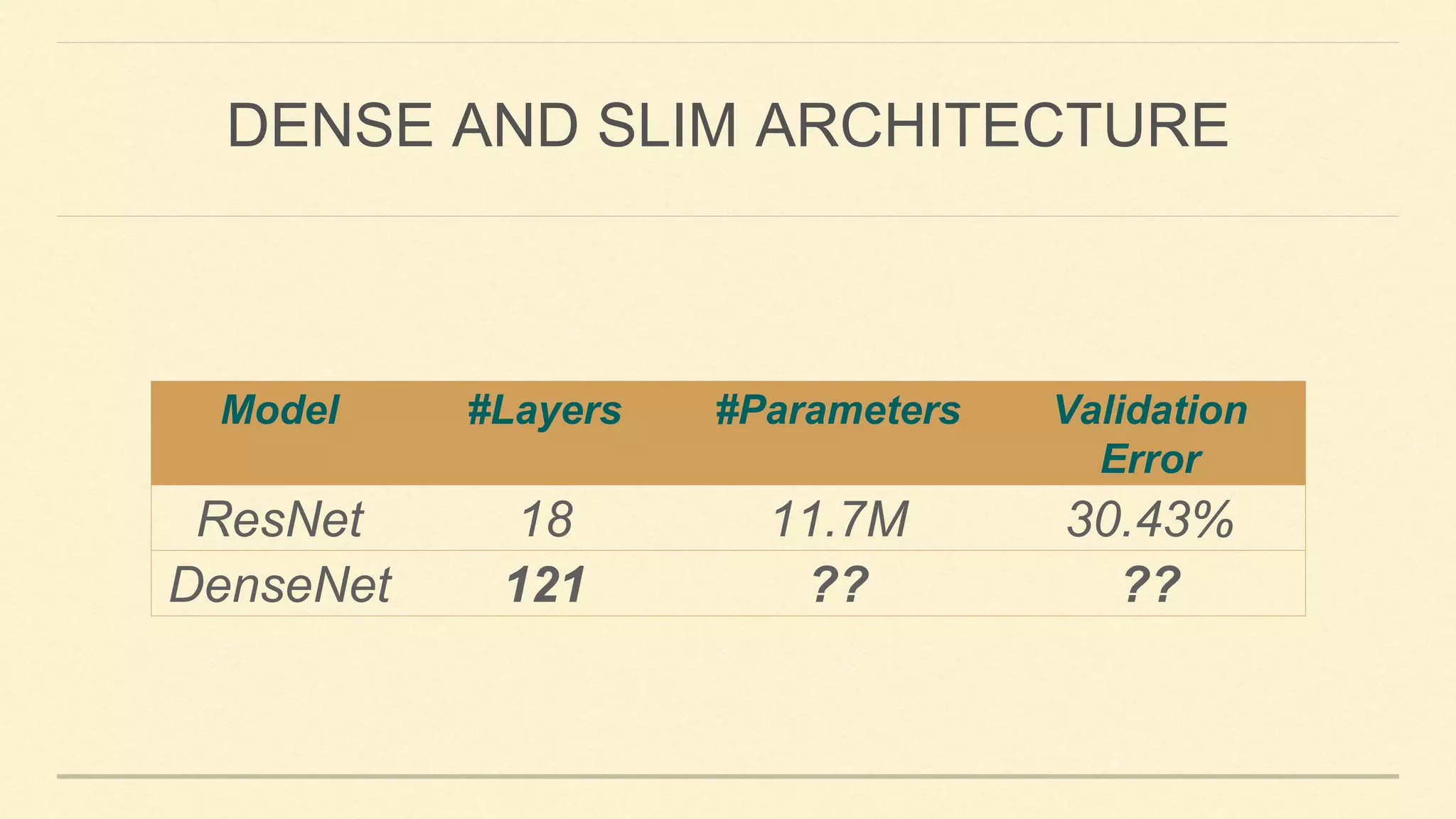
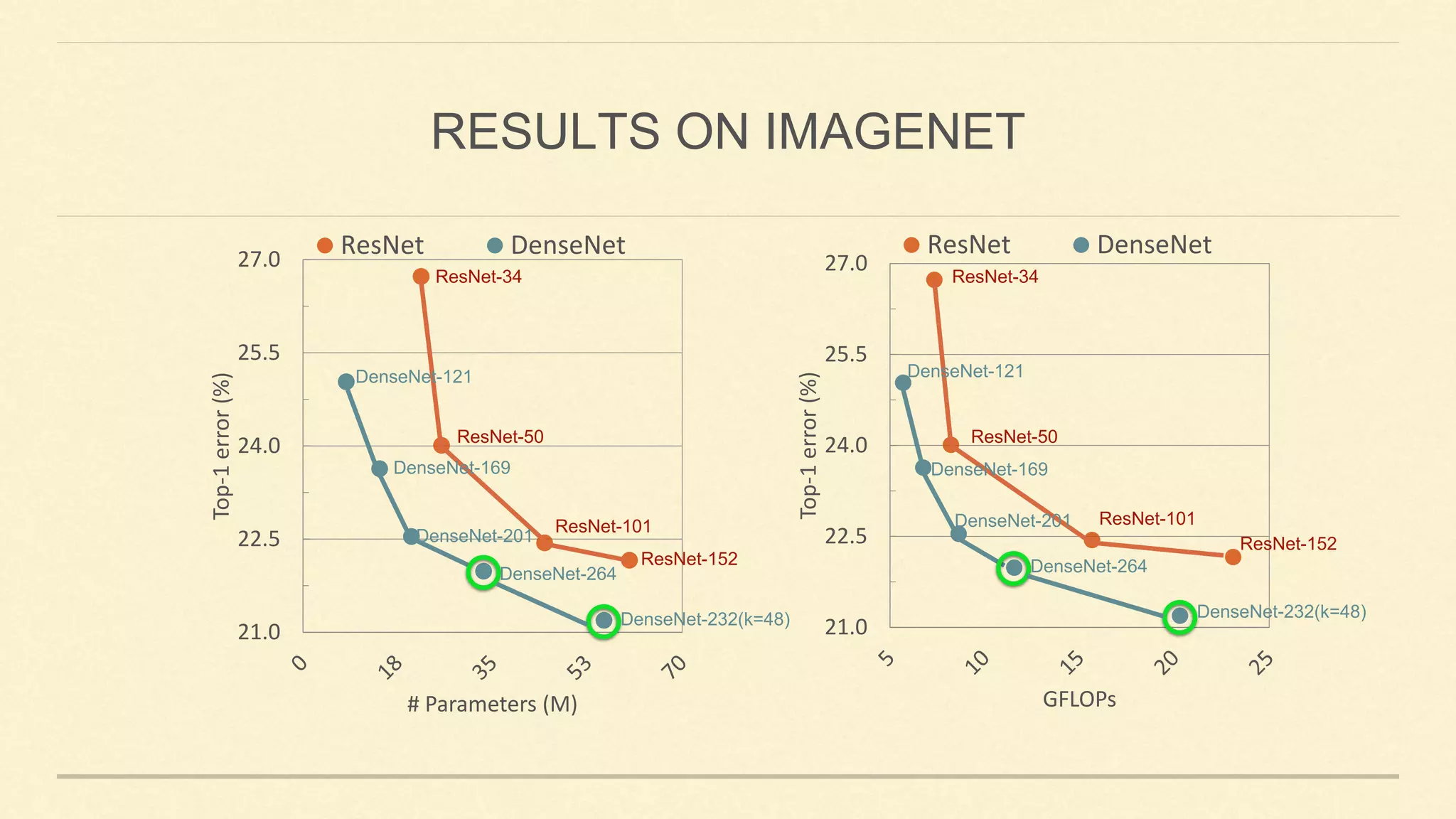
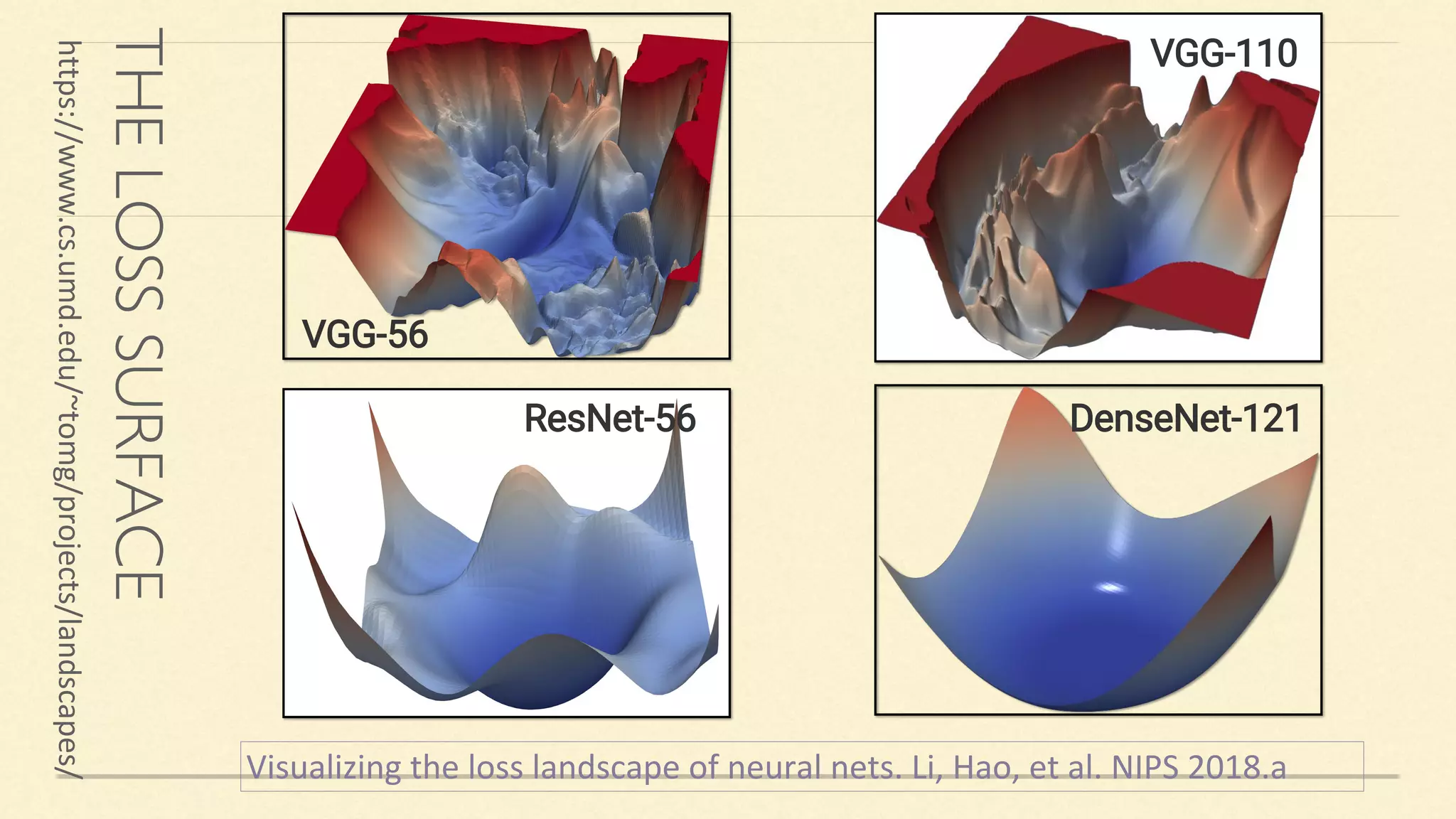
![Main Idea:
✓ Dense connectivity: creates short path in the network and encourages feature reuse.
ResNet
GoogleNet
FractalNet
DENSENET [HUANG ET AL. 2017]](https://image.slidesharecdn.com/gaohuang-190826085652/75/Architecture-Design-for-Deep-Neural-Networks-I-8-2048.jpg)


![Main Idea:
✓ Automatic architecture search using reinforcement learning, genetic/evolutional
algorithms or differentiable approaches.
AutoML is a very active research field, see www.automl.org
Neural Architecture Search [Zoph and Le, 2017 and many]](https://image.slidesharecdn.com/gaohuang-190826085652/75/Architecture-Design-for-Deep-Neural-Networks-I-18-2048.jpg)

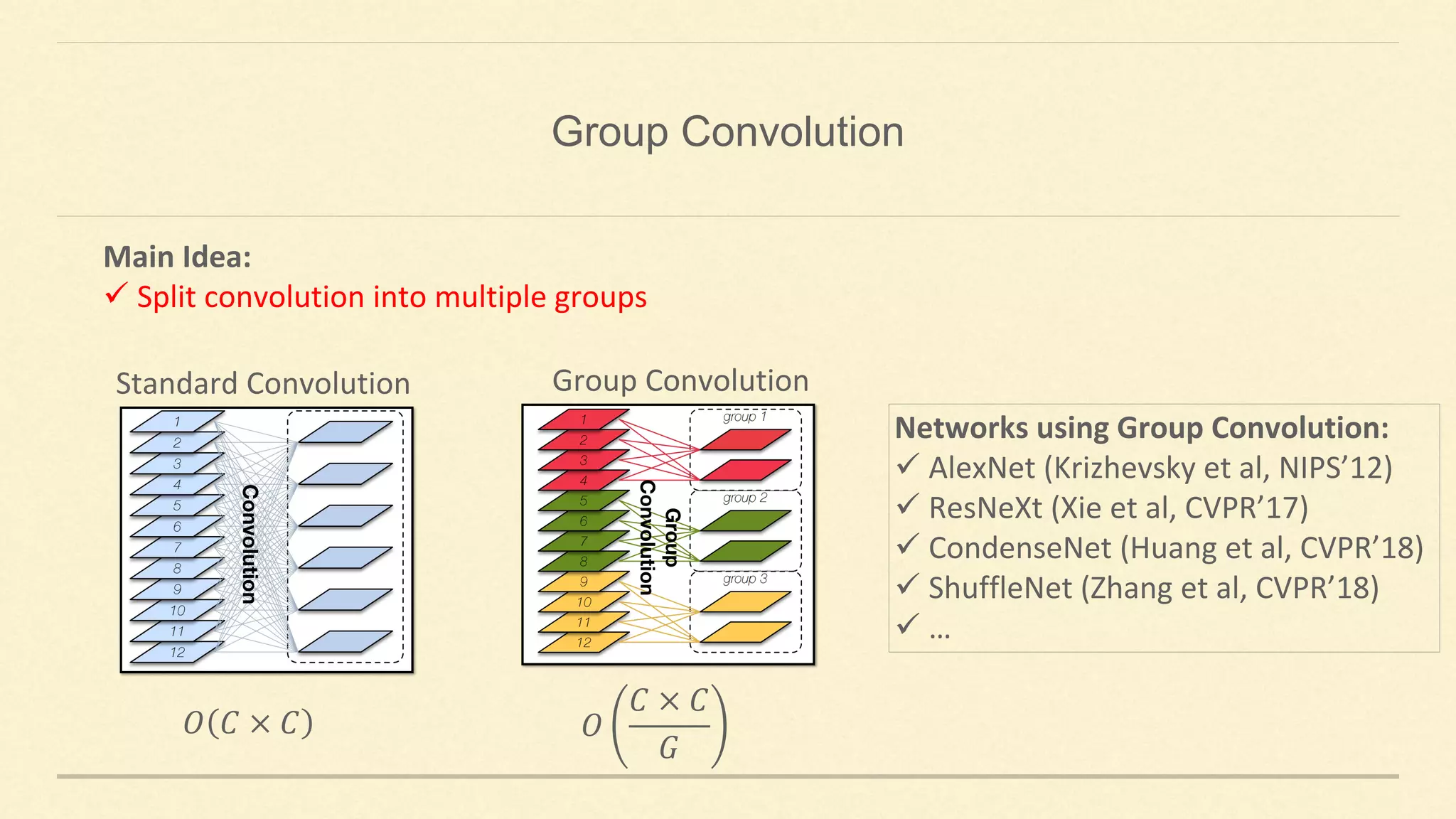
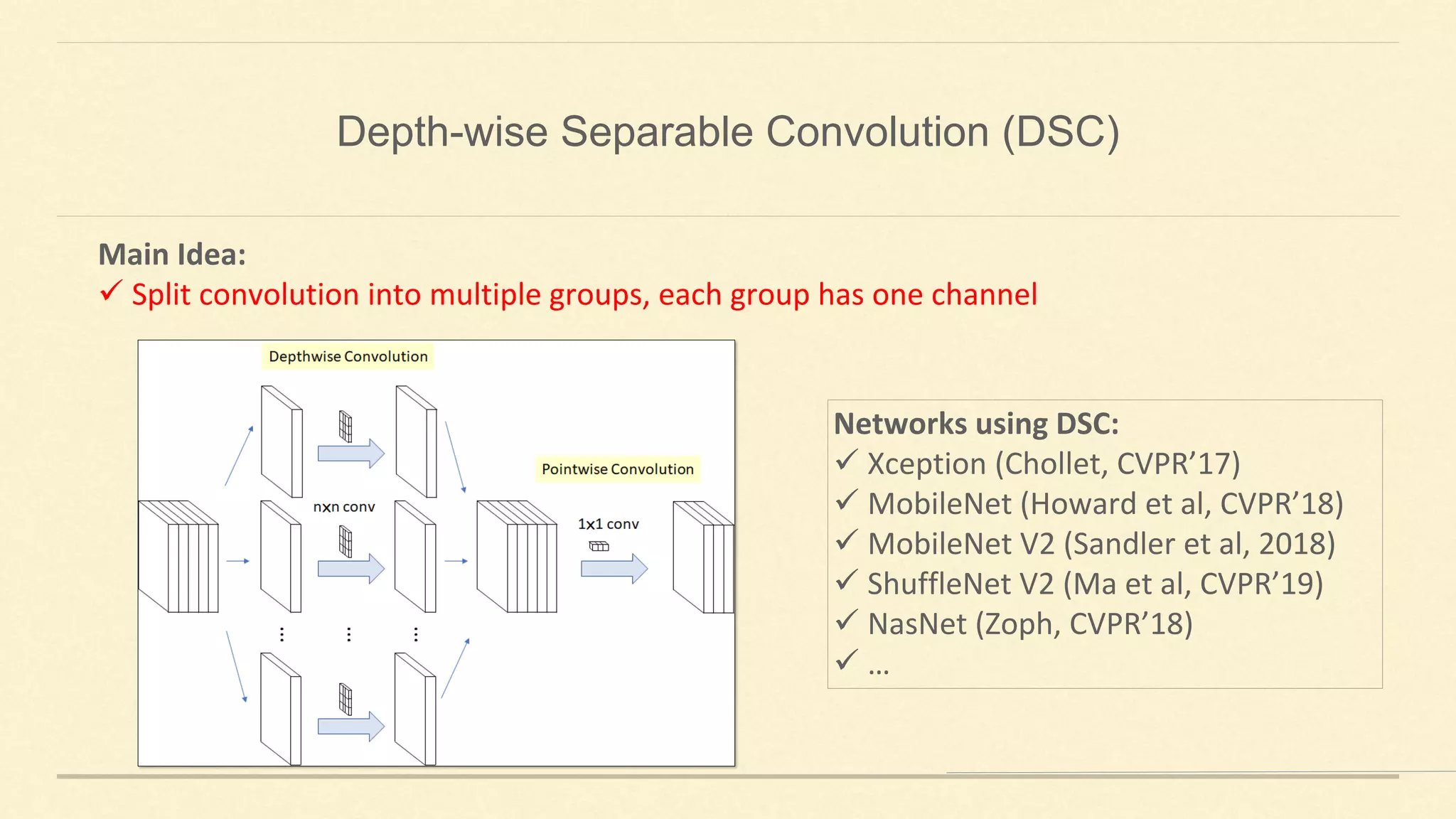
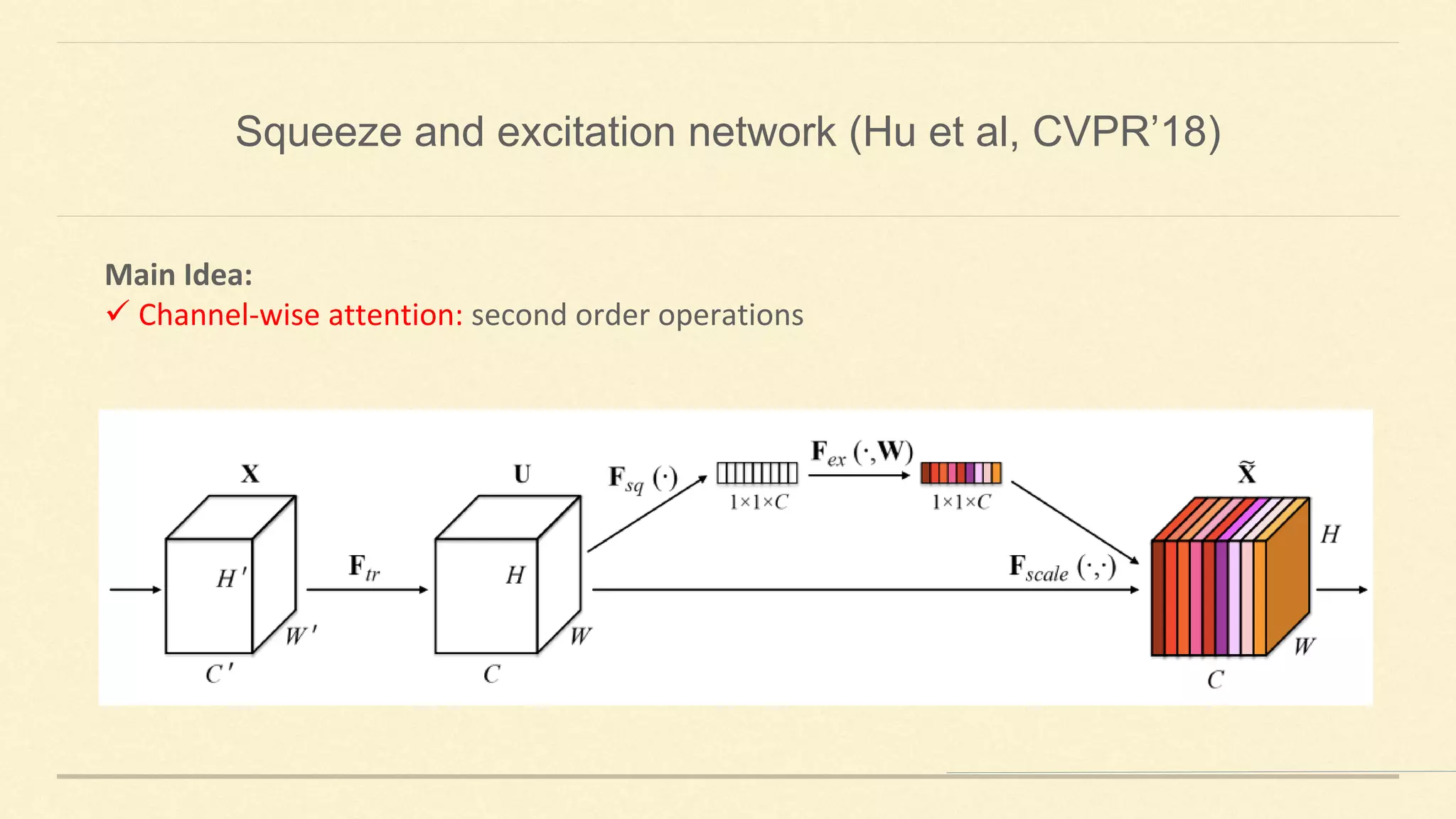
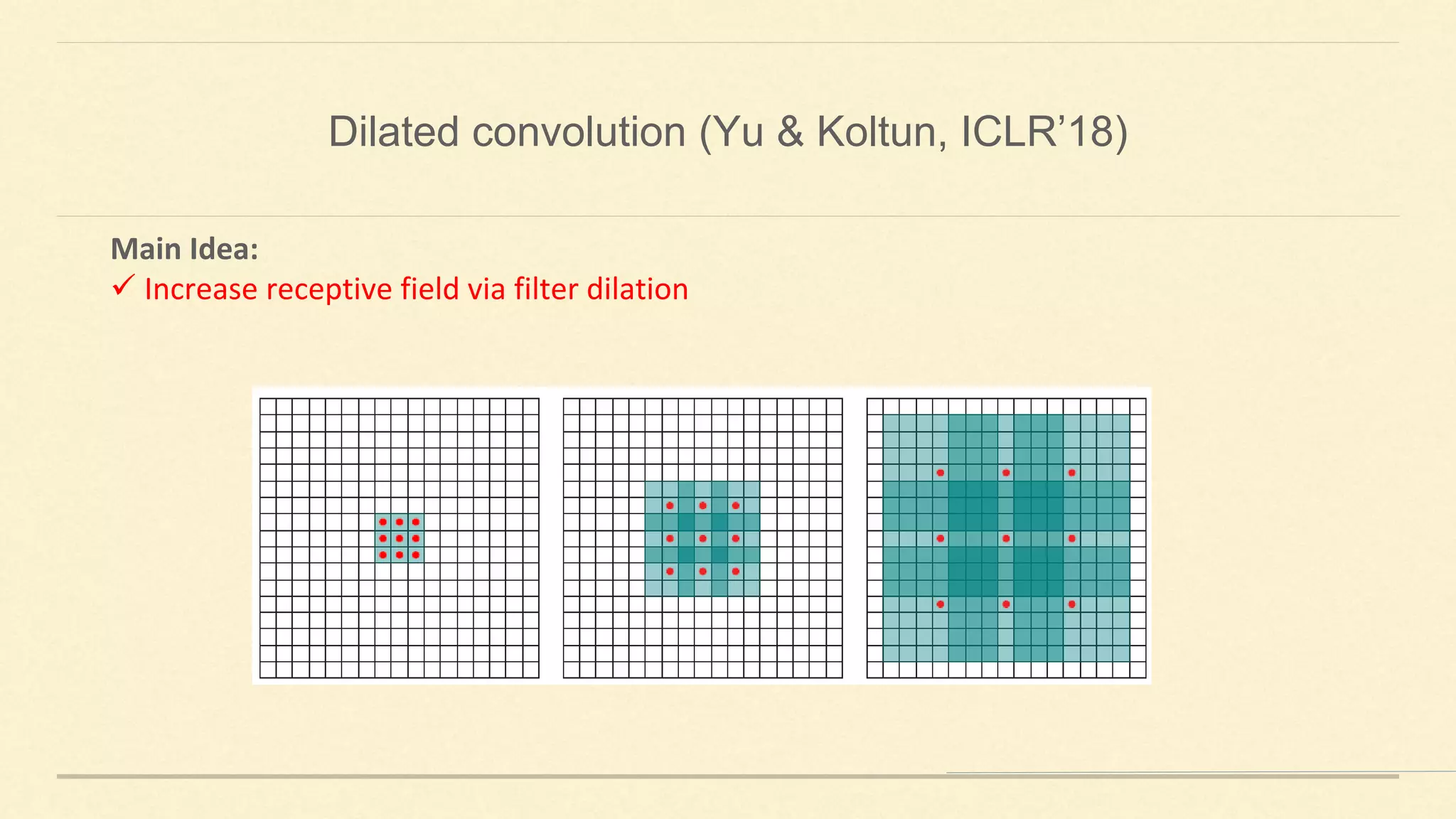
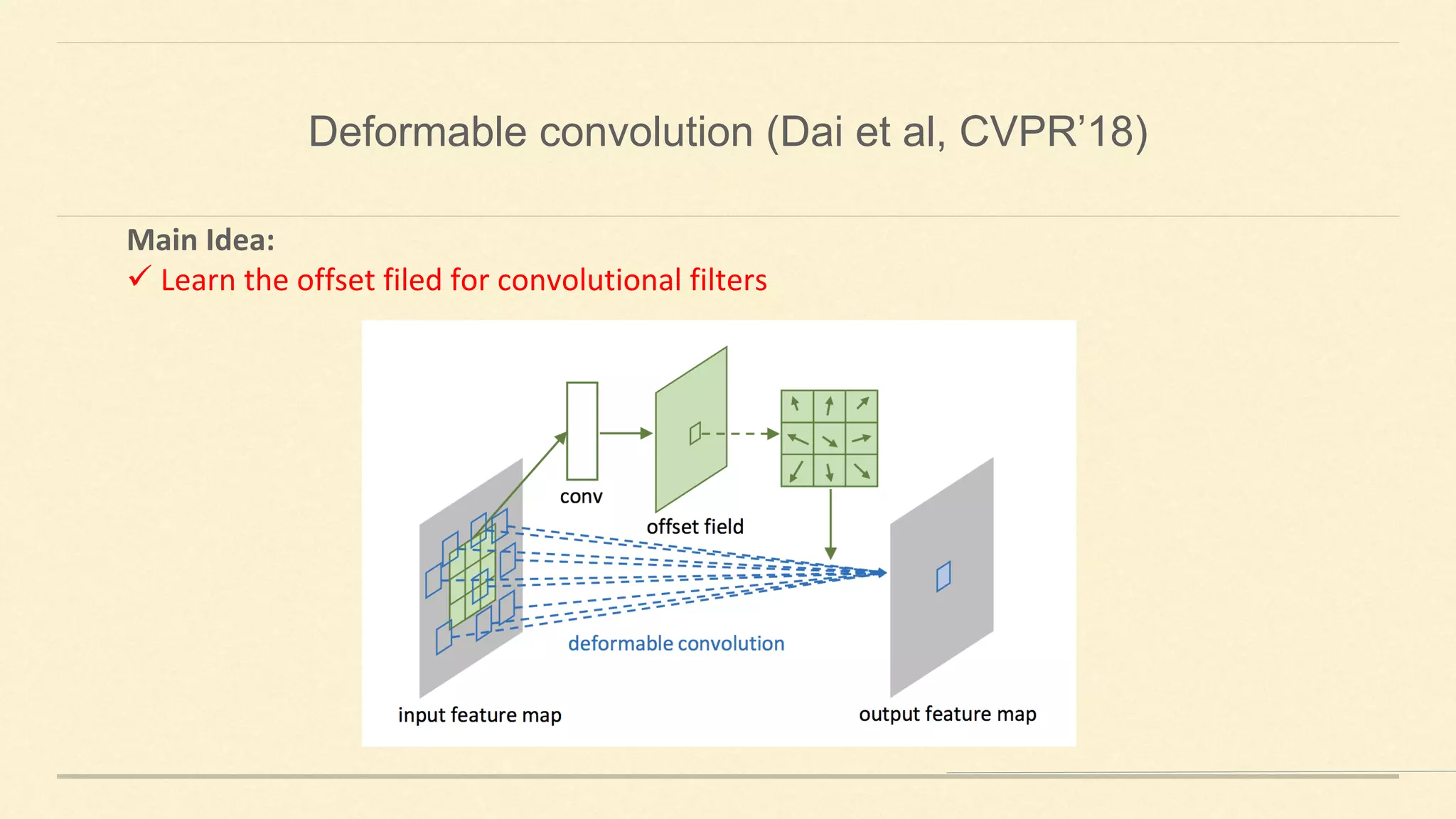

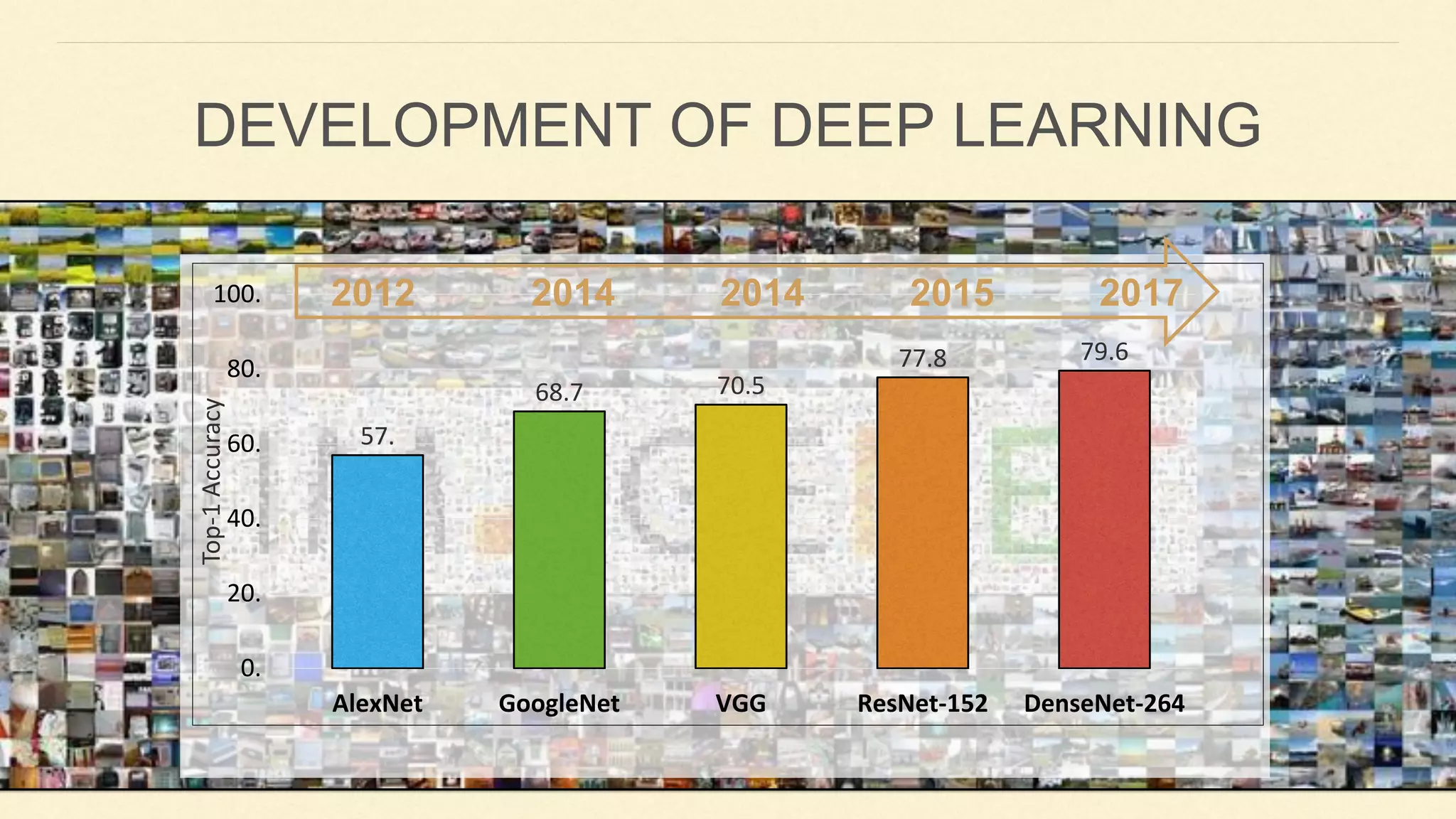
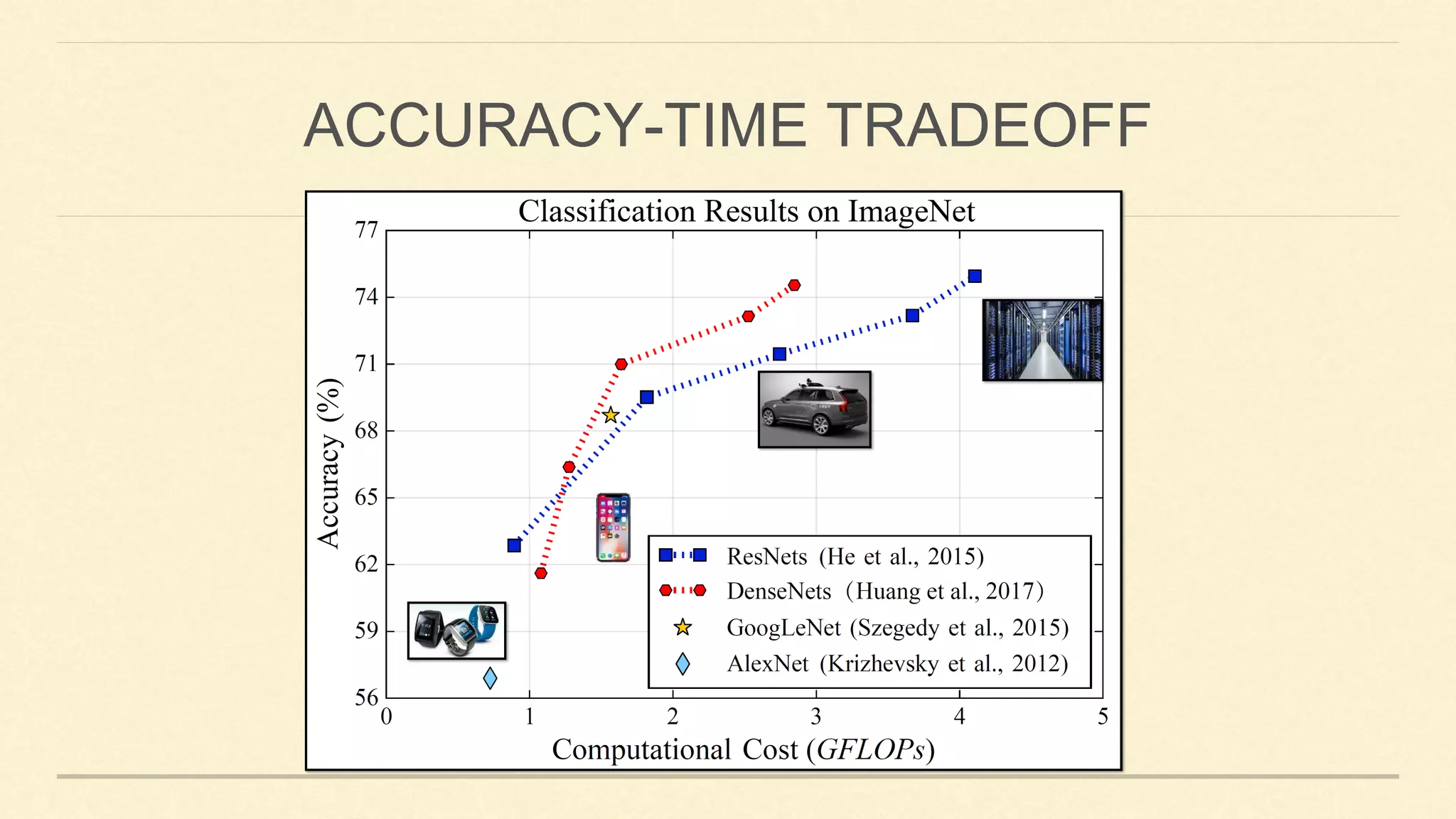




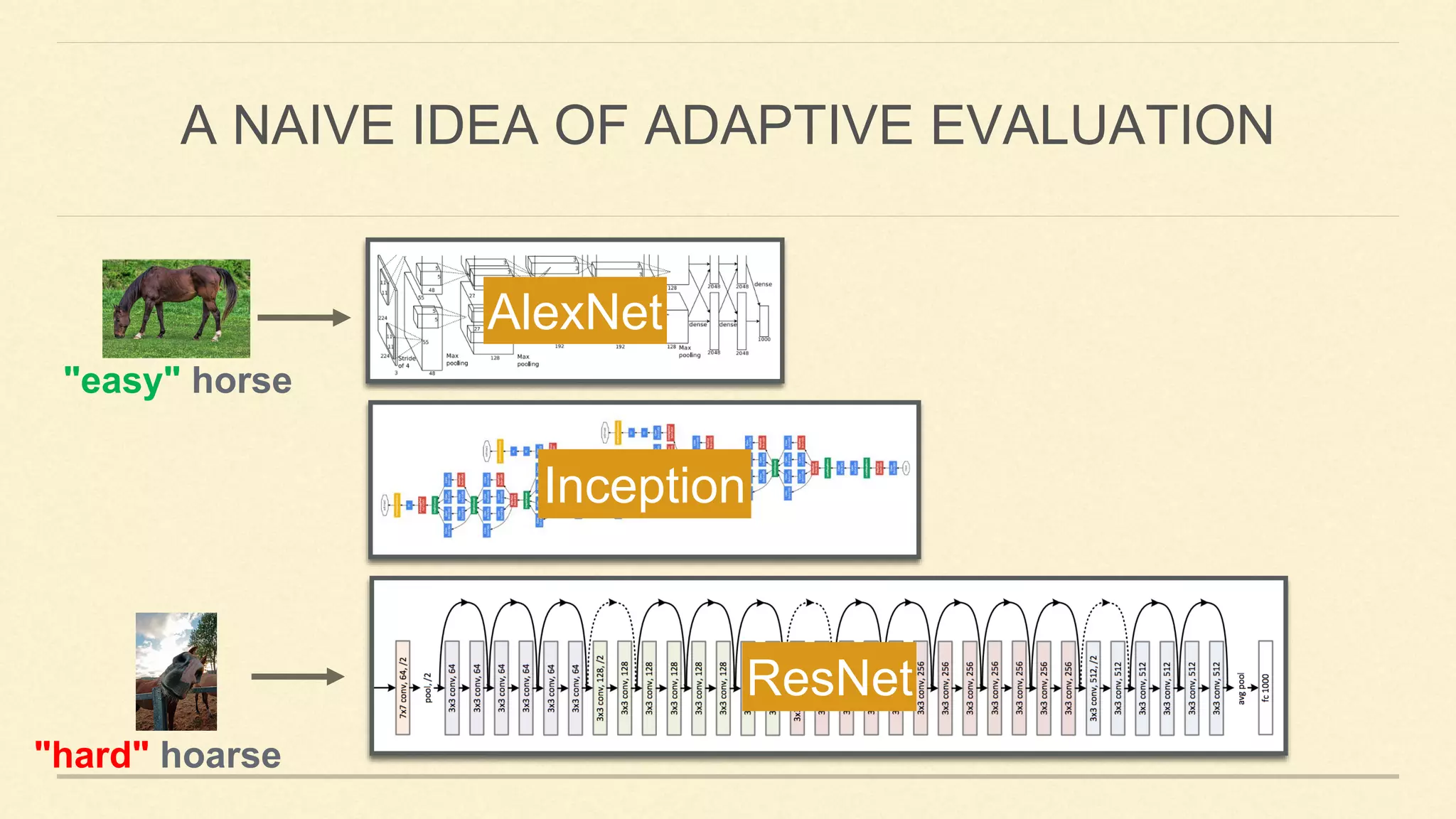
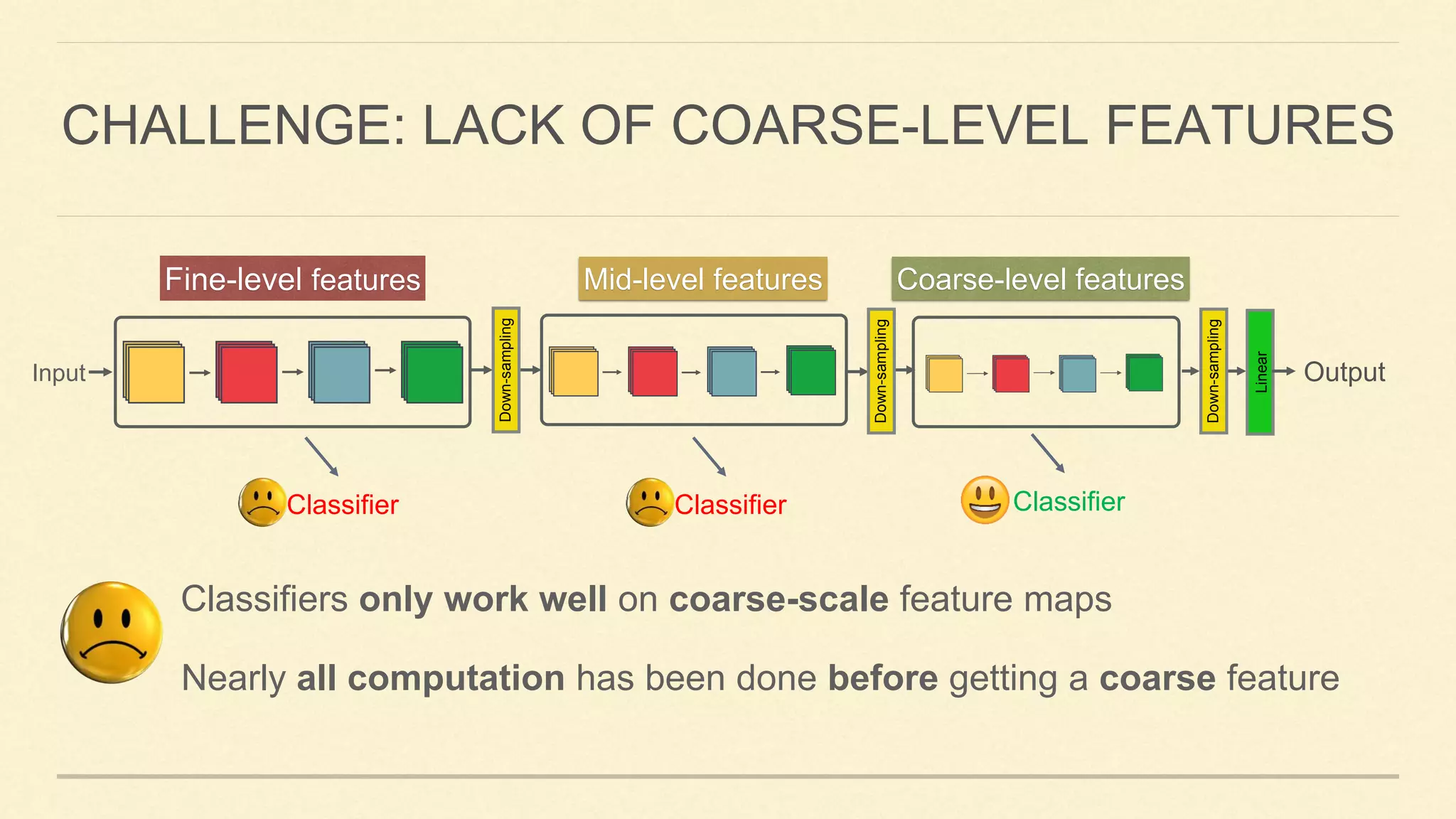
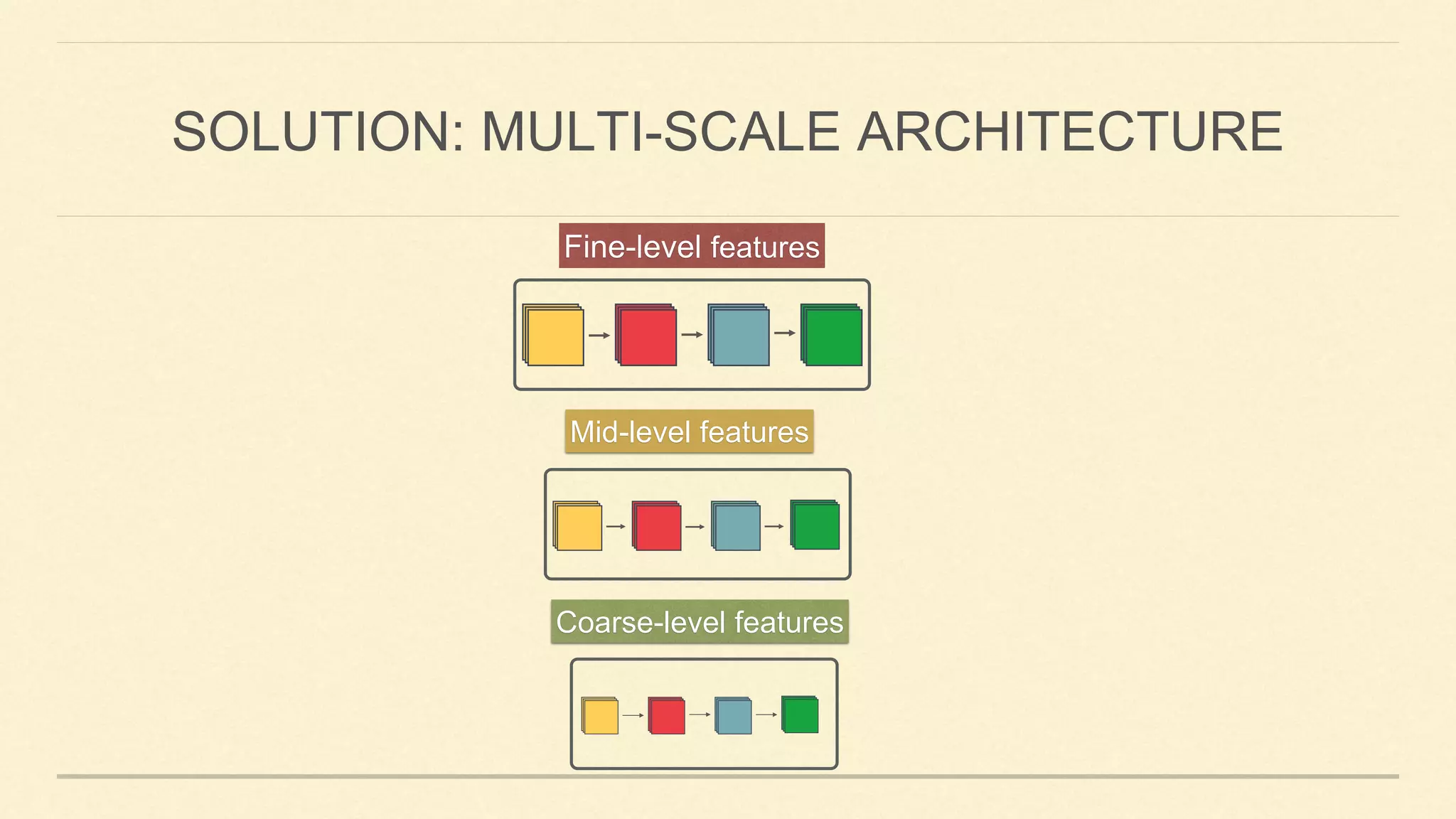
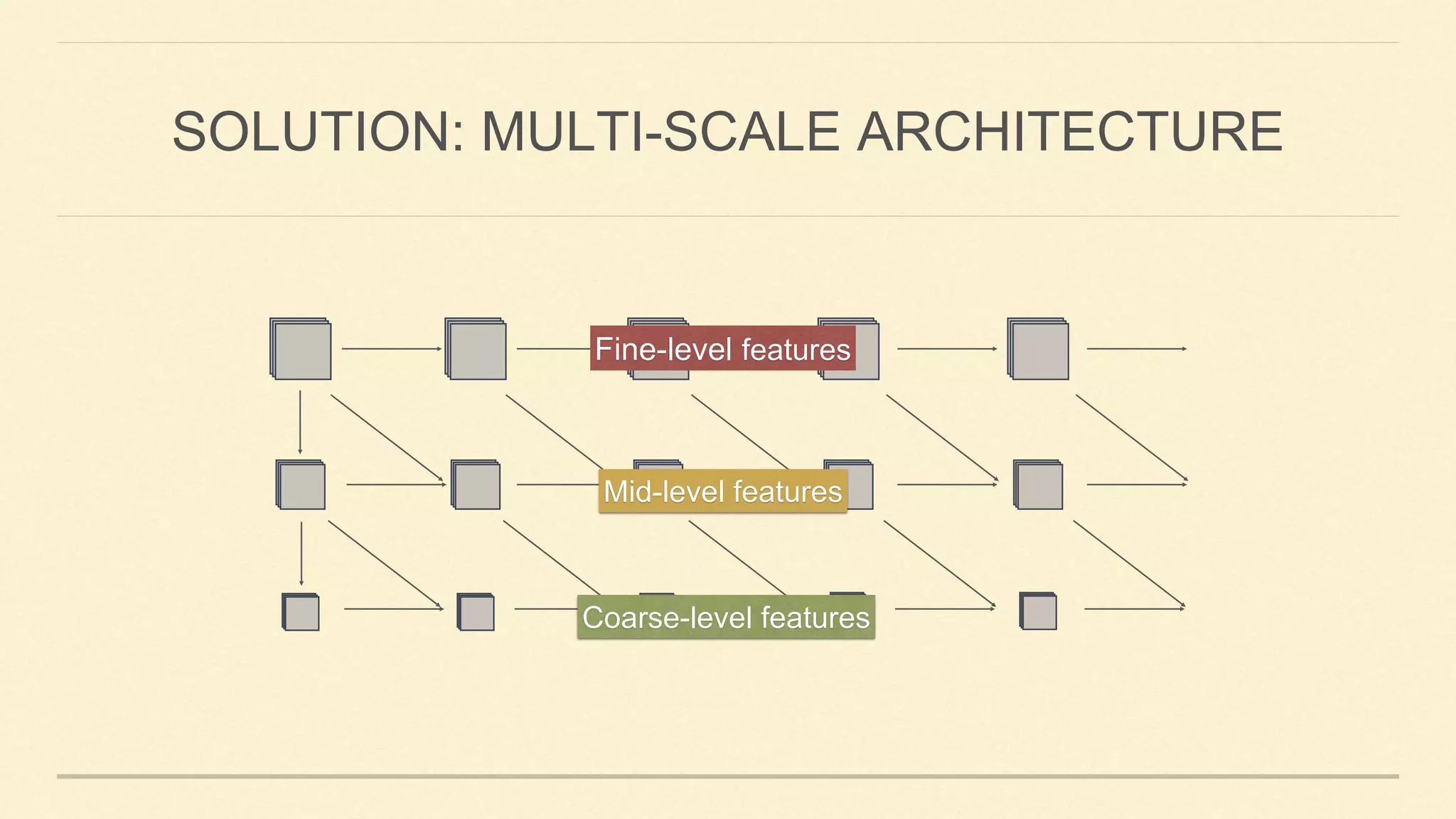
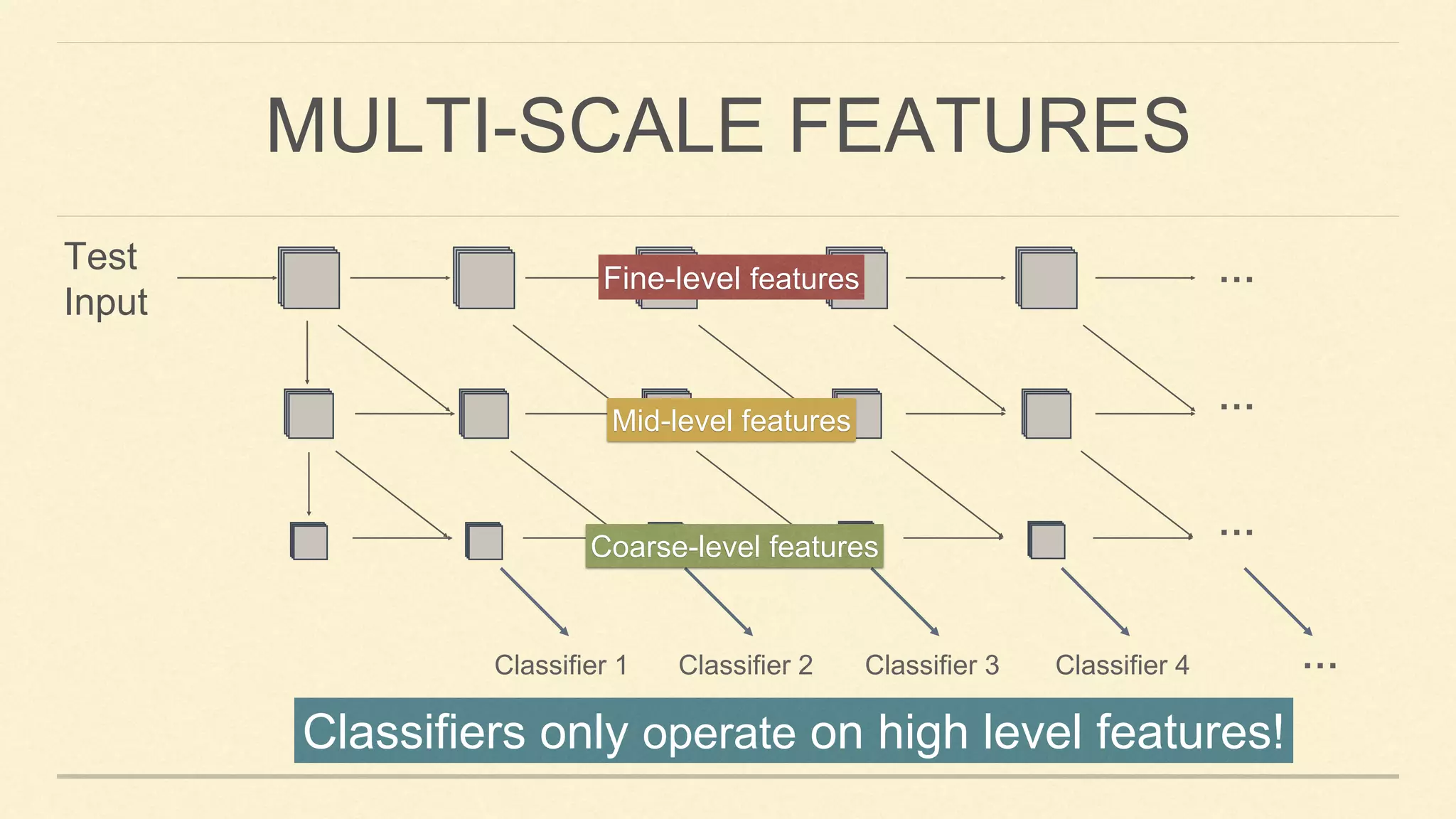
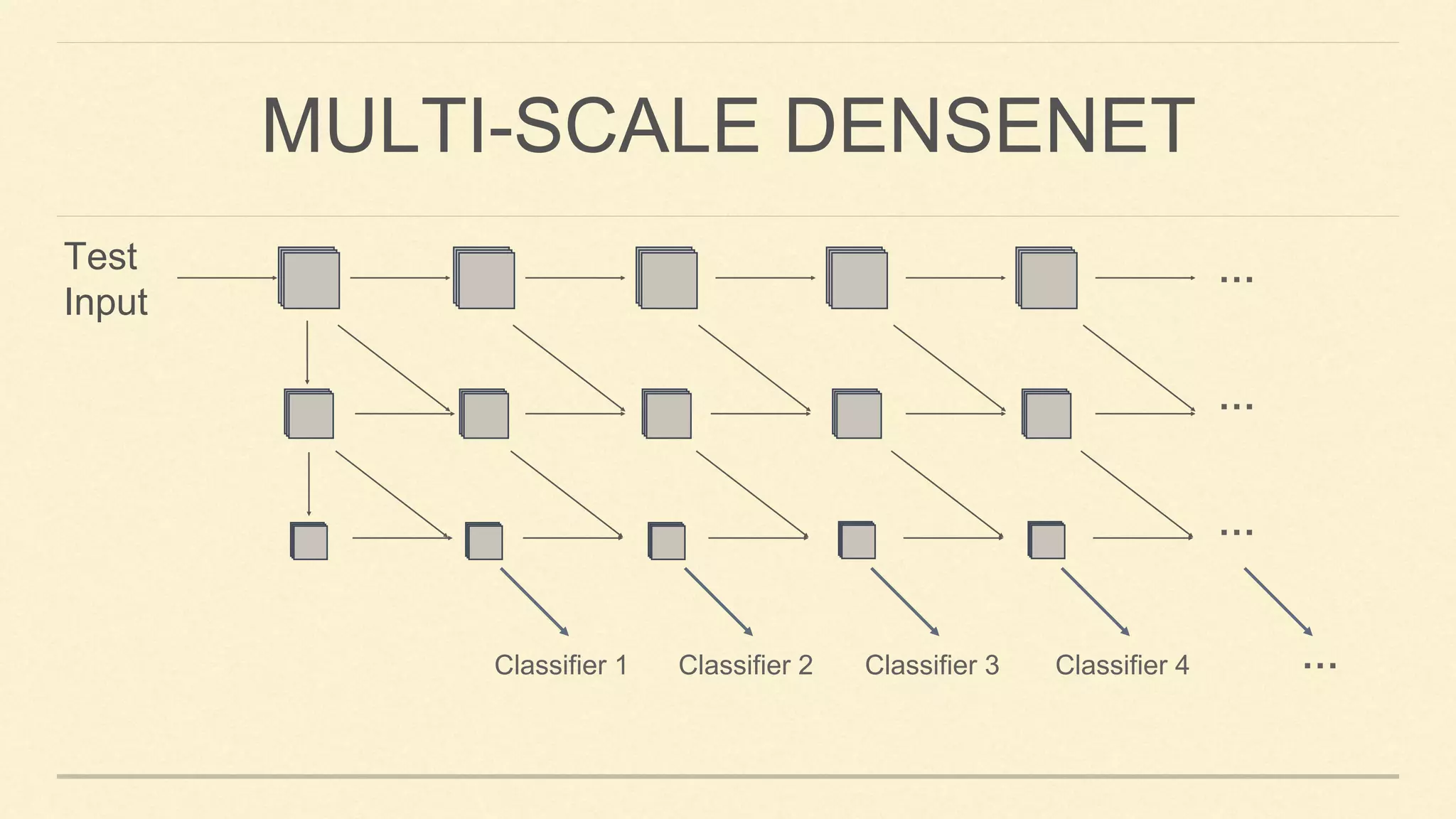

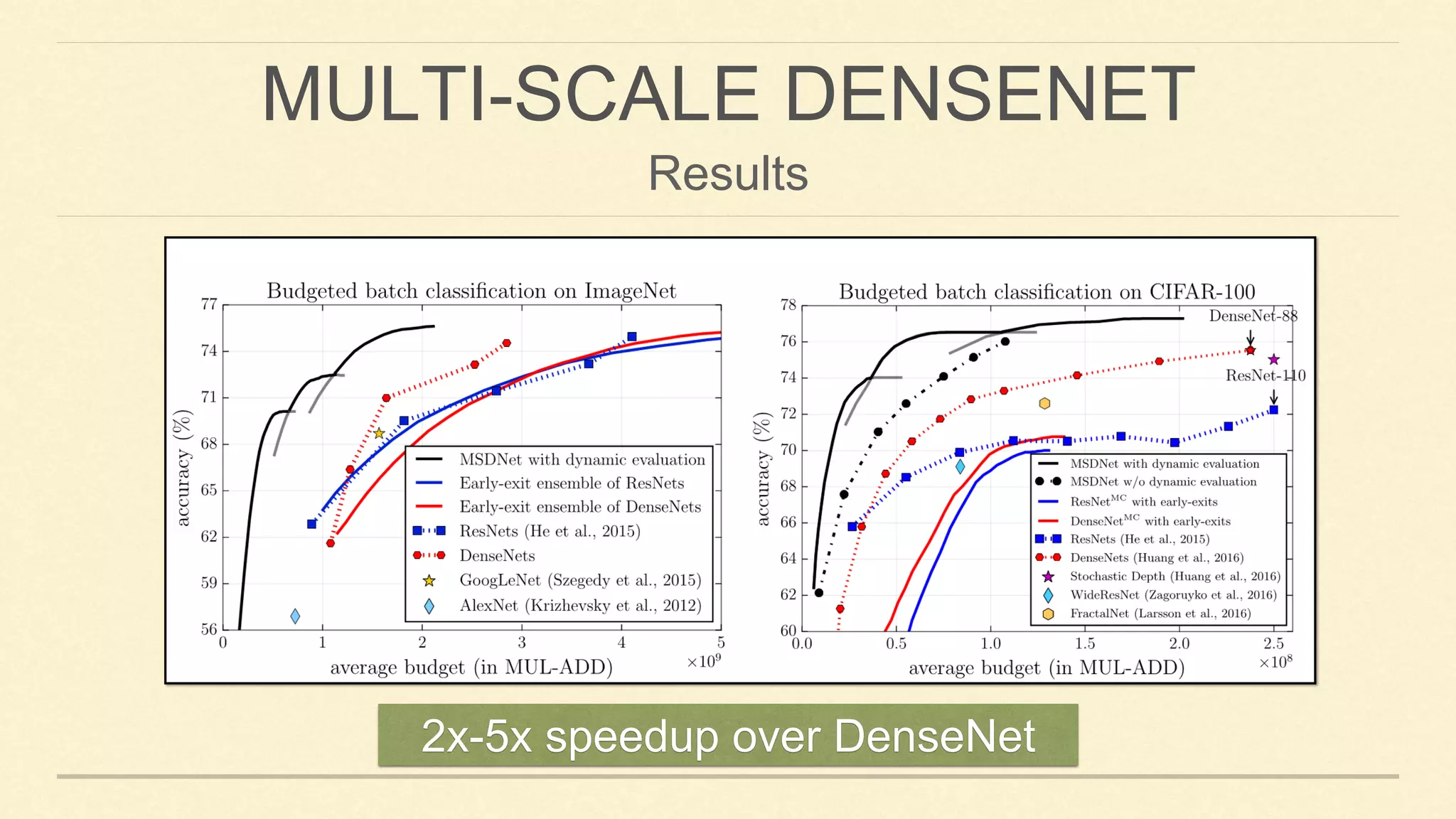
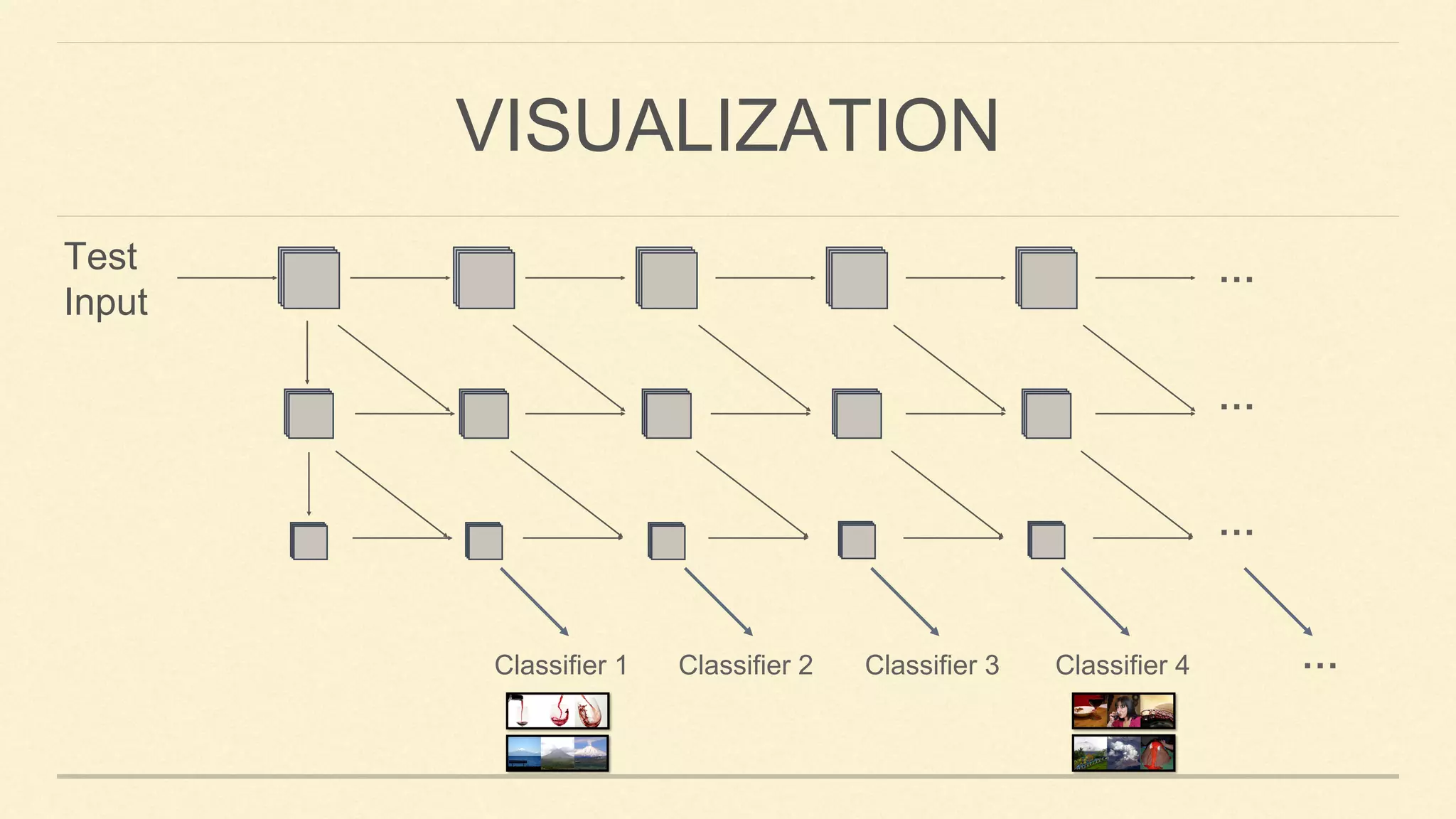





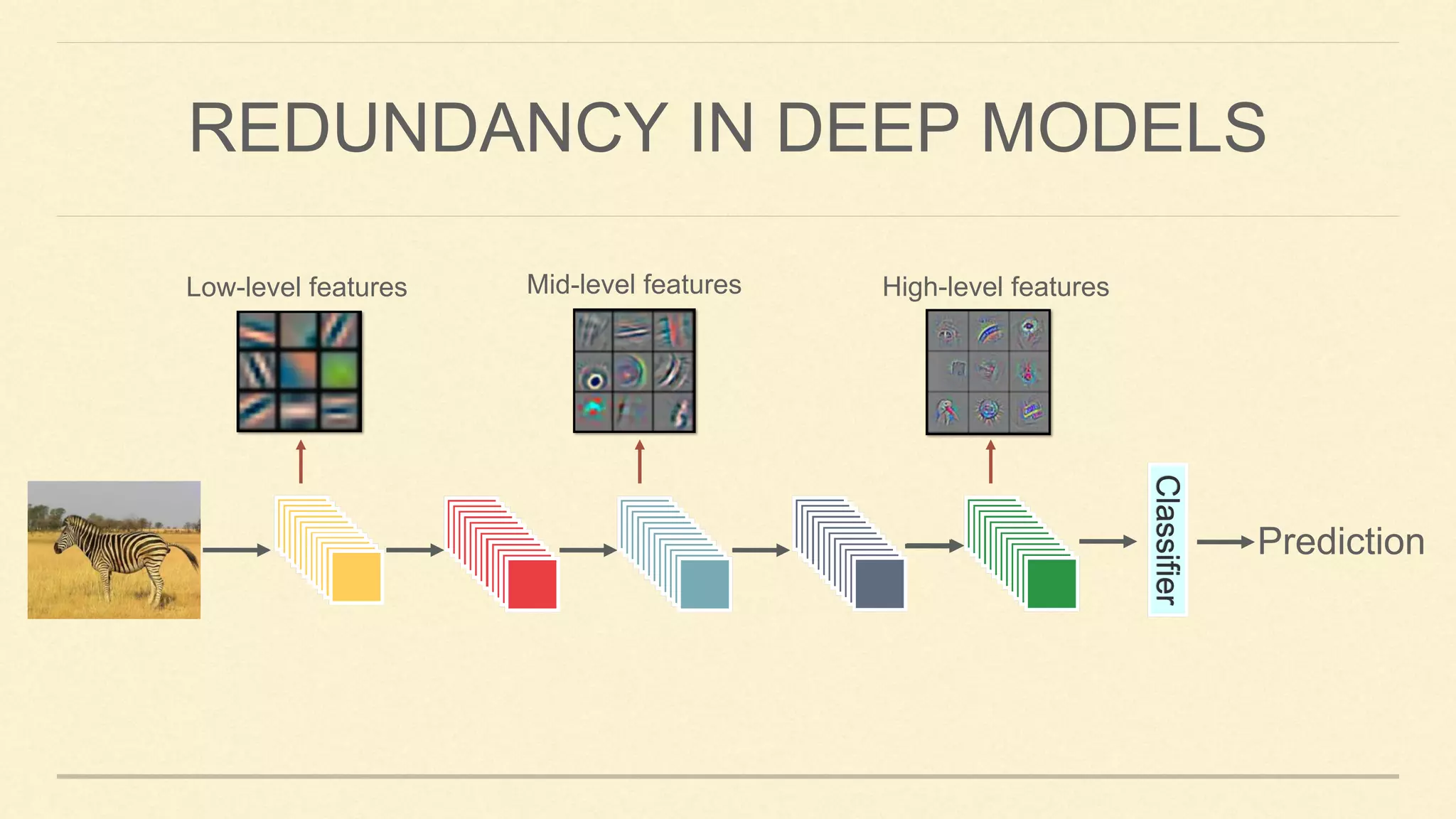
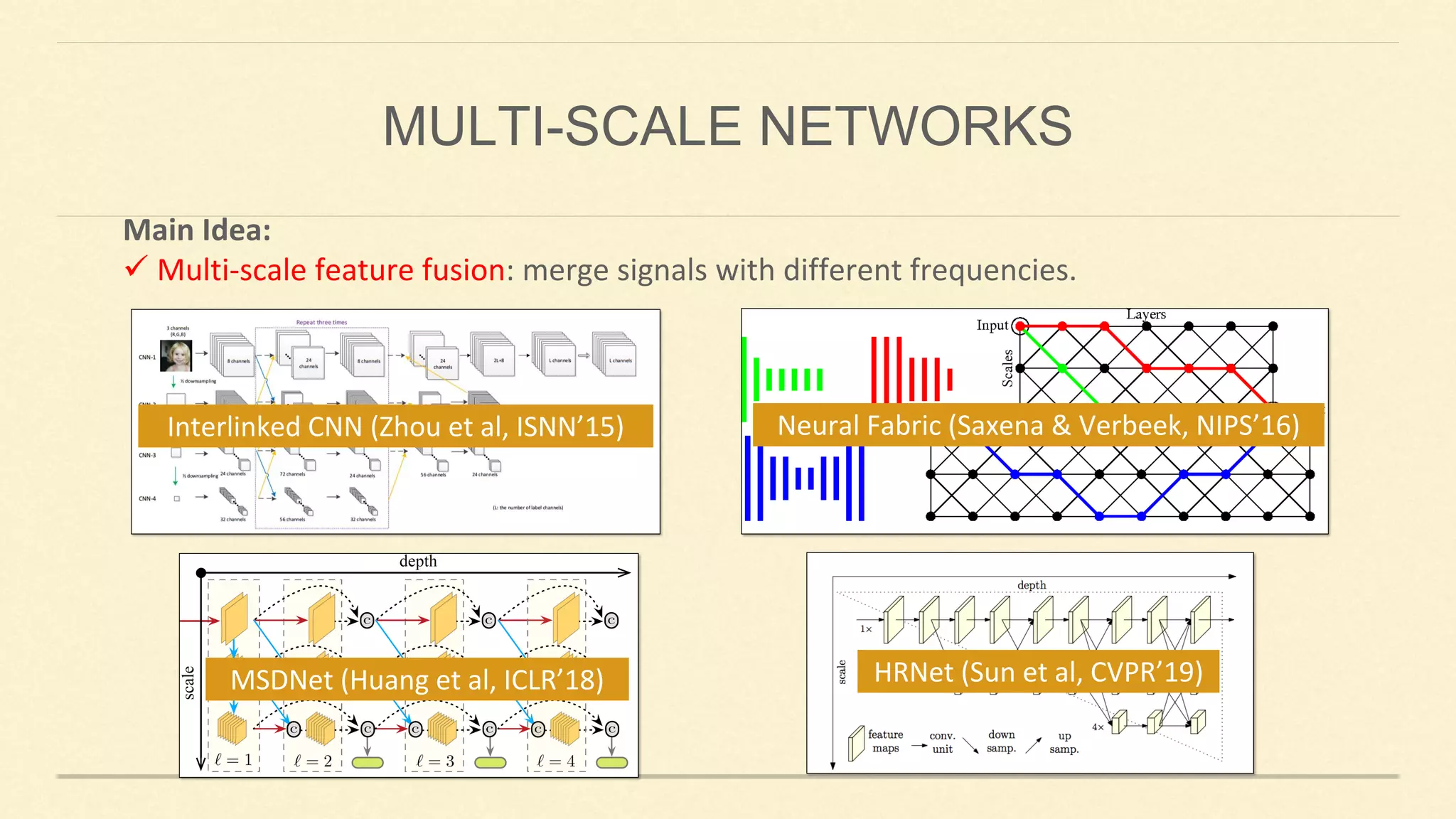
This document summarizes Gao Huang's presentation on neural architectures for efficient inference. The presentation covered three parts: 1) macro-architecture innovations in convolutional neural networks (CNNs) such as ResNet, DenseNet, and multi-scale networks; 2) micro-architecture innovations including group convolution, depthwise separable convolution, and attention mechanisms; and 3) moving from static networks to dynamic networks that can adaptively select simpler or more complex models based on input complexity. The key idea is to enable faster yet accurate inference by matching computational cost to input difficulty.






![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)











![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)












































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)












