Downloaded 38 times







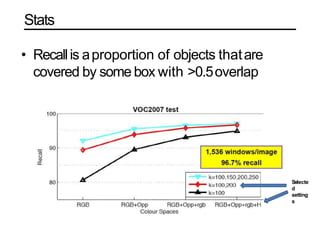








![Anchors - Example
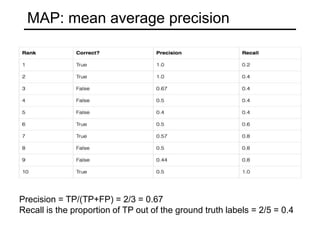
• Anchor dims=(size*scale)/sqrt(ratio)
• Eg for 32 anchor size:
• [-22 -11 22 11] 44X22 [-28 -14 28 14] 56X28 [-35 -17 35 17] 70X34
• [-16 -16 16 16] 32X32 [-20 -20 20 20] 40X40 [-25 -25 25 25] 50X50
• [-11 -22 11 22] 22X44 [-14 -28 14 28] 28X56 [-17 -35 17 35] 34X70
For 800,600 input image:
• P3 activation map shape: 100,75
• Stride: 8
• Total (A) = 9 anchors per pixel location
• Total anchors at P3 level = 100*75*9
= 67500
• Similarly sum for all pyramid levels
P3,P4,P5,P6,P7 = total 90360! anchors per
image](https://image.slidesharecdn.com/objectdetection-190825033952/85/Object-detection-RCNNs-vs-Retinanet-36-320.jpg)
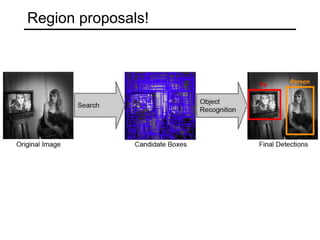
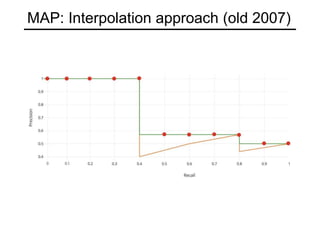
![Shift anchors
Shift anchors according to input image from activation map
(26,15)
(-22,-11)
(22,11)
(-18,-7)
(0,0)
(4,4)
Shift anchor centered at (0,0) on P3 (stride 8)
Activation map by [ 4. 4. 4. 4.]
Next shift [ 12. 4. 12. 4.], [ 20. 4. 20. 4.] , ….
(4,4) (12,4)
8
Input Image
Anchors applied wrt to input image!](https://image.slidesharecdn.com/objectdetection-190825033952/85/Object-detection-RCNNs-vs-Retinanet-37-320.jpg)
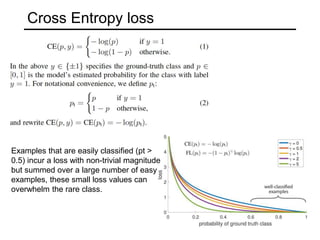
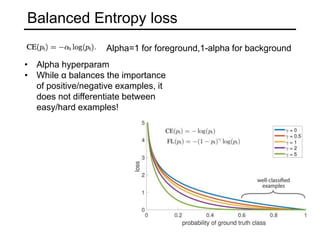
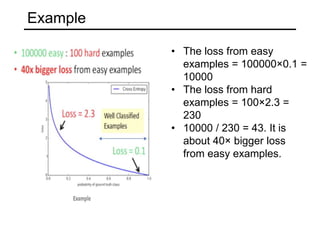
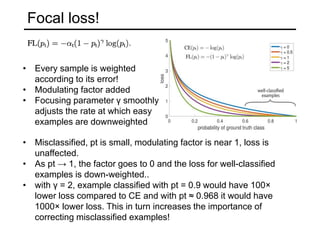
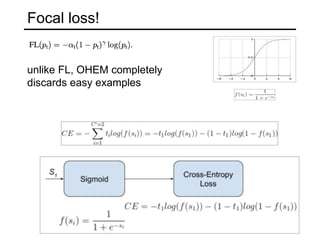
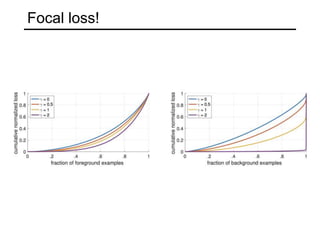
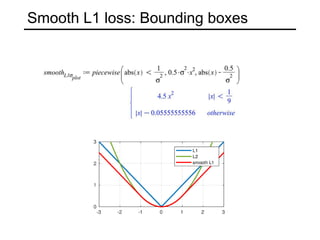

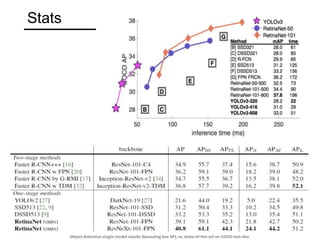



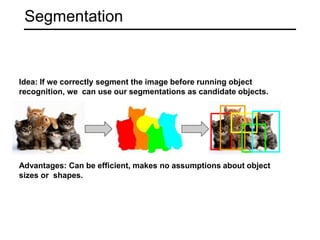
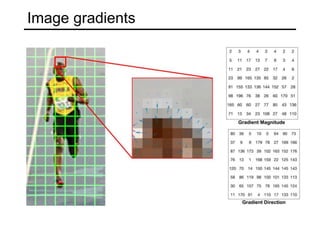
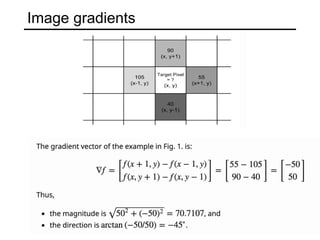
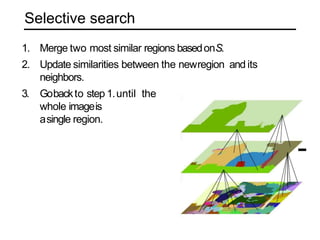
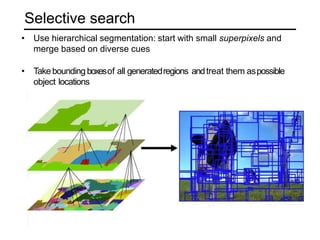
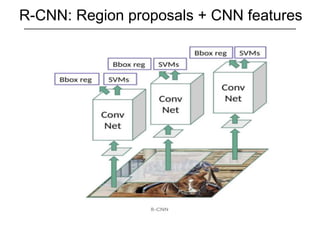
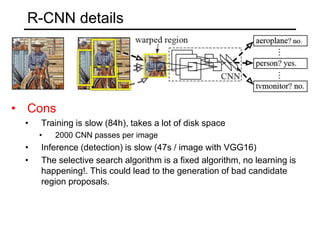
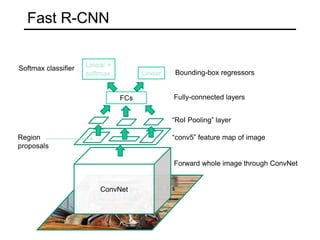
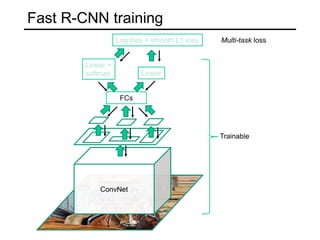
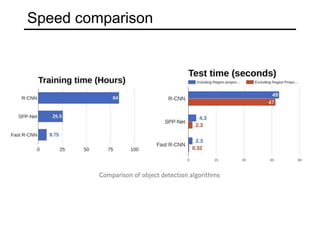
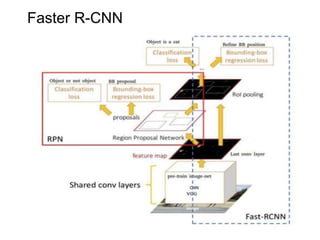
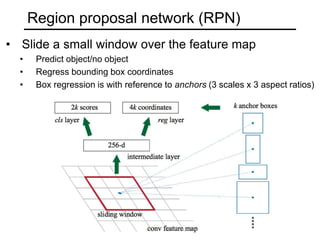
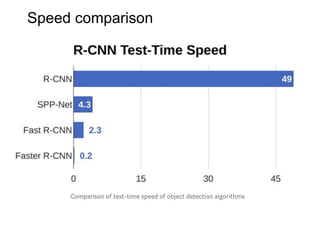
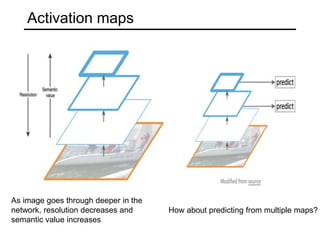
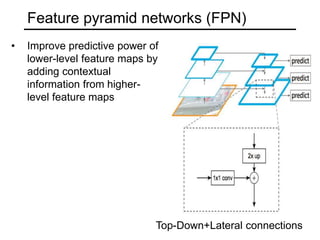
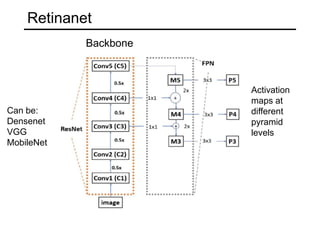
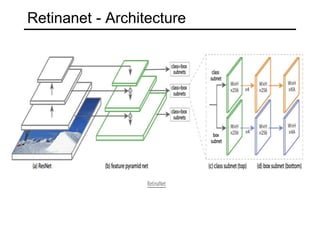
The document discusses various object detection methods, including selective search, R-CNN, and the Fast R-CNN approach, focusing on their advantages and disadvantages related to training time and proposal quality. It highlights the importance of region proposals and introduces the Faster R-CNN, which employs a Region Proposal Network (RPN) for improved proposal generation. Additionally, it covers advancements like Focal Loss and the use of Feature Pyramid Networks (FPN) to enhance detection accuracy across different scales and contexts.






















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












