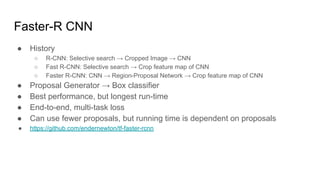
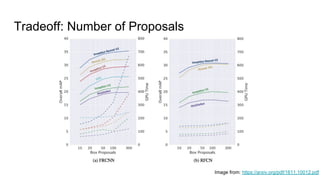
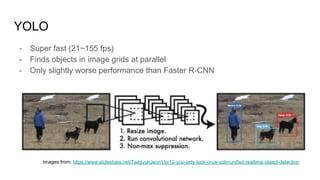
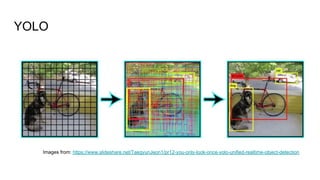
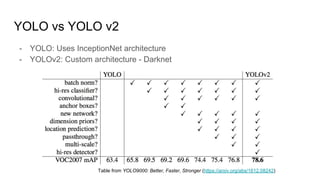
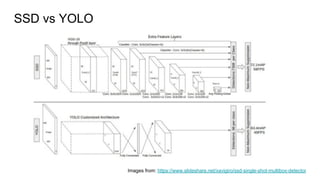
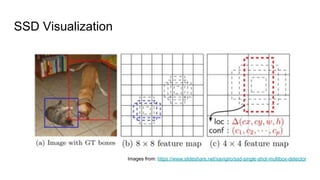
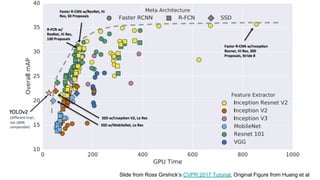
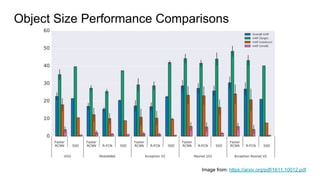
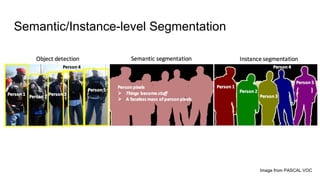
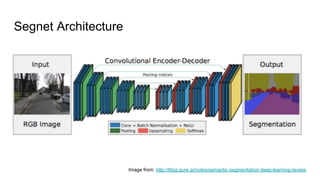
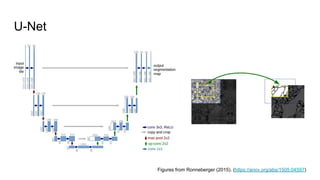
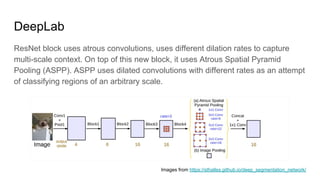
The document discusses various modern frameworks for object detection and segmentation, highlighting architectures such as Faster R-CNN, YOLO, and SSD, along with their respective advantages and limitations. It also addresses the importance of understanding trade-offs when choosing frameworks for specific tasks and mentions the significance of modular frameworks in image processing. Additionally, it provides links to open-source implementations and further reading materials on the subject.