Download as KEY, PPTX






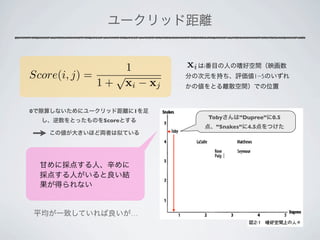
















This document discusses various methods for calculating similarity scores between data points, including collaborative filtering, cosine similarity, Euclidean distance, Jaccard similarity, and Tanimoto similarity. It also mentions using word segmentation tools like Mecab for text data preprocessing in Japanese.