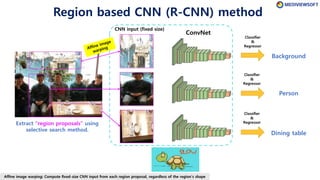
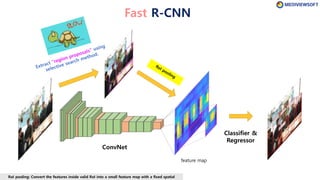
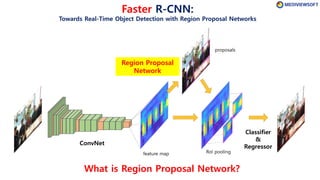
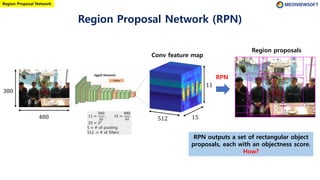
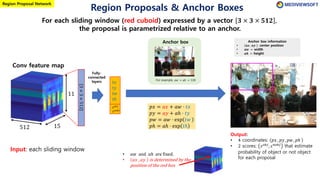
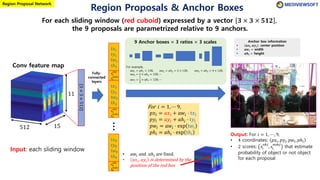
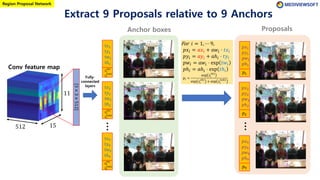
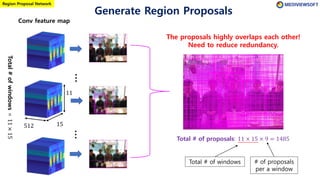
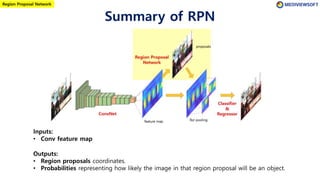
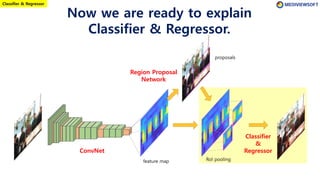
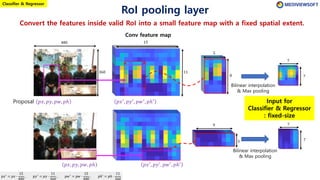
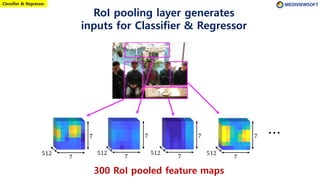
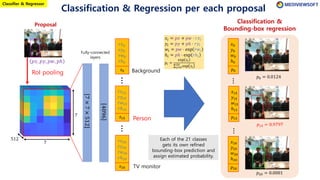
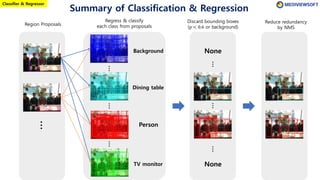
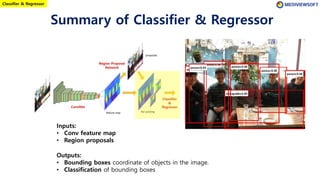
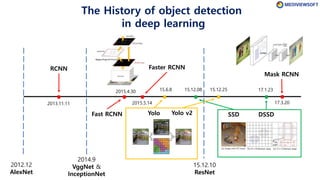
The document describes Faster R-CNN, an object detection method that uses a Region Proposal Network (RPN) to generate region proposals from feature maps, pools features from each proposal into a fixed size using RoI pooling, and then classifies and regresses bounding boxes for each proposal using a convolutional network. The RPN outputs objectness scores and bounding box adjustments for anchor boxes sliding over the feature map, and non-maximum suppression is applied to reduce redundant proposals.

![Dog
Cat
Person
⋮
pool5 features[224,224,3]
[7,7,512]
Input image
224
224
7 =
224
32
32 = 25
5 = # of pooling
7
7
Vgg16 Networks
Pooling
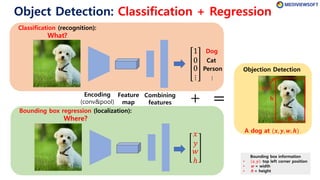
CNN-based Object Detection:
There are clues of dog (What) at local position (Where)
in the convolution feature map
Fully-connected
layers
Classification
Regression
𝑥
𝑦
𝑤
ℎ
1
0
0
⋮
These red boxes contains clues of “dog at the bounding box (𝑥, 𝑦, 𝑤, ℎ)”.
⋯ ⋯ Dog](https://image.slidesharecdn.com/winterschool2018-180123075434/85/Tutorial-on-Object-Detection-Faster-R-CNN-3-320.jpg)








![References
[Gitbooks] Object Localization and Detection
https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/object_localization_and_detection.html
[ICCV2015 Tutorial] Convolutional Feature Maps
https://courses.engr.illinois.edu/ece420/sp2017/iccv2015_tutorial_convolutional_feature_maps_kaiminghe.pdf
[Infographic] The Modern History of Object Recognition
https://github.com/Nikasa1889/HistoryObjectRecognition
[Tensorflow Code] tf-Faster-RCNN
https://github.com/kevinjliang/tf-Faster-RCNN
[Medium] A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
[pyimagesearch] Intersection over Union (IoU) for object detection
https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
[Stanford c231n] Lecture 11: Detection and Segmentation
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf](https://image.slidesharecdn.com/winterschool2018-180123075434/85/Tutorial-on-Object-Detection-Faster-R-CNN-29-320.jpg)




































































