Download as PDF, PPTX
![[course site]
Imagenet Large Scale
Visual Recognition
Challenge (ILSVRC)
Day 2 Lecture 4
Xavier Giró-i-Nieto](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-1-2048.jpg)
![2
ImageNet Dataset
Li Fei-Fei, “How we’re teaching computers to understand
pictures” TEDTalks 2014.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual
recognition challenge. arXiv preprint arXiv:1409.0575. [web]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-2-2048.jpg)
![3
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual
recognition challenge. arXiv preprint arXiv:1409.0575. [web]
ImageNet Dataset](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-3-2048.jpg)

![Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual
recognition challenge. arXiv preprint arXiv:1409.0575. [web]
● Top 5 error rate
ImageNet Challenge](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-5-2048.jpg)
![Slide credit:
Rob Fergus (NYU)
Image Classification 2012
-9.8%
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2014). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web] 6
Based on SIFT + Fisher Vectors
ImageNet Challenge](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-6-2048.jpg)
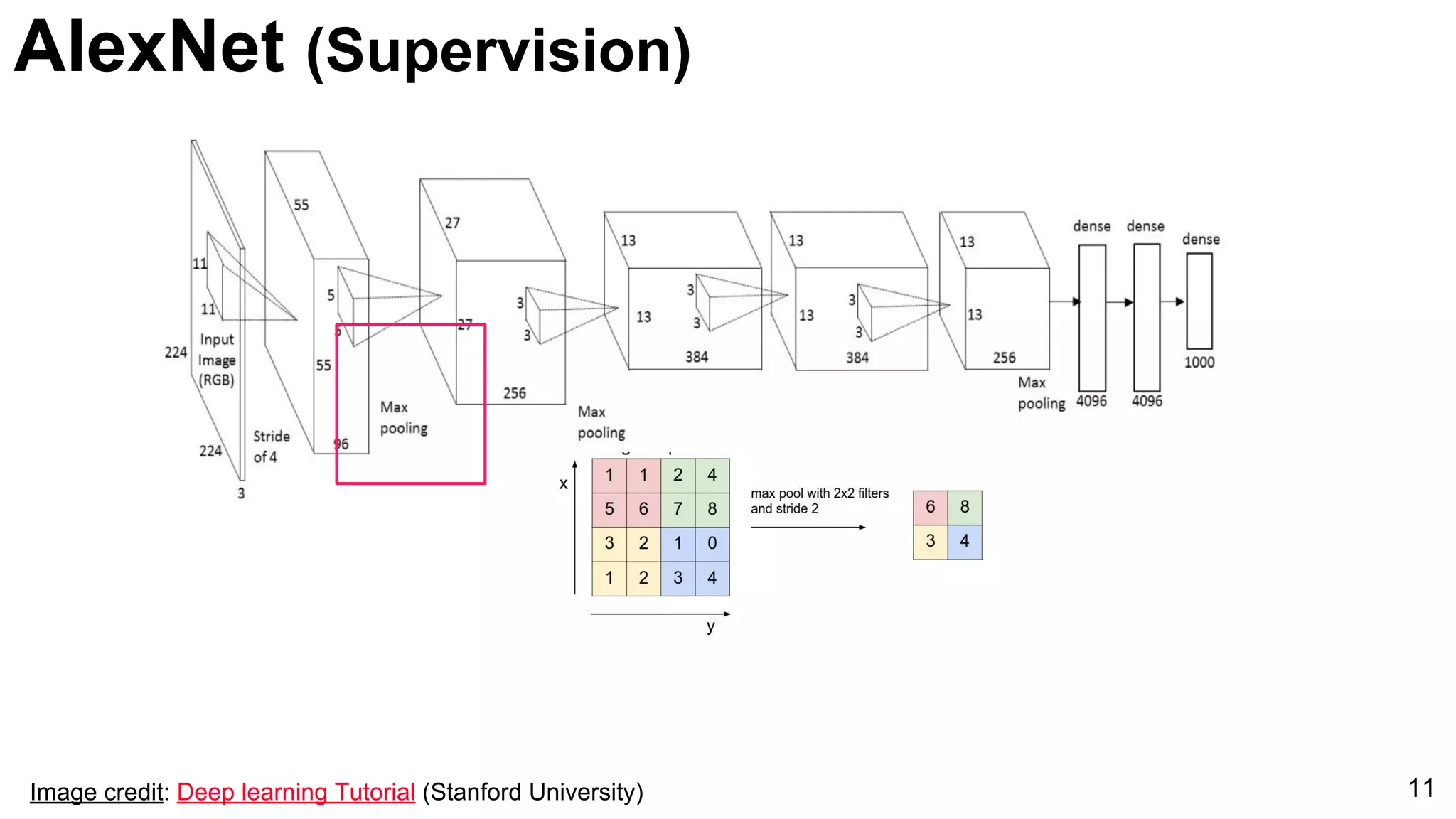
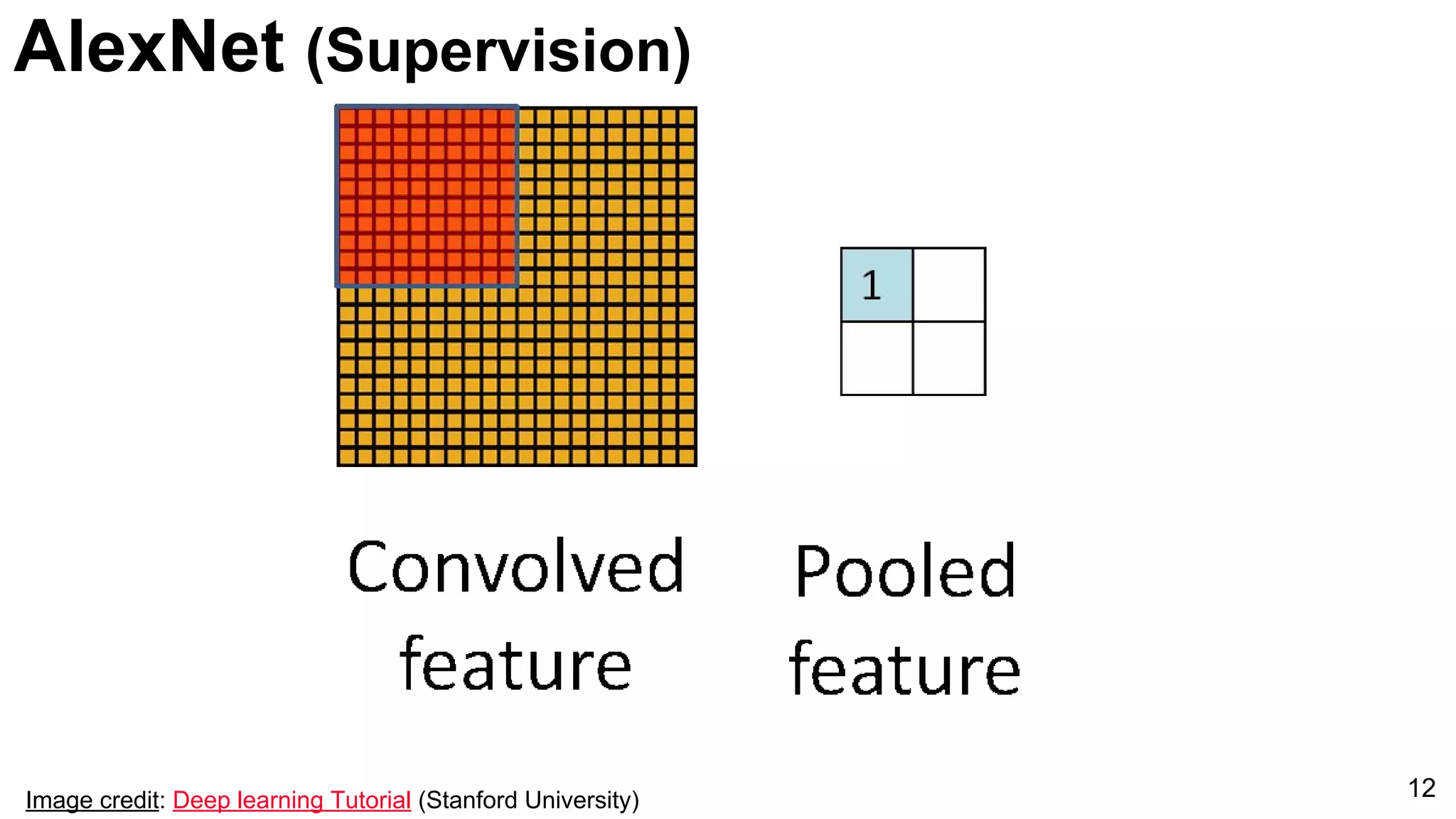
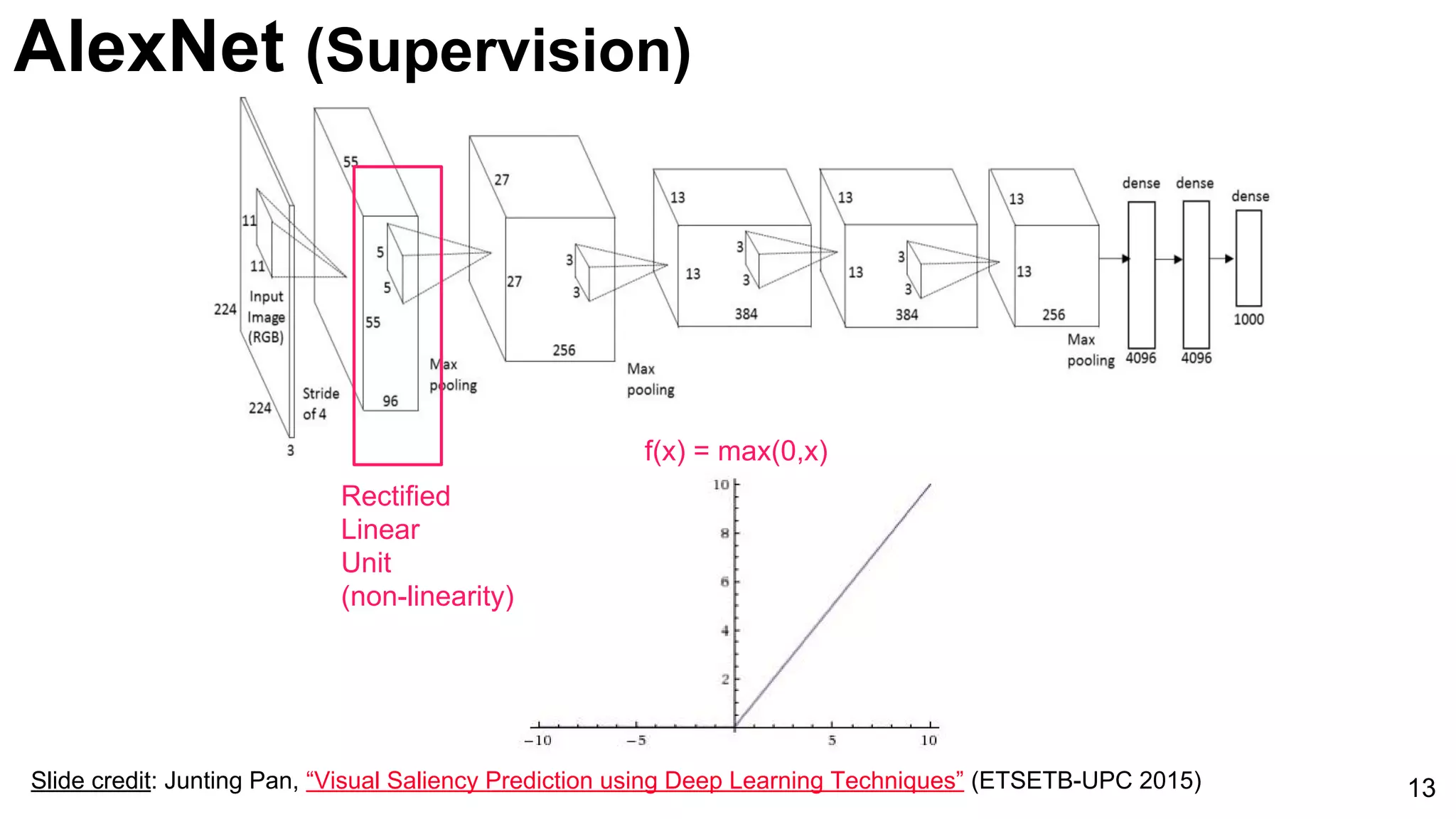
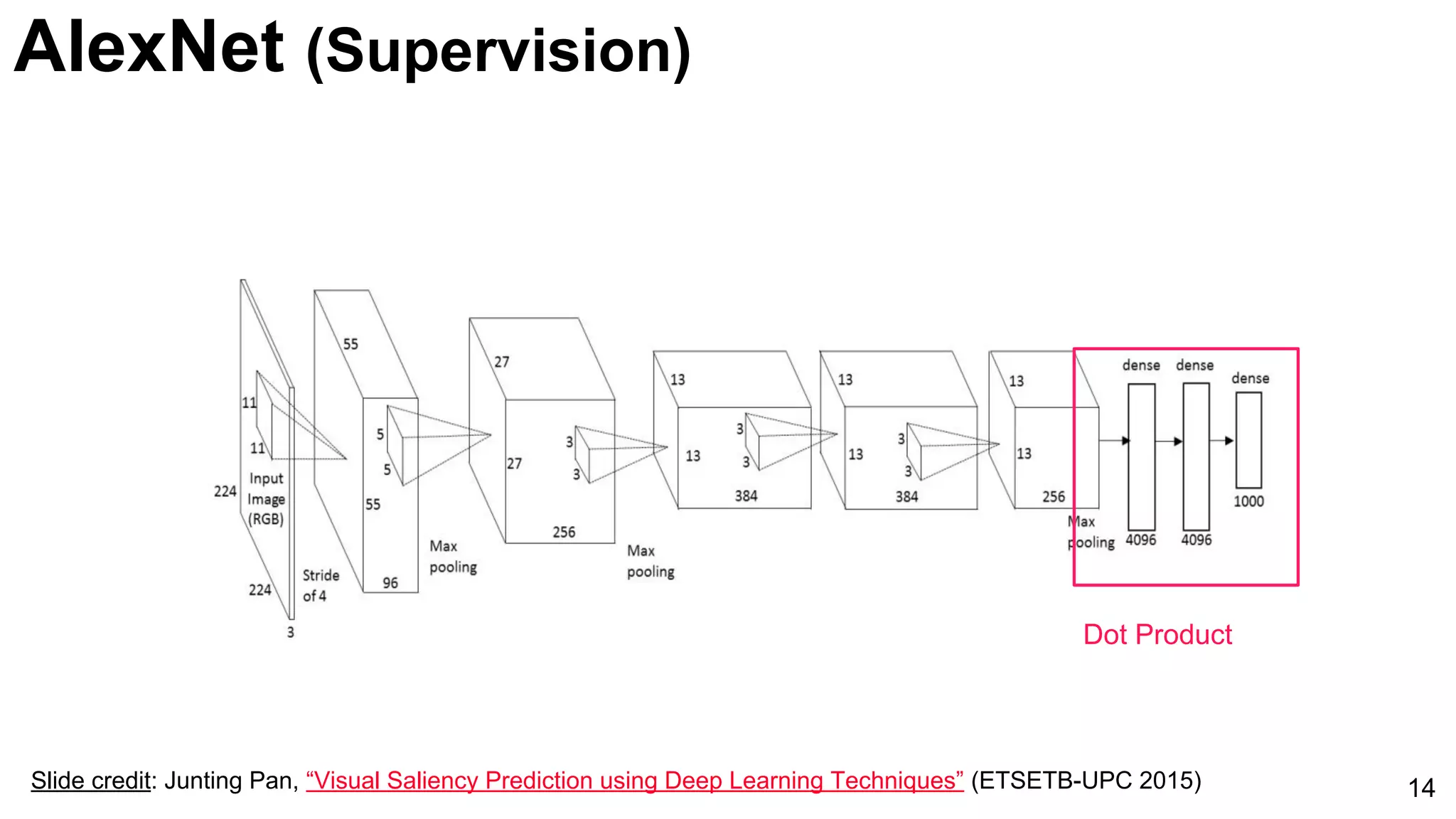
![ImageNet Classification 2013
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web]
Slide credit:
Rob Fergus (NYU)
15
ImageNet Challenge](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-15-2048.jpg)




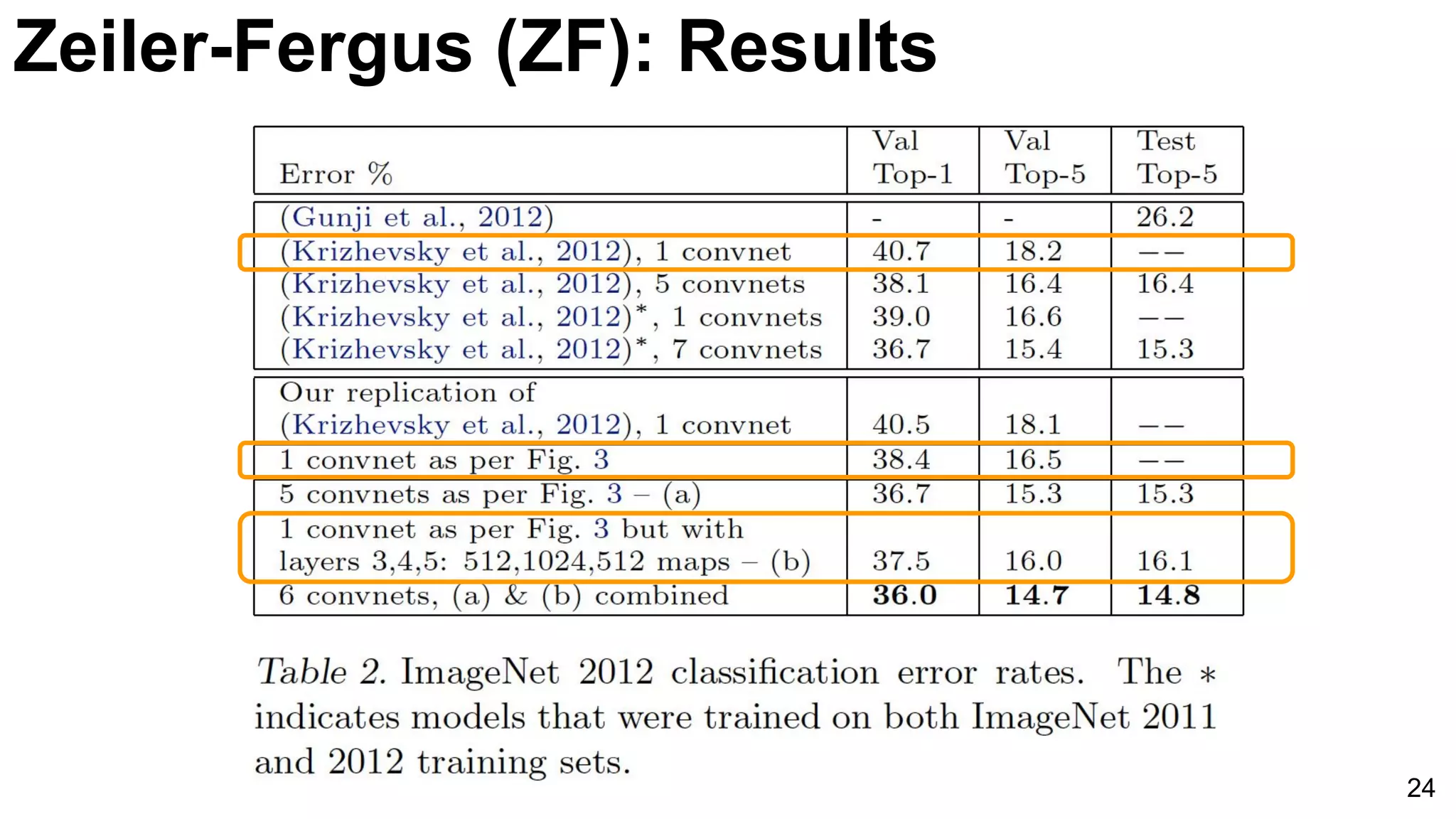
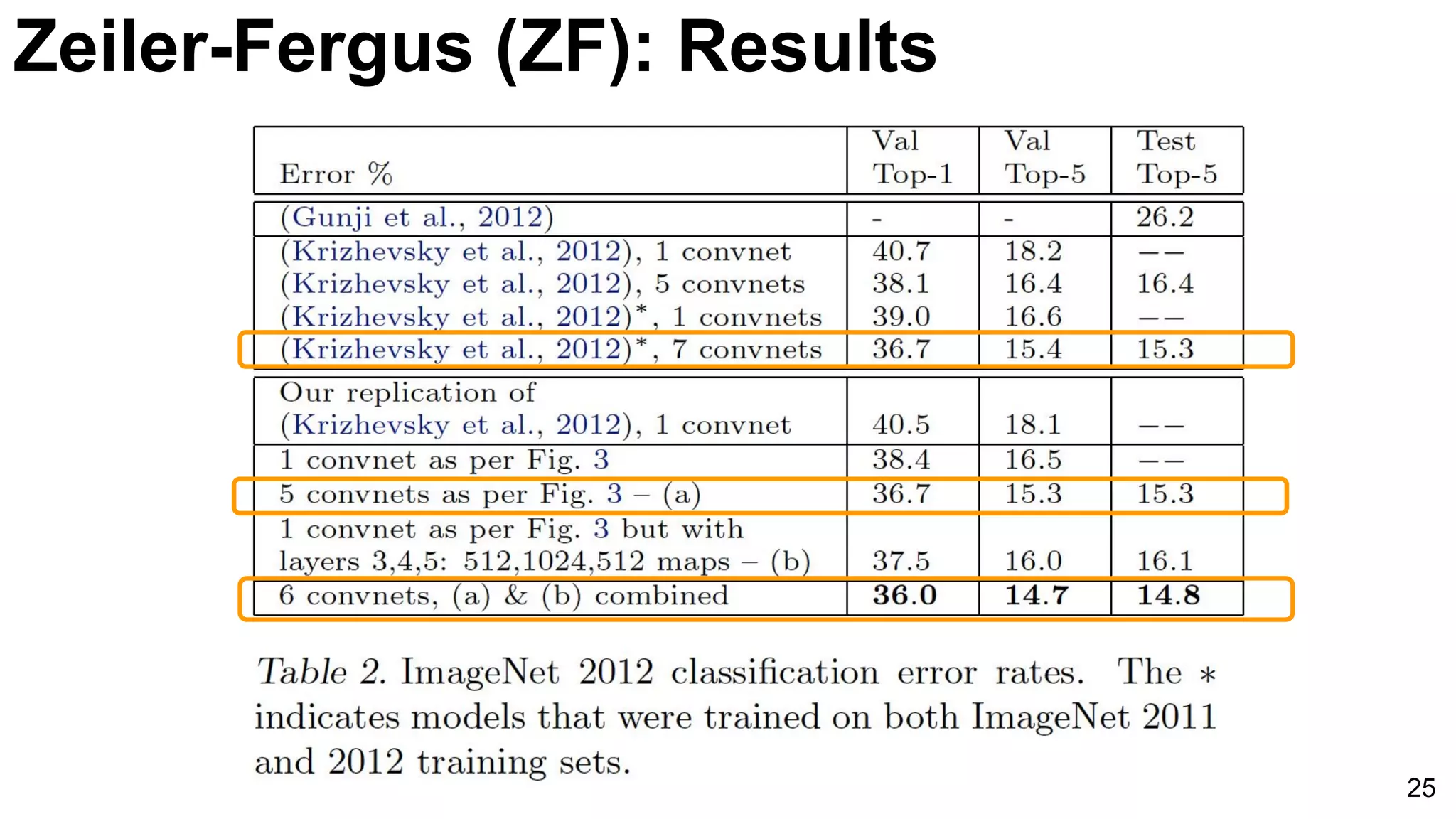
![ImageNet Classification 2013
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web]
-5%
26
E2E: Classification: ImageNet ILSRVC](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-26-2048.jpg)
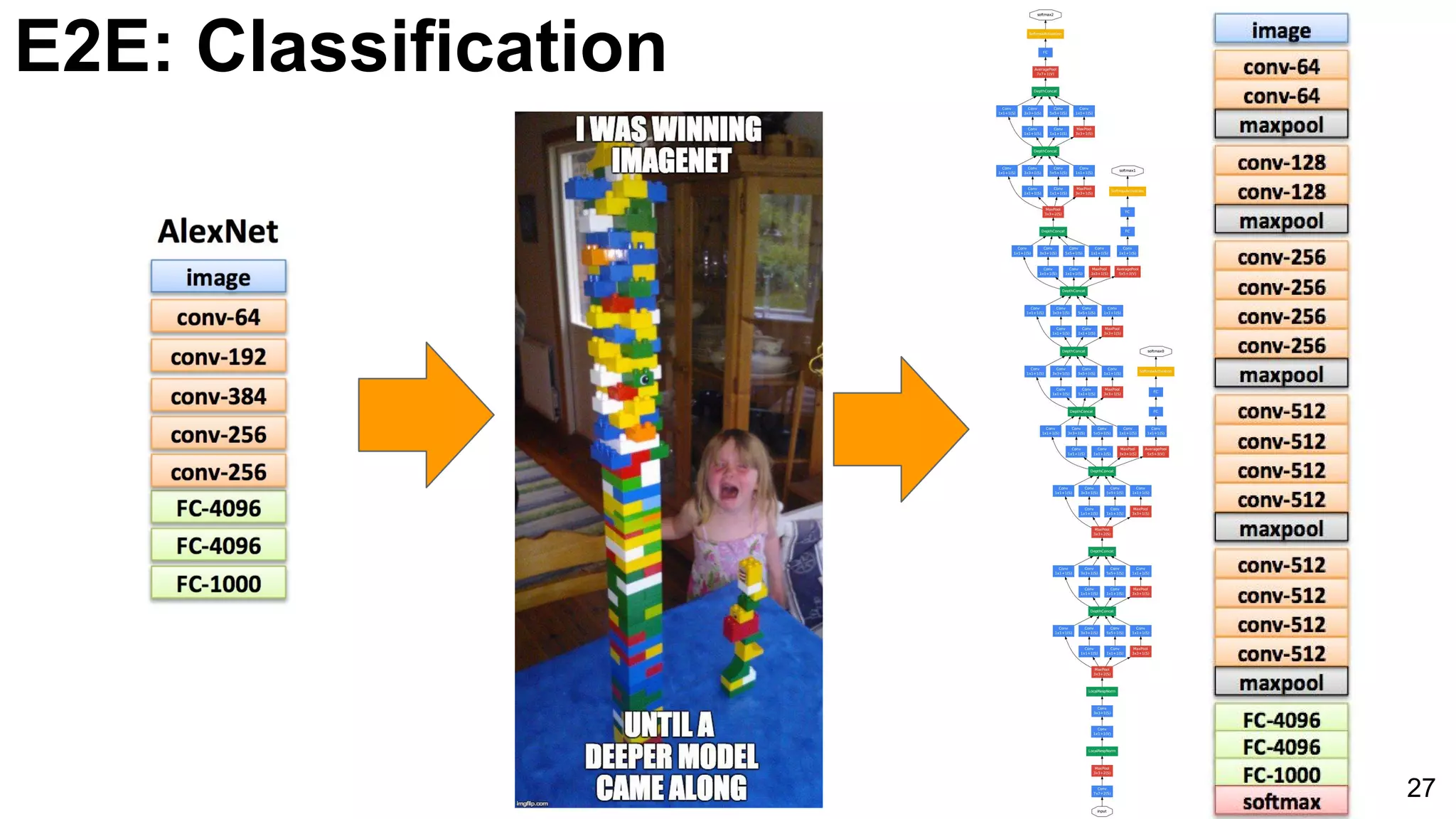

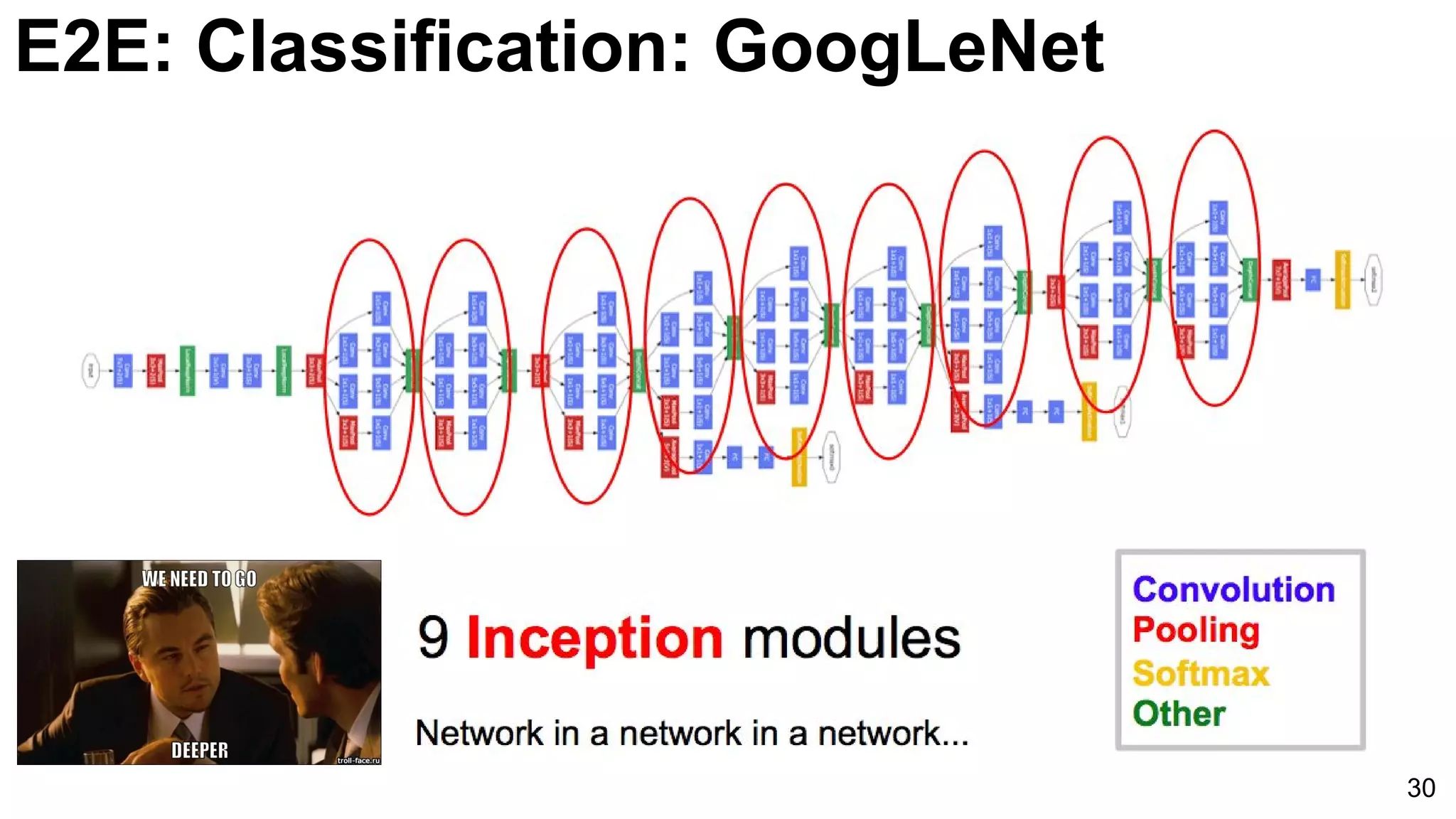
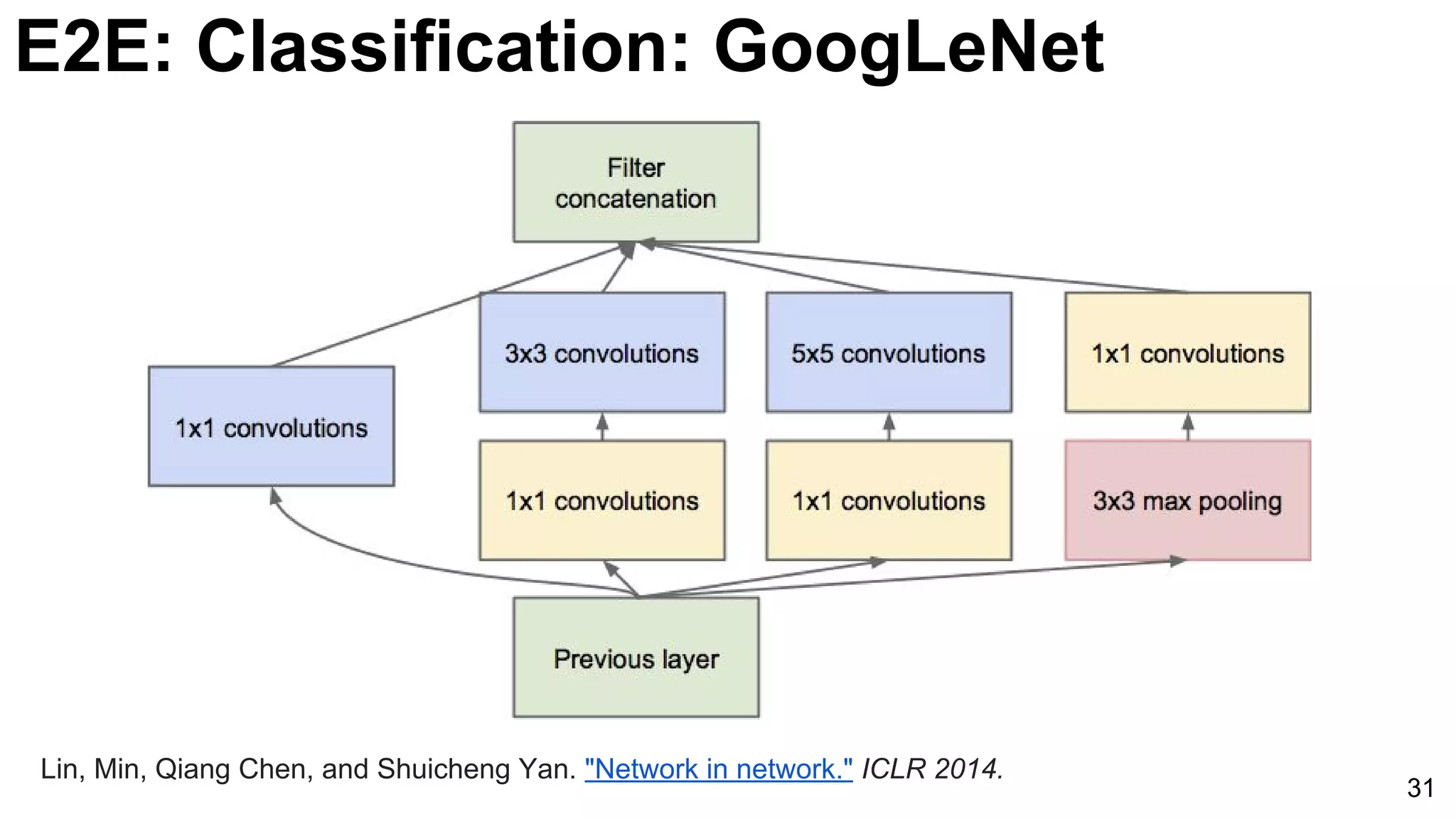
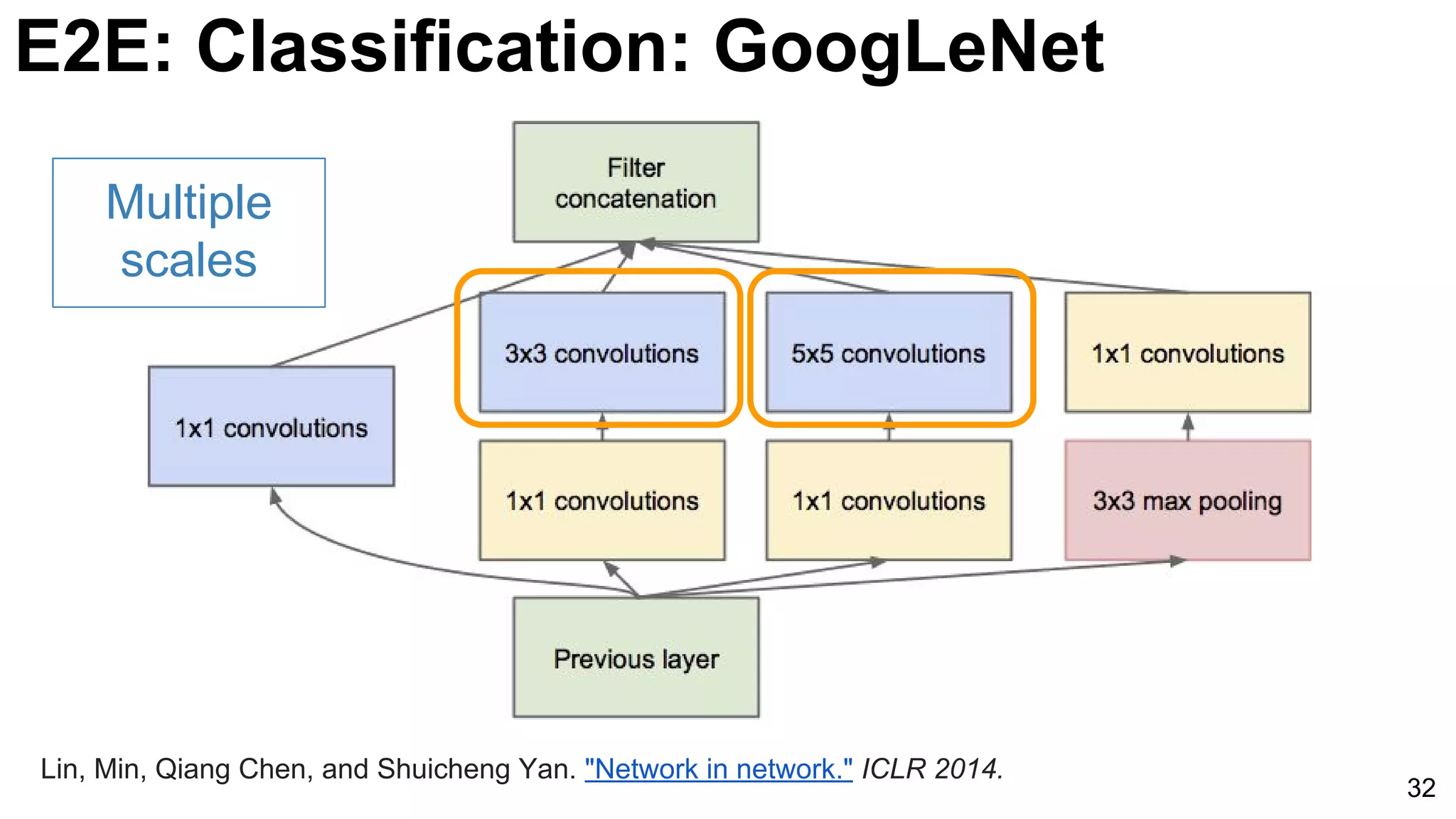
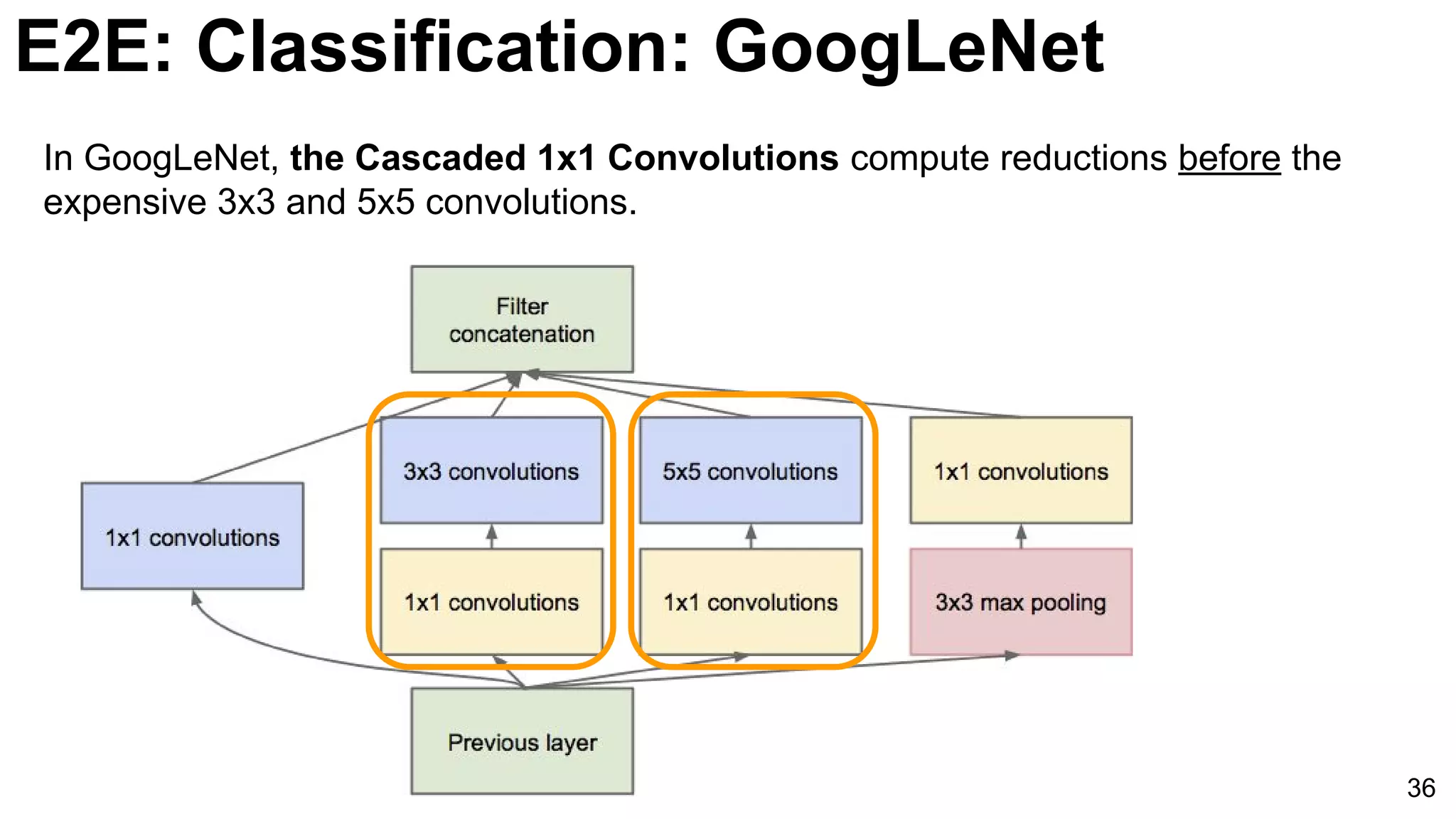
![E2E: Classification: GoogLeNet (NiN)
33
3x3 and 5x5 convolutions deal
with different scales.
Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." ICLR 2014. [Slides]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-33-2048.jpg)
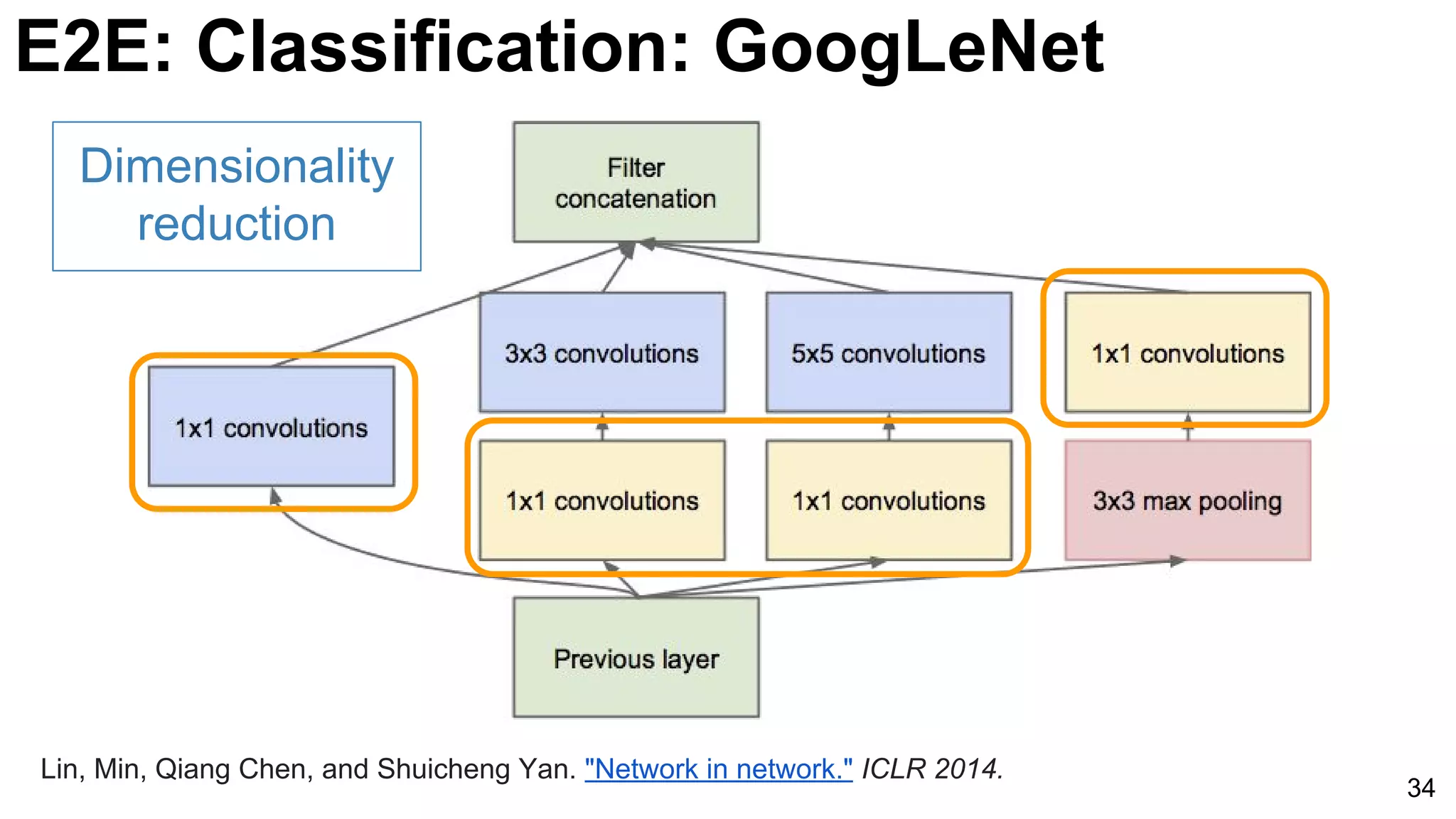
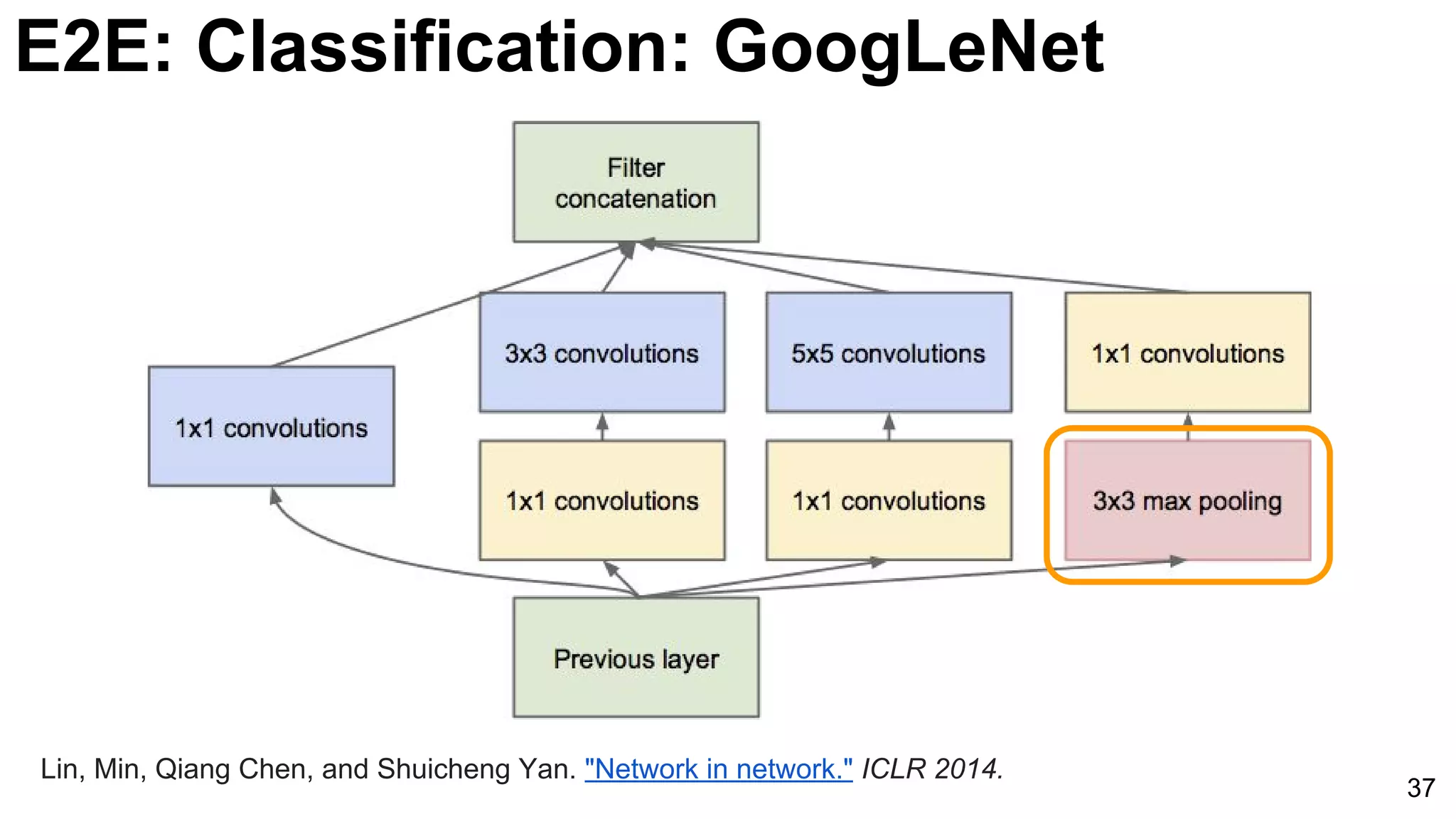
![35
1x1 convolutions does dimensionality
reduction (c3<c2) and accounts for rectified
linear units (ReLU).
Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." ICLR 2014. [Slides]
E2E: Classification: GoogLeNet (NiN)](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-35-2048.jpg)
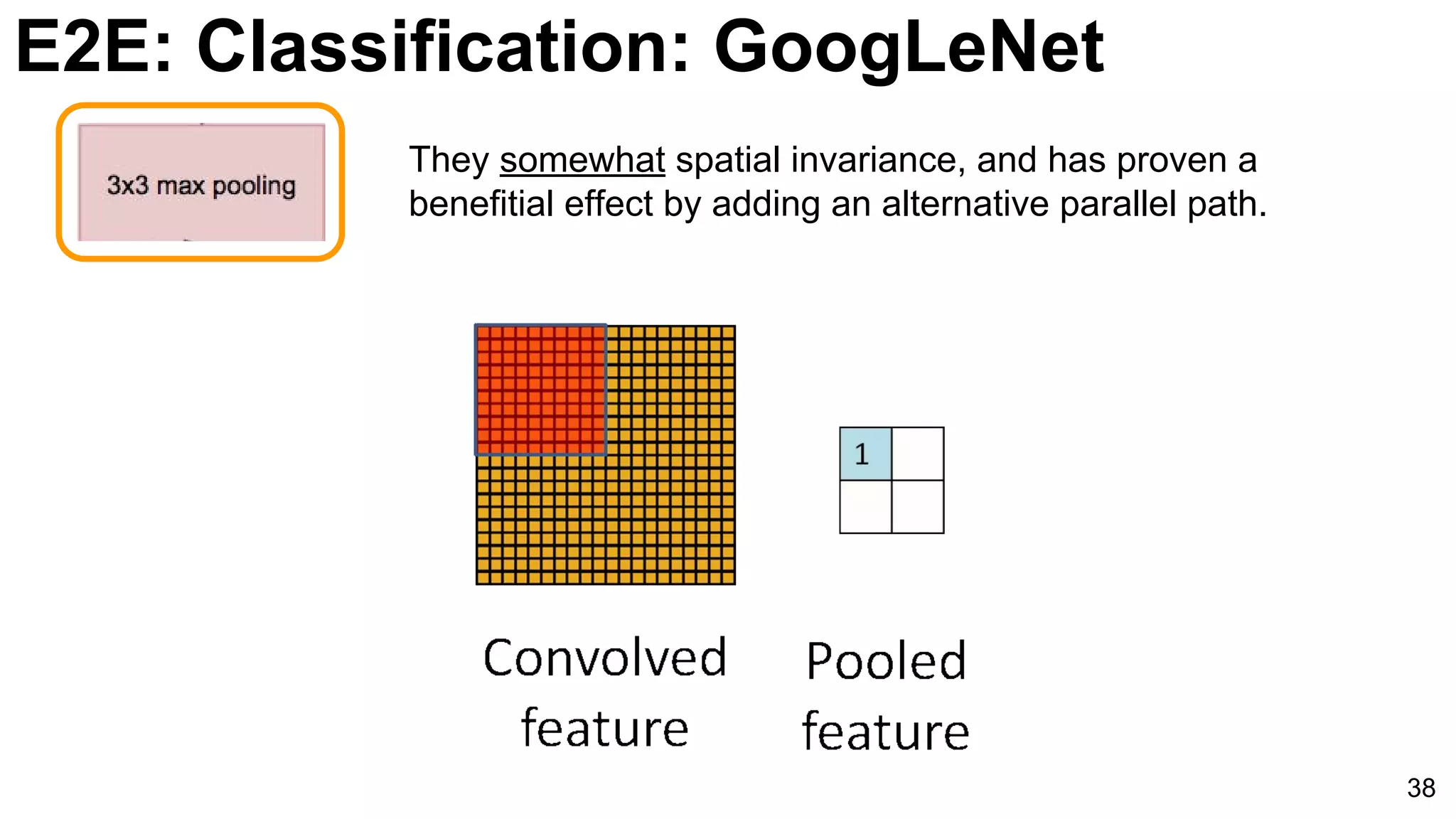
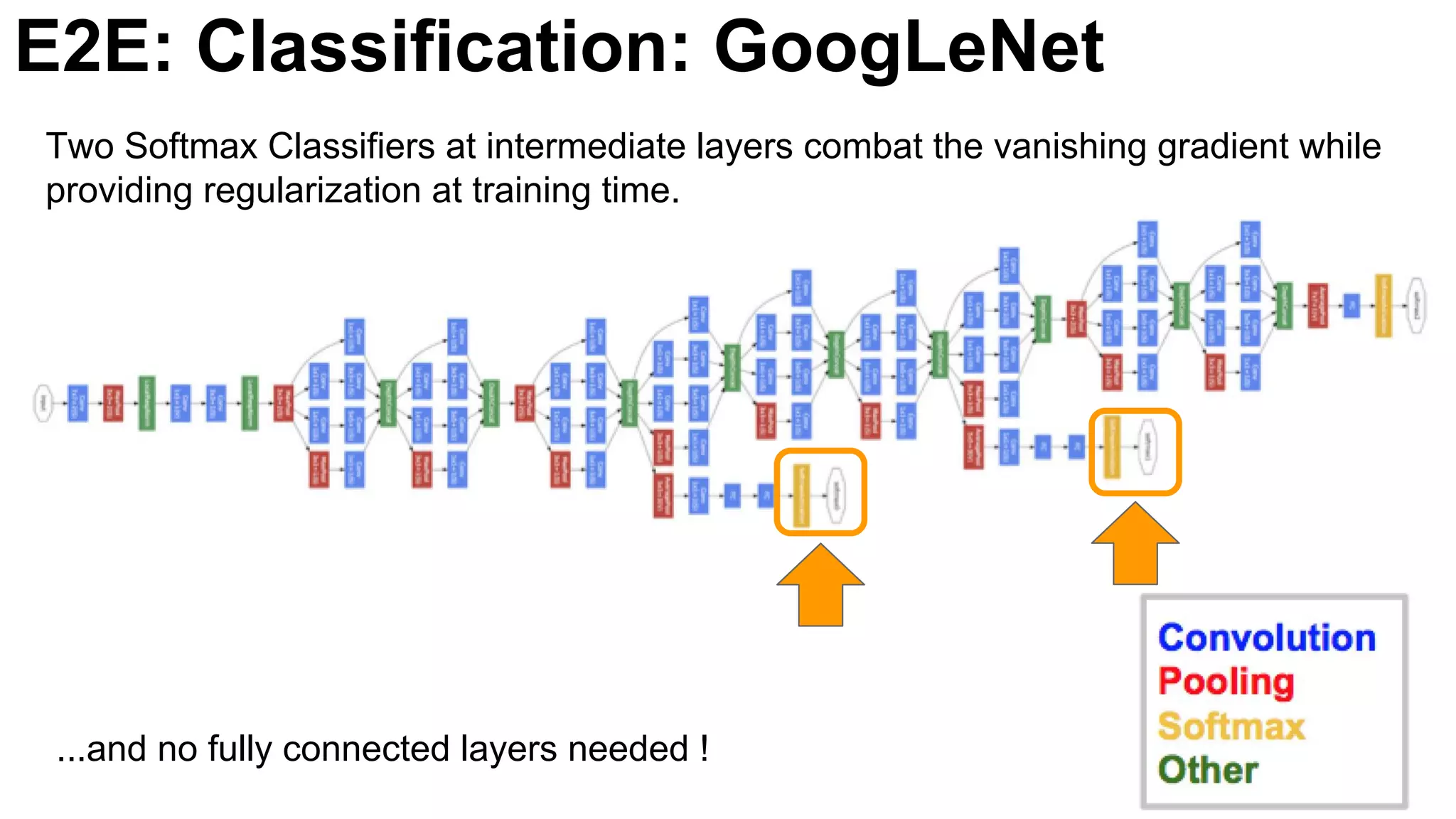
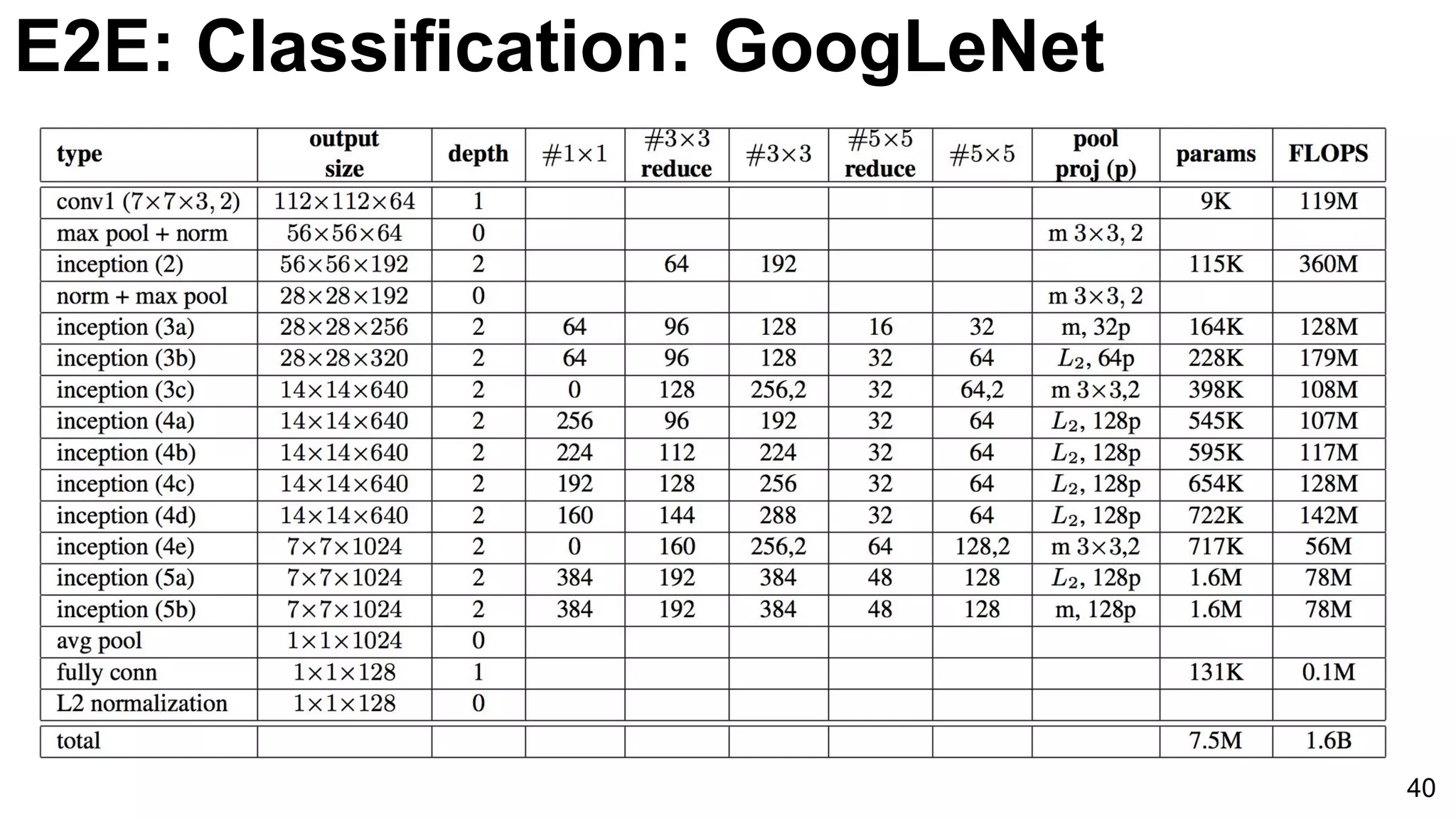
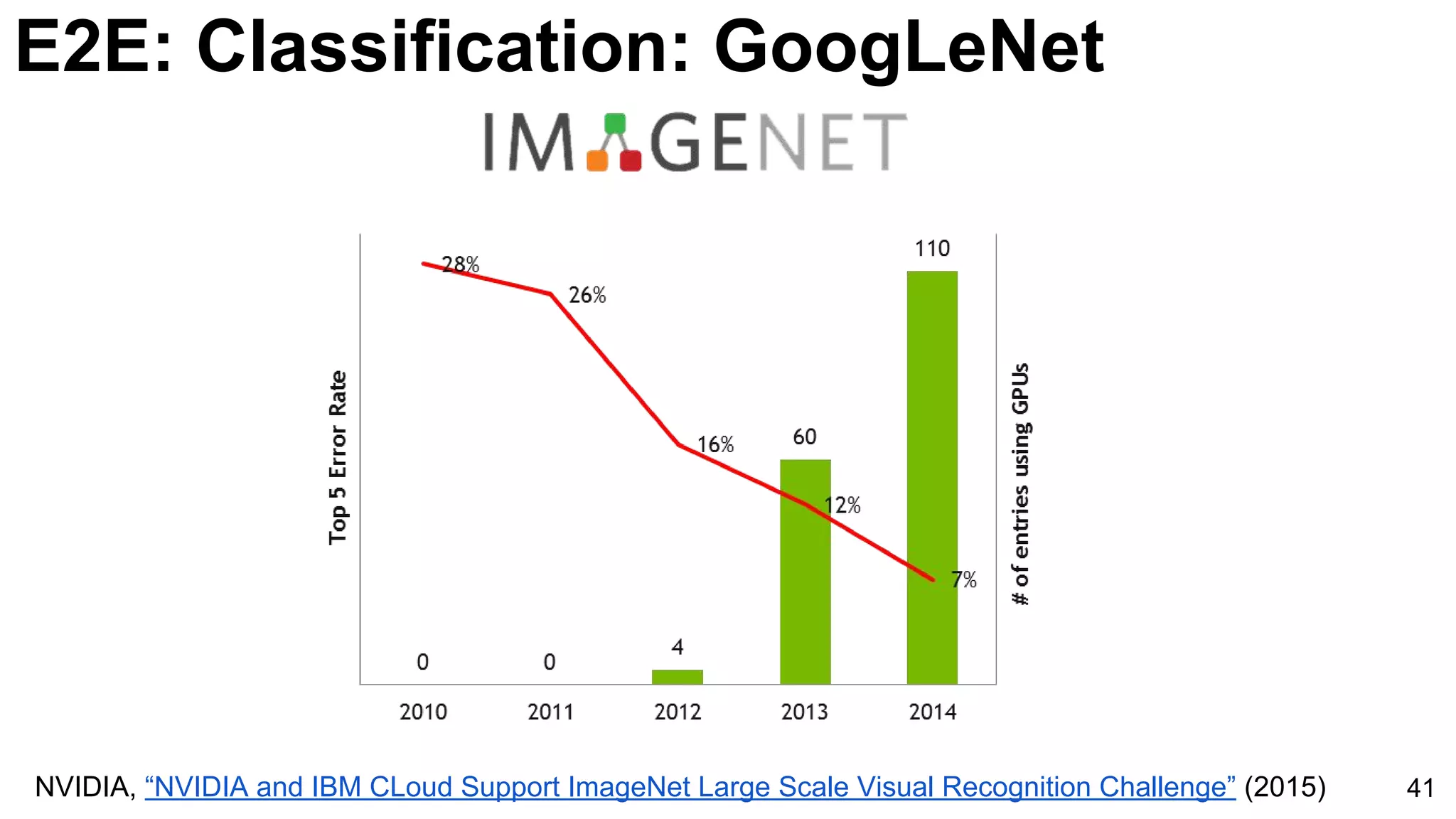
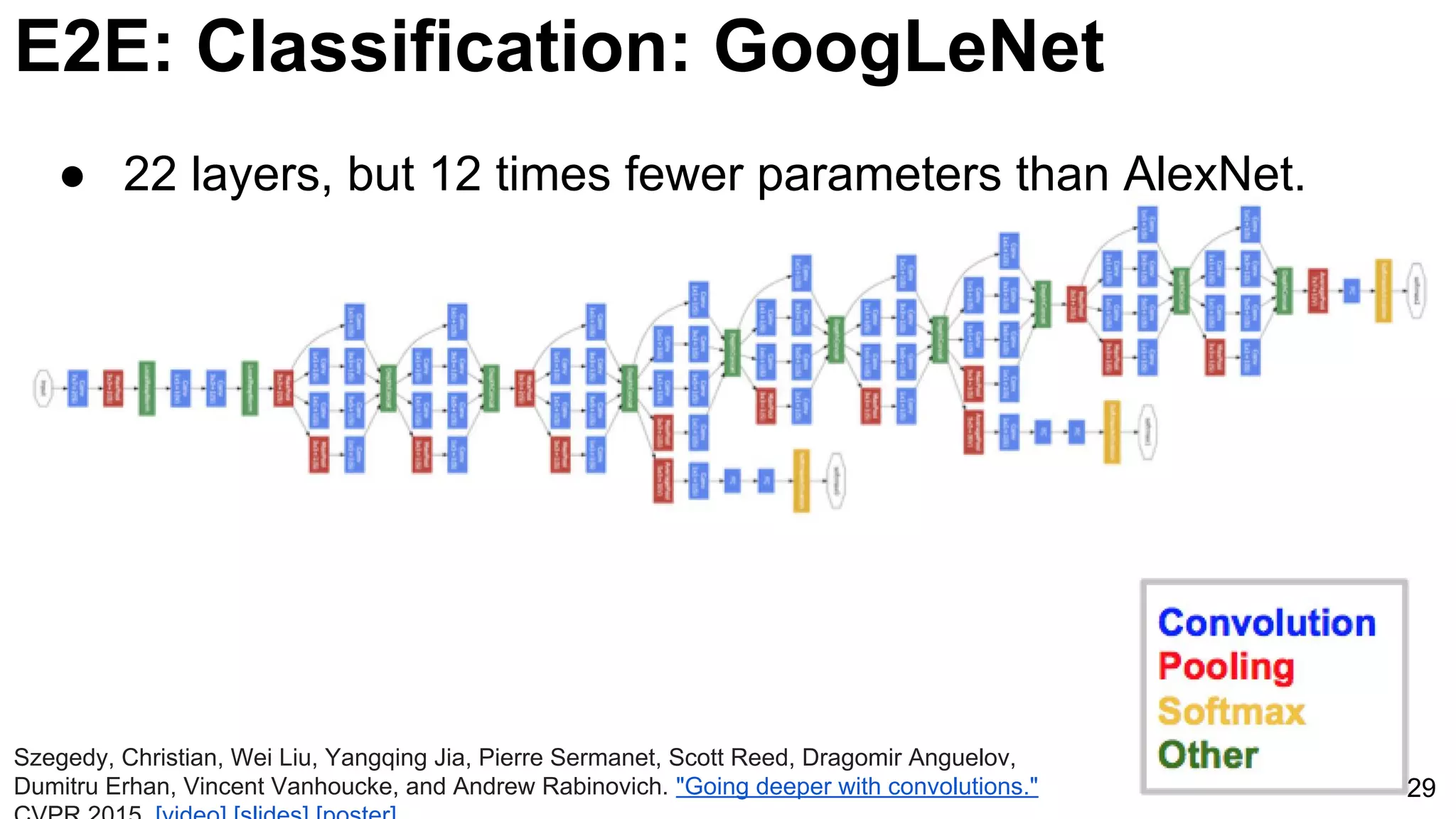
![E2E: Classification: GoogLeNet
42
Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent
Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." CVPR 2015. [video] [slides] [poster]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-42-2048.jpg)
![E2E: Classification: VGG
43
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition."
International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-43-2048.jpg)
![E2E: Classification: VGG
44
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition."
International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-44-2048.jpg)
![E2E: Classification: VGG: 3x3 Stacks
45
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image
recognition." International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-45-2048.jpg)
![E2E: Classification: VGG
46
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image
recognition." International Conference on Learning Representations (2015). [video] [slides] [project]
● No poolings between some convolutional layers.
● Convolution strides of 1 (no skipping).](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-46-2048.jpg)
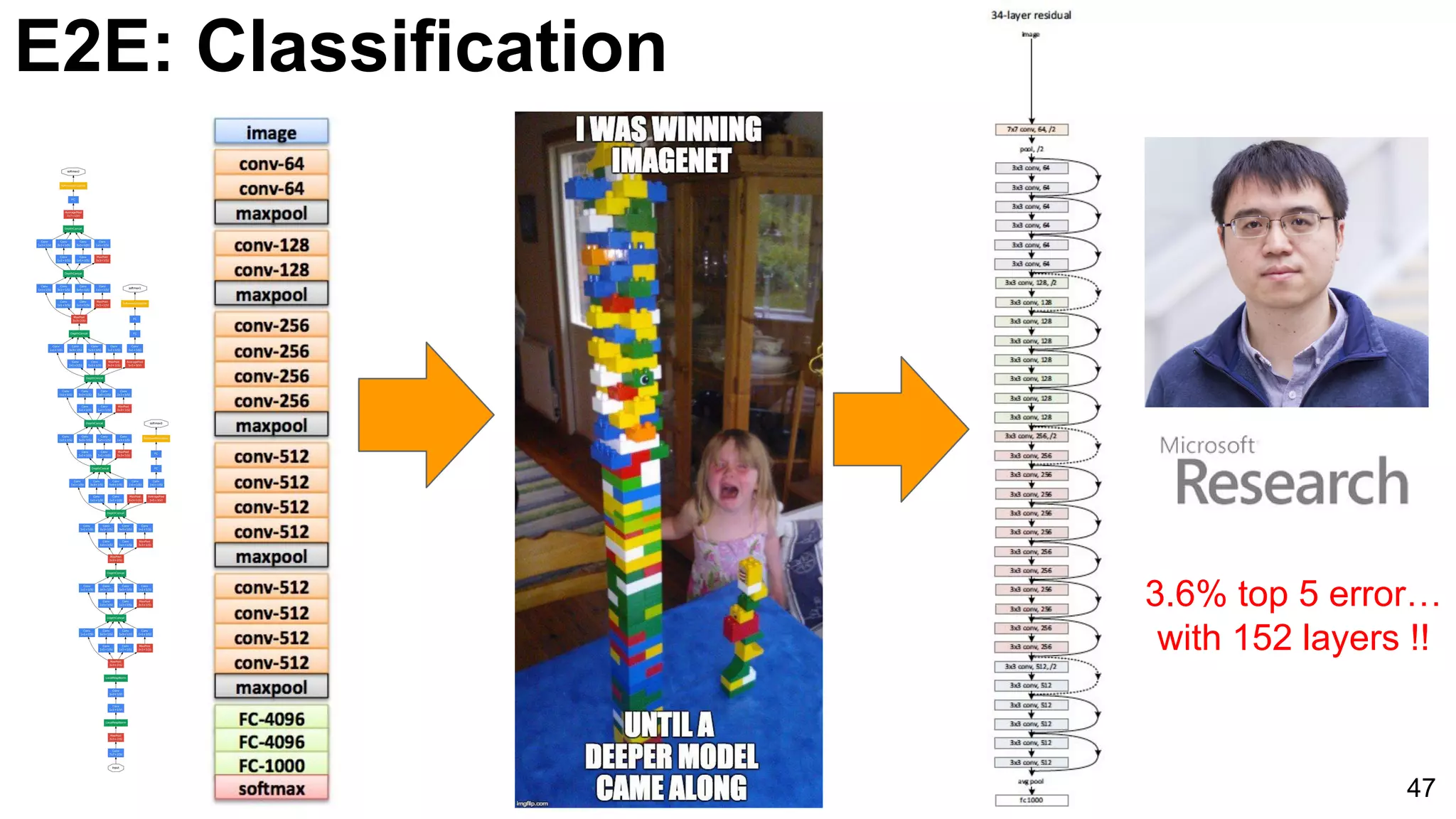
![E2E: Classification: ResNet
48
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-48-2048.jpg)
![E2E: Classification: ResNet
49
● Deeper networks (34 is deeper than 18) are more difficult to train.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]
Thin curves: training error
Bold curves: validation error](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-49-2048.jpg)
![ResNet
50
● Residual learning: reformulate the layers as learning residual functions with
reference to the layer inputs, instead of learning unreferenced functions
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-50-2048.jpg)
![E2E: Classification: ResNet
51
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]](https://image.slidesharecdn.com/dlcvd2l4imagenet-160802094728/75/Deep-Learning-for-Computer-Vision-ImageNet-Challenge-UPC-2016-51-2048.jpg)


The document discusses the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), detailing the dataset comprising 1,000 object classes with 1.2 million training images and 100,000 test images. It highlights the evolution of image classification techniques, with a focus on architectures like AlexNet, GoogLeNet, and ResNet, emphasizing improvements in accuracy and feature extraction methods. Additionally, it mentions various publications and contributions by researchers in the development of convolutional neural networks and visualization techniques.
Overview of ImageNet Large Scale Visual Recognition Challenge (ILSVRC) and dataset contributions.
The dataset consists of 1,000 object classes with 1.2M training and 100k testing images, focusing on top 5 error rate.
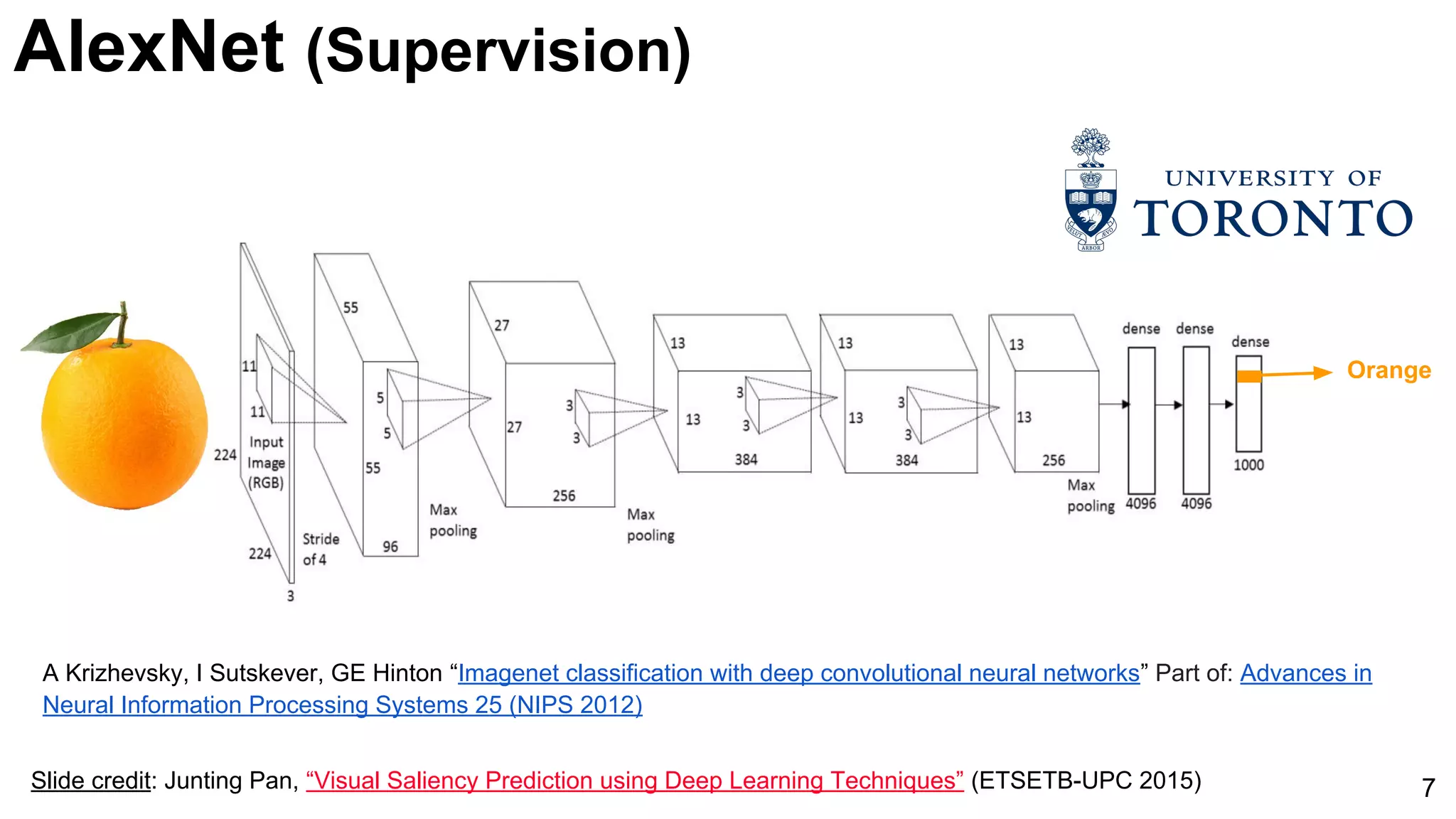
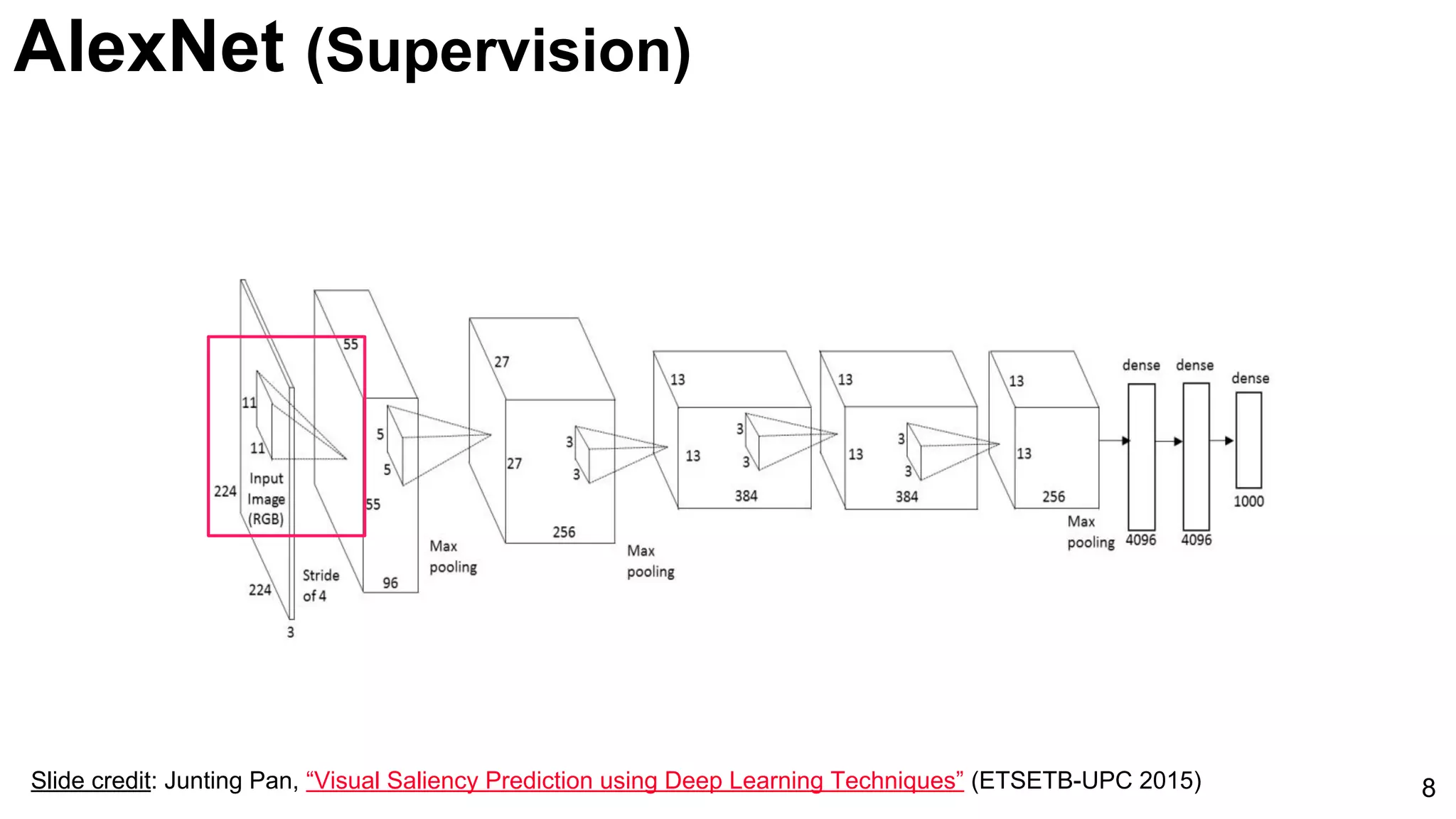
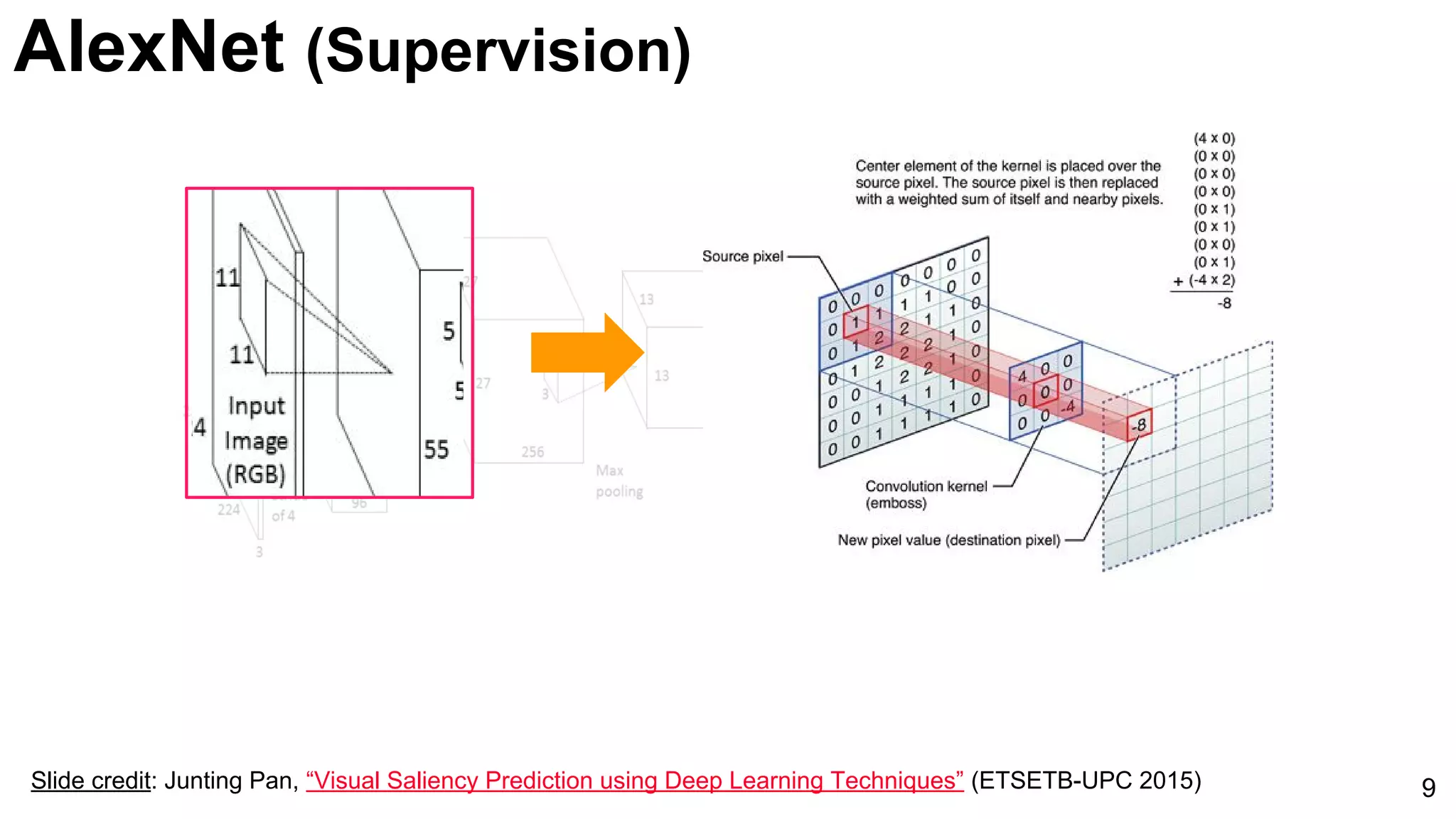
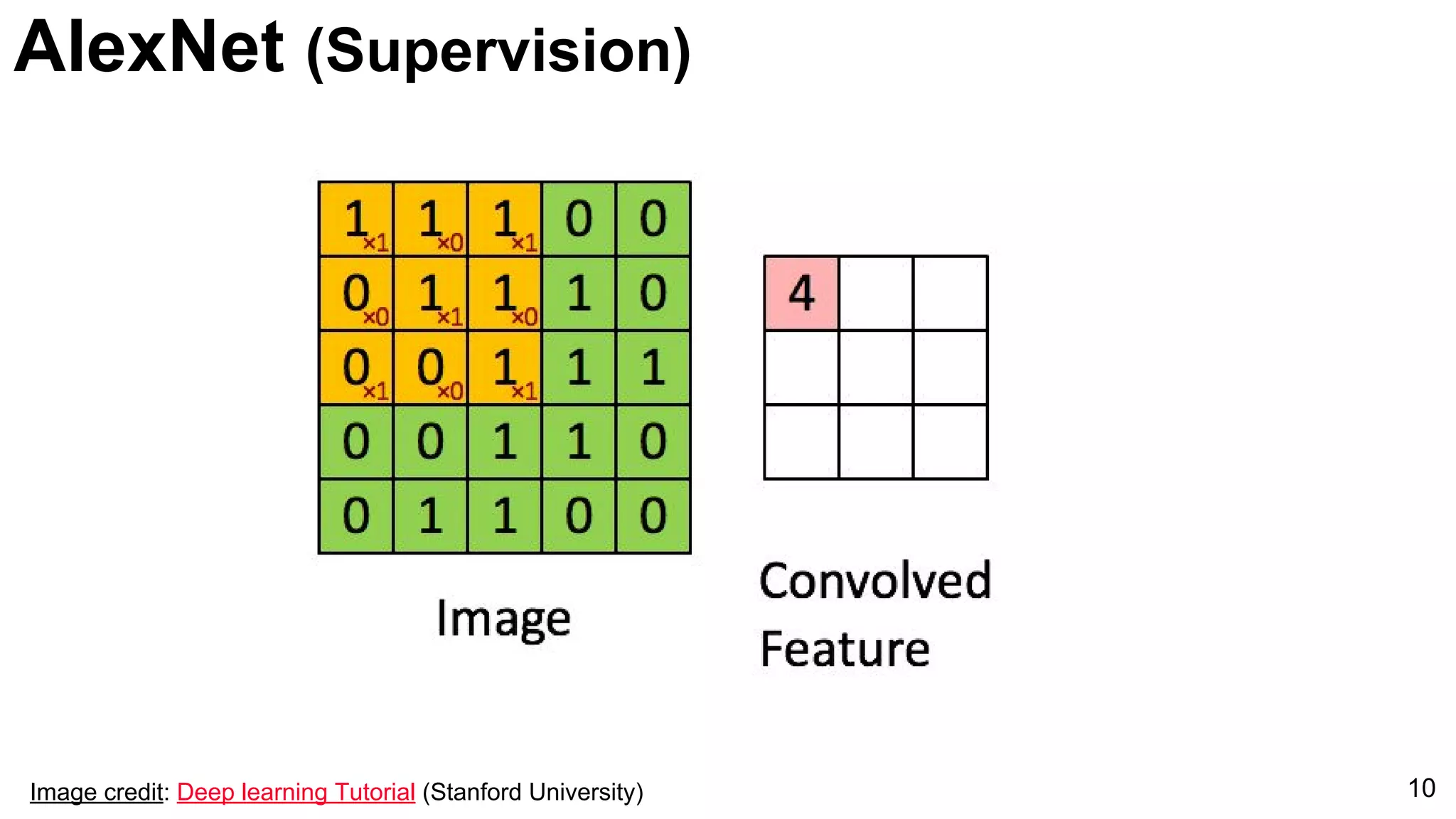
Introduction of AlexNet as a significant model for image classification, marked by its innovative architecture.
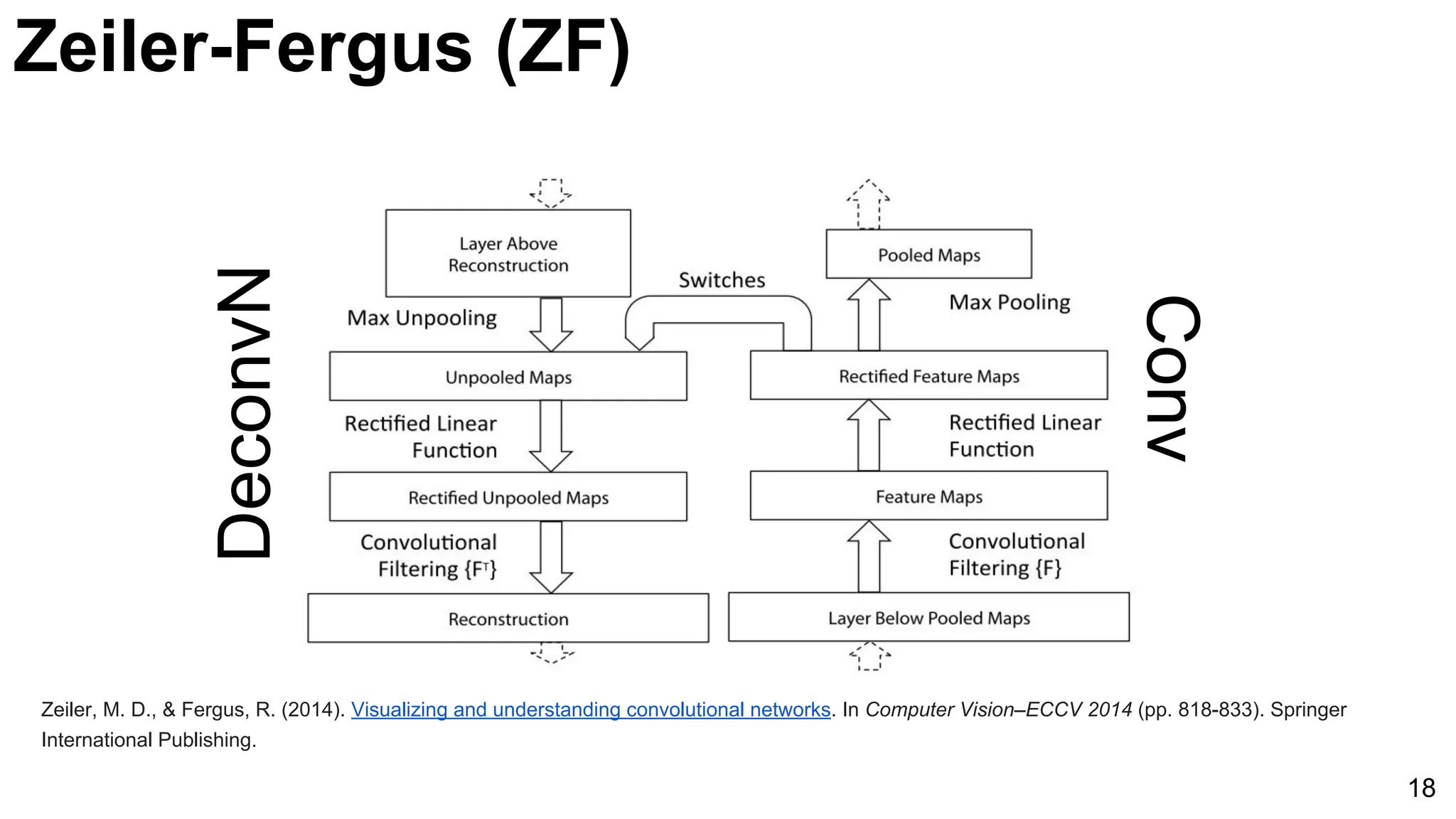
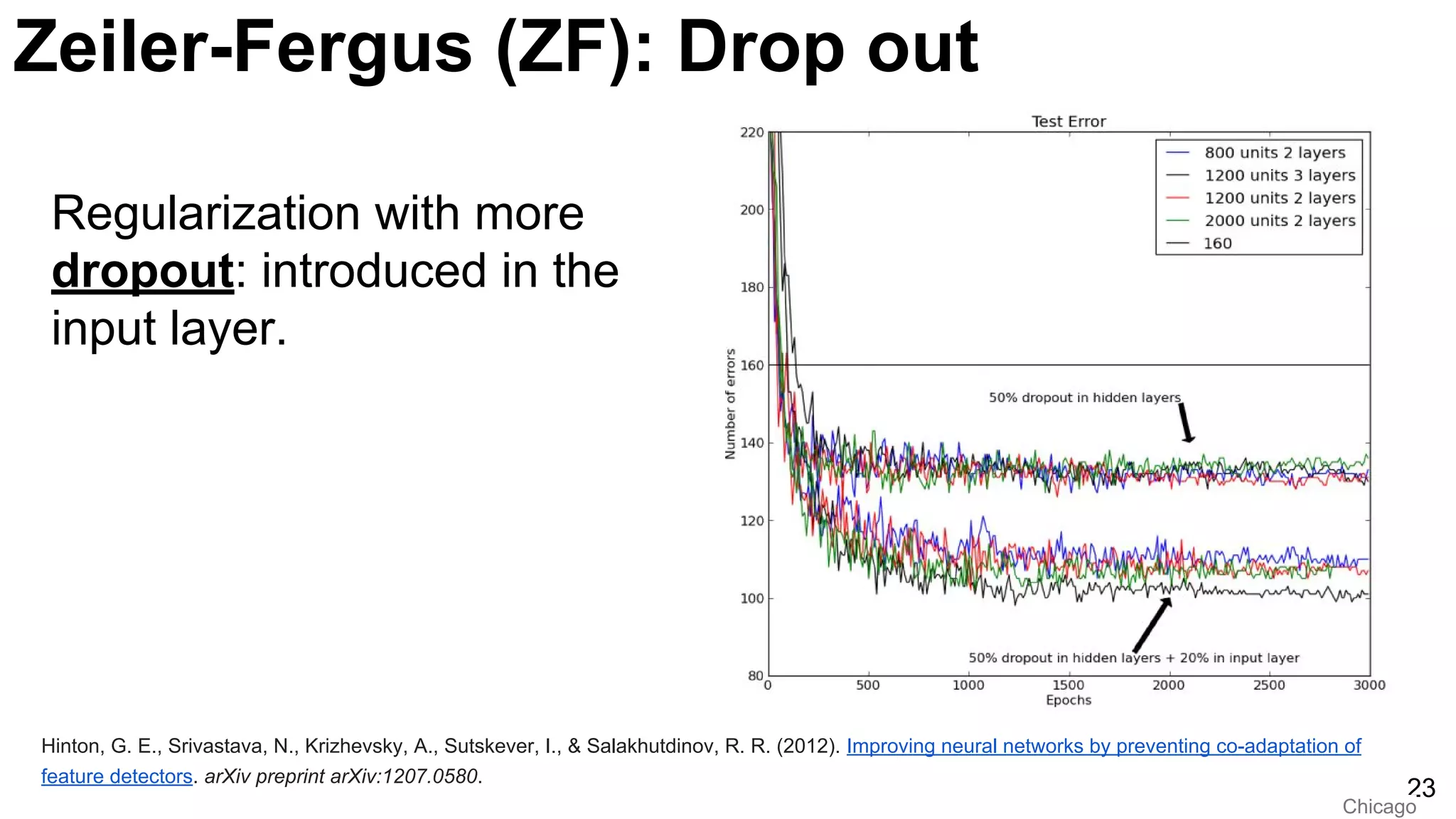
Discussion on Zeiler-Fergus model, highlighting reverse mapping in convnets and the impact of visualization.
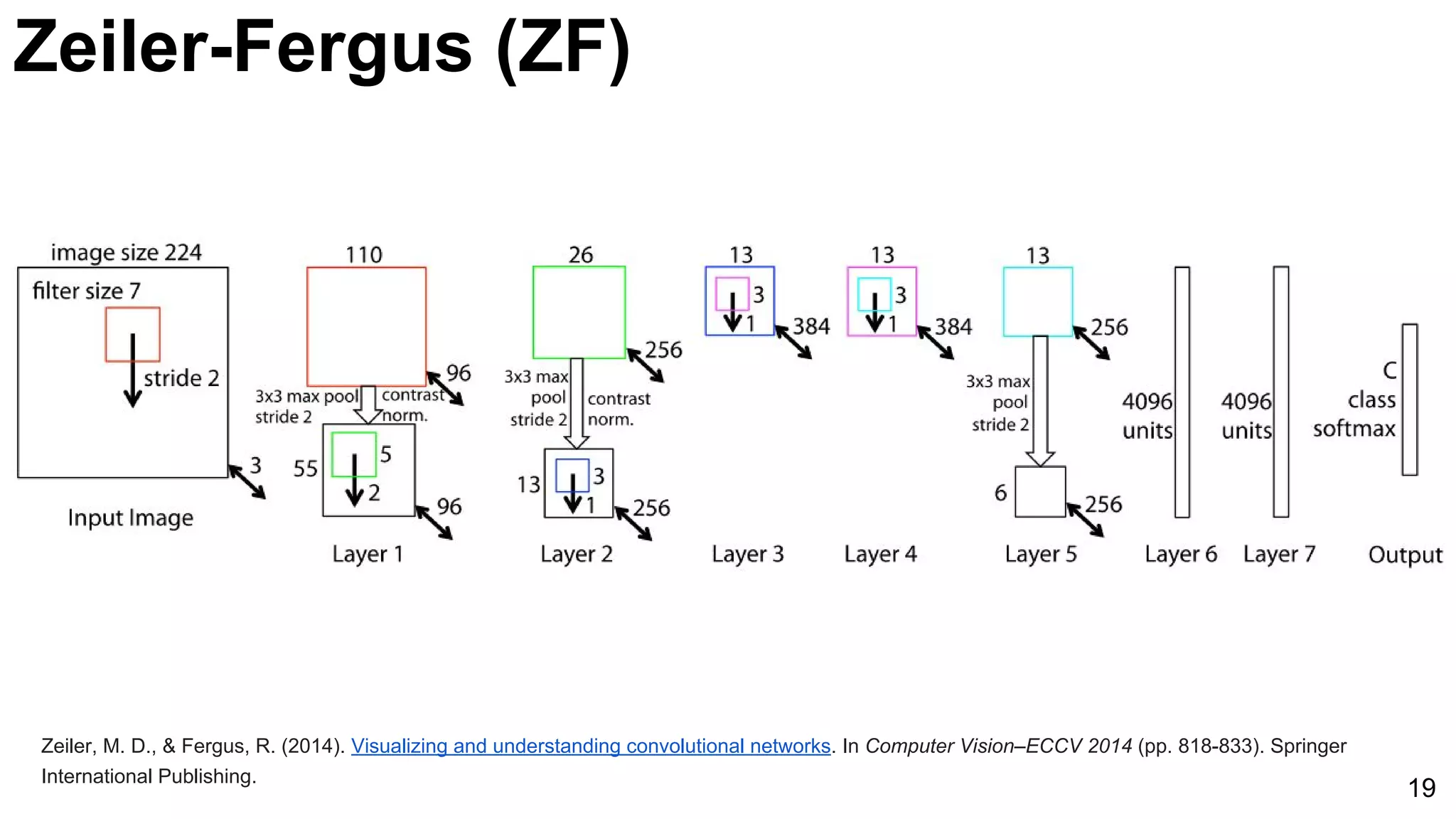
Comparison of AlexNet and Zeiler-Fergus architectures focusing on feature extraction efficiencies and a notable error rate decrease to 5%.
Introduction of GoogLeNet with multiple layers and parameters reducing strategy, utilizing softmax classifiers to improve training efficacy.
Presentation of VGG with its deep network structure focusing on image recognition and a low top 5 error rate of 3.6%.
Exploration of ResNet architecture, detailing advancements in deep learning through residual connections and enhancing model training.























![[PR12] Inception and Xception - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12inceptionandxception-jaejunyoo-170910140157-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)