Download as PDF, PPTX



![3
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual
recognition challenge. arXiv preprint arXiv:1409.0575. [web]
ImageNet Dataset](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-3-320.jpg)
![Slide credit:
Rob Fergus (NYU)
-9.8%
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2014). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web] 4
Based on SIFT + Fisher Vectors
ImageNet Challenge: 2012](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-4-320.jpg)
![ImageNet Classification 2013
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web]
Slide credit:
Rob Fergus (NYU)
6
ImageNet Challenge: 2013](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-6-320.jpg)


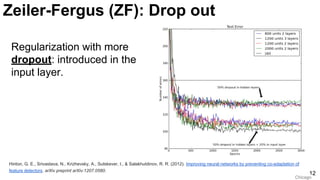
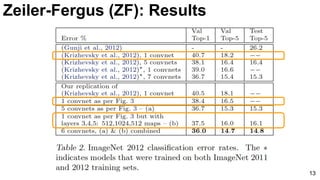
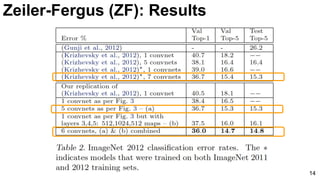
![ImageNet Classification 2013
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web]
-5%
15
ImageNet Challenge: 2013](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-15-320.jpg)


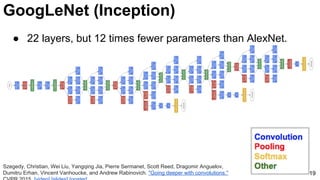
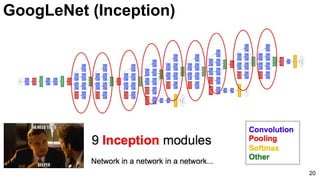
![GoogLeNet (NiN)
23
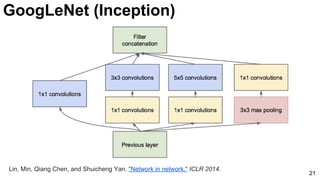
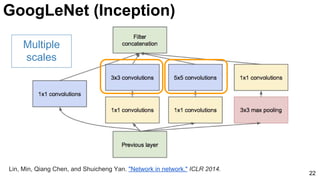
3x3 and 5x5 convolutions deal
with different scales.
Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." ICLR 2014. [Slides]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-23-320.jpg)
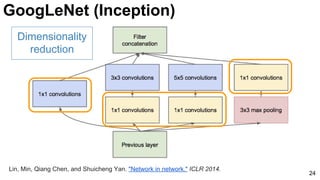
![25
1x1 convolutions does dimensionality
reduction (c3<c2) and accounts for rectified
linear units (ReLU).
Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." ICLR 2014. [Slides]
GoogLeNet (Inception)](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-25-320.jpg)
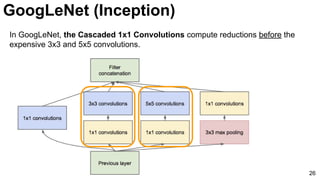
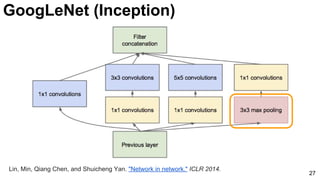
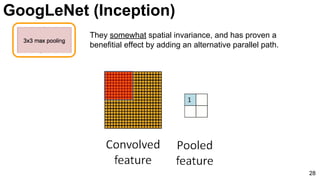
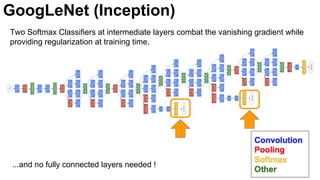
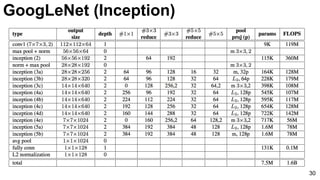
![31
Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent
Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." CVPR 2015. [video] [slides] [poster]
GoogLeNet (Inception)](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-31-320.jpg)
![E2E: Classification: VGG
32
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." ICLR 2015.
[video] [slides] [project]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-32-320.jpg)
![E2E: Classification: VGG
33
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition."
International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-33-320.jpg)
![E2E: Classification: VGG: 3x3 Stacks
34
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image
recognition." International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-34-320.jpg)
![E2E: Classification: VGG
35
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image
recognition." International Conference on Learning Representations (2015). [video] [slides] [project]
● No poolings between some convolutional layers.
● Convolution strides of 1 (no skipping).](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-35-320.jpg)

![E2E: Classification: ResNet
37
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-37-320.jpg)
![E2E: Classification: ResNet
38
● Deeper networks (34 is deeper than 18) are more difficult to train.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]
Thin curves: training error
Bold curves: validation error](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-38-320.jpg)
![ResNet
39
● Residual learning: reformulate the layers as learning residual functions with
reference to the layer inputs, instead of learning unreferenced functions
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-39-320.jpg)
![E2E: Classification: ResNet
40
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385
(2015). [slides]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-40-320.jpg)
![41
Learn more
Li Fei-Fei, “How we’re teaching computers to understand
pictures” TEDTalks 2014.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual
recognition challenge. arXiv preprint arXiv:1409.0575. [web]](https://image.slidesharecdn.com/dlmmdcud1l03imageclassificationonimagenet-170427160933/85/Image-Classification-on-ImageNet-D1L3-Insight-DCU-Machine-Learning-Workshop-2017-41-320.jpg)


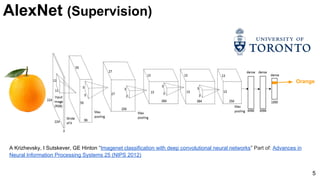
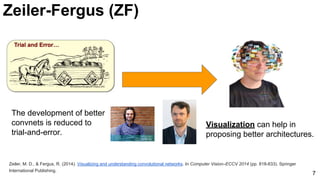
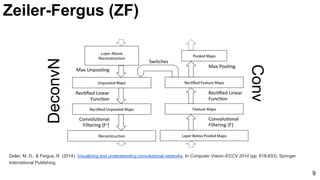
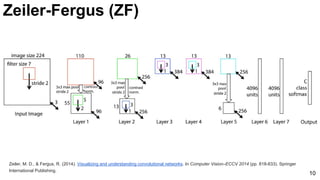
The document discusses advancements in image classification through the ImageNet challenge, emphasizing the evolution of convolutional neural networks (CNNs) like AlexNet, GoogLeNet, and ResNet. It highlights techniques such as dropout regularization and the use of deconvolutional networks to improve feature learning. Key studies, architecture designs, and their impact on neural network performance are referenced throughout.























![[IGC 2017] 넥슨코리아 심재근 - 시스템 기획자에 대한 기본 지식과 준비과정](https://cdn.slidesharecdn.com/ss_thumbnails/igc-170905073804-thumbnail.jpg?width=640&height=640&fit=bounds)






























































