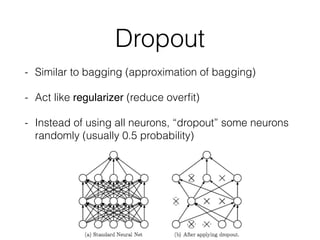
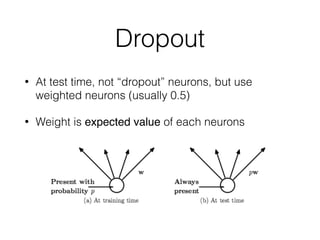
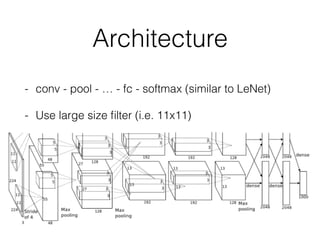
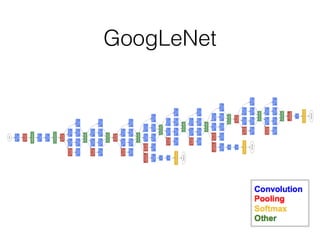
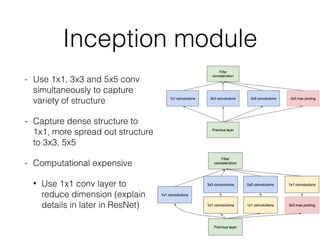
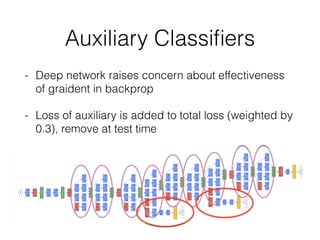
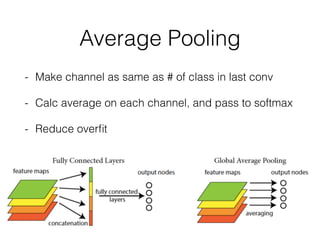
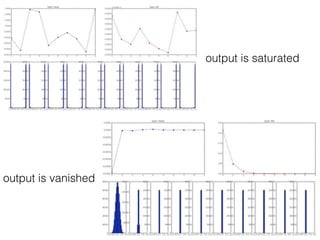
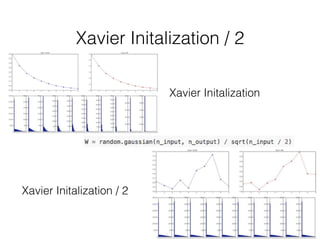
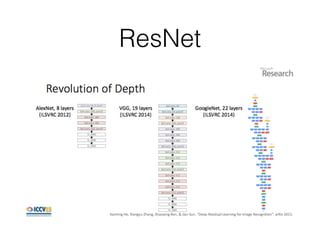
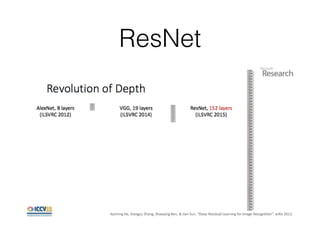
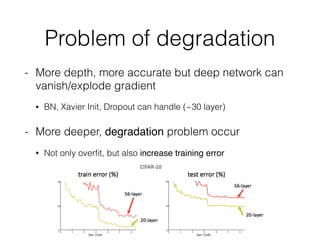
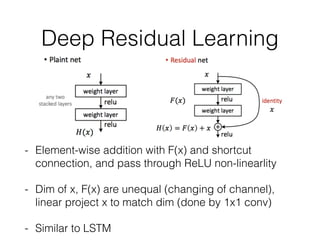
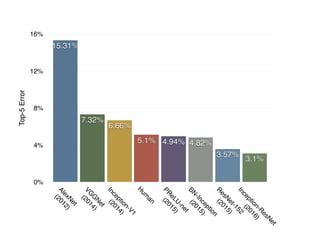
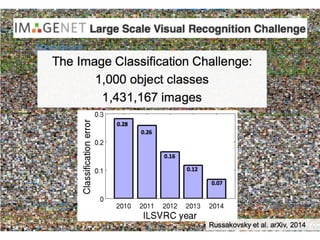
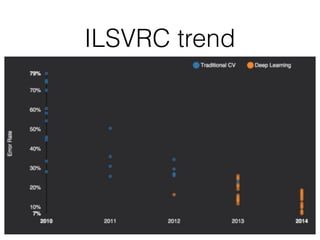
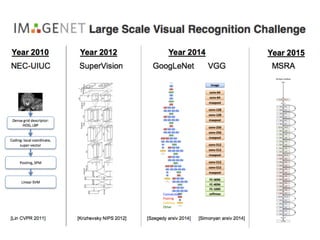
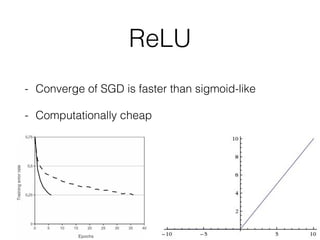
This document summarizes the evolution of convolutional neural networks (CNNs) from LeNet to ResNet. It discusses key CNN architectures like AlexNet, VGGNet, GoogLeNet, and ResNet and the techniques they introduced such as ReLU, dropout, batch normalization, and residual connections. These techniques helped reduce overfitting and allowed training of much deeper networks, leading to substantially improved accuracy on the ImageNet challenge over time, from AlexNet's top-5 error of 15.3% in 2012 to ResNet's 3.57% in 2015.


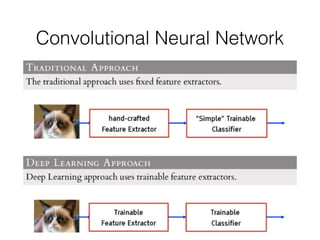
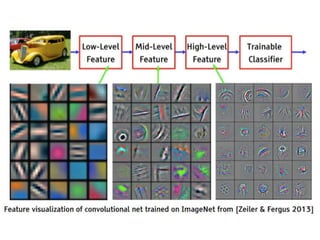

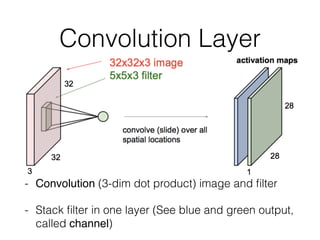

![Convolution Layer
- Example) 1st conv layer in AlexNet
• Input: [224, 224], filter: [11x11x3], 96, output: [55, 55]
- Each filter extract different features (i.e. horizontal
edge, vertical edge…)](https://image.slidesharecdn.com/case-study-of-cnn-160501201532/85/Case-Study-of-Convolutional-Neural-Network-7-320.jpg)








![Data augmentation
- Randomly crop [256, 256] images to [224, 224]
- At test time, crop 5 images and average to predict](https://image.slidesharecdn.com/case-study-of-cnn-160501201532/85/Case-Study-of-Convolutional-Neural-Network-22-320.jpg)