Download as PDF, PPTX













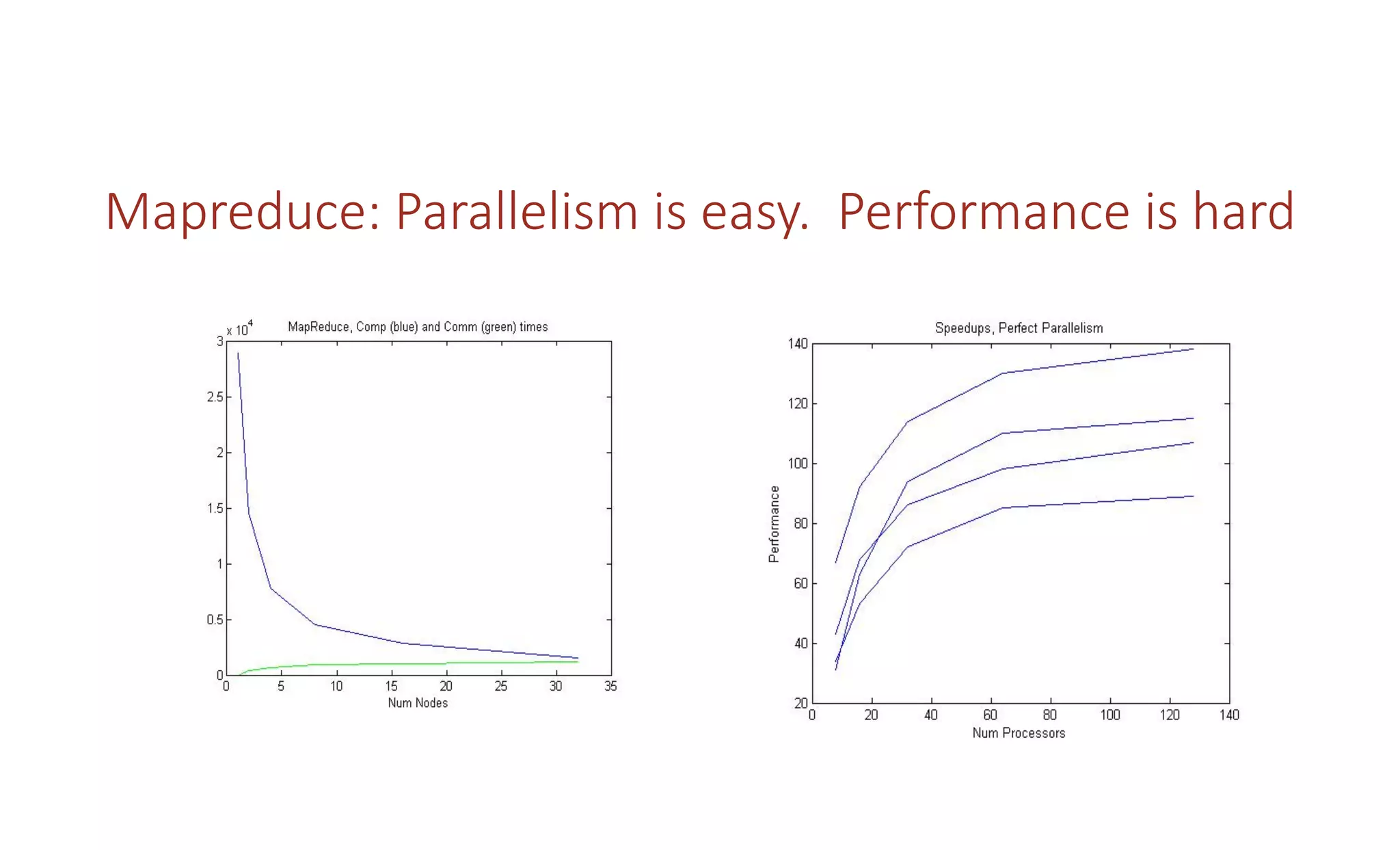






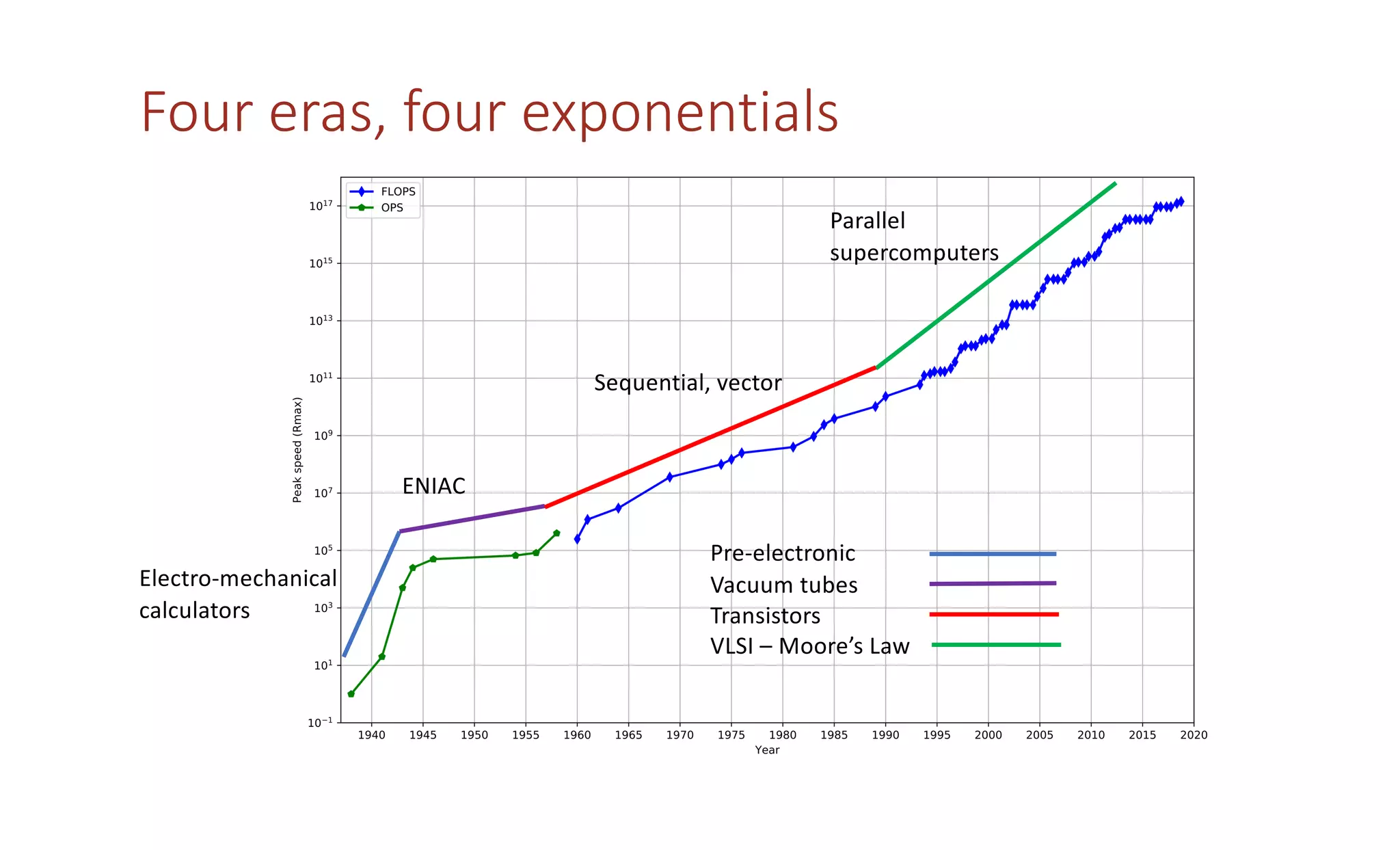


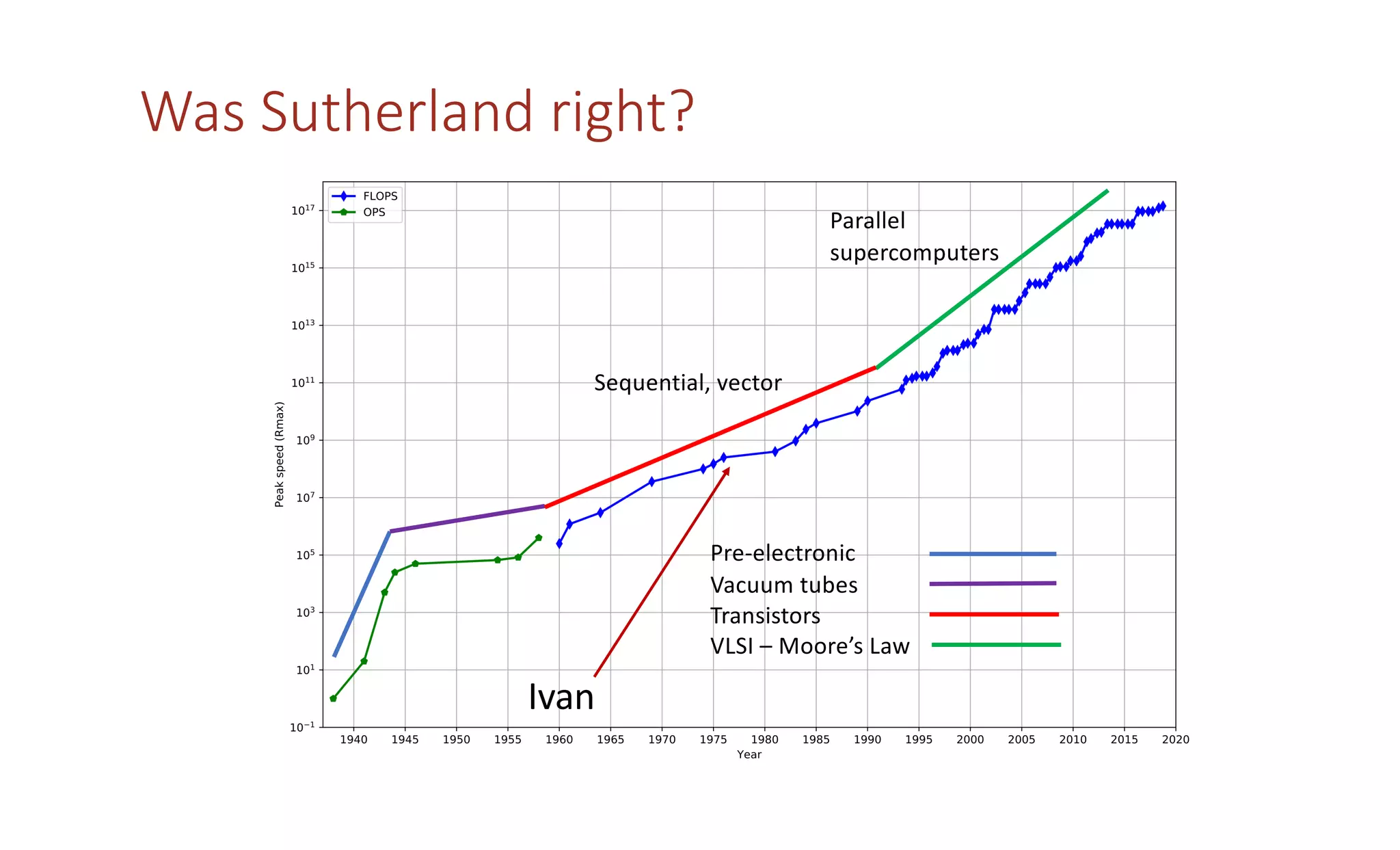





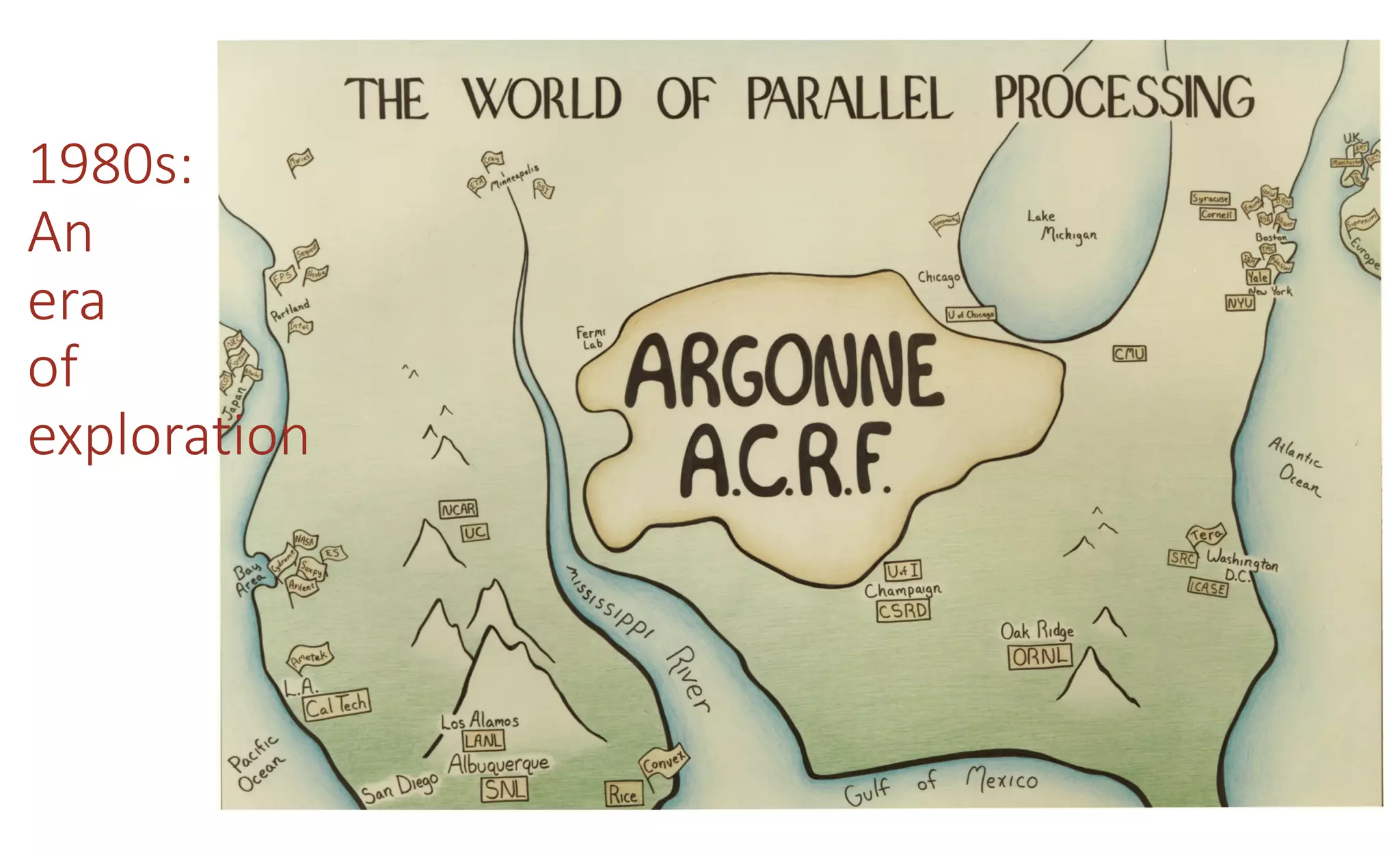

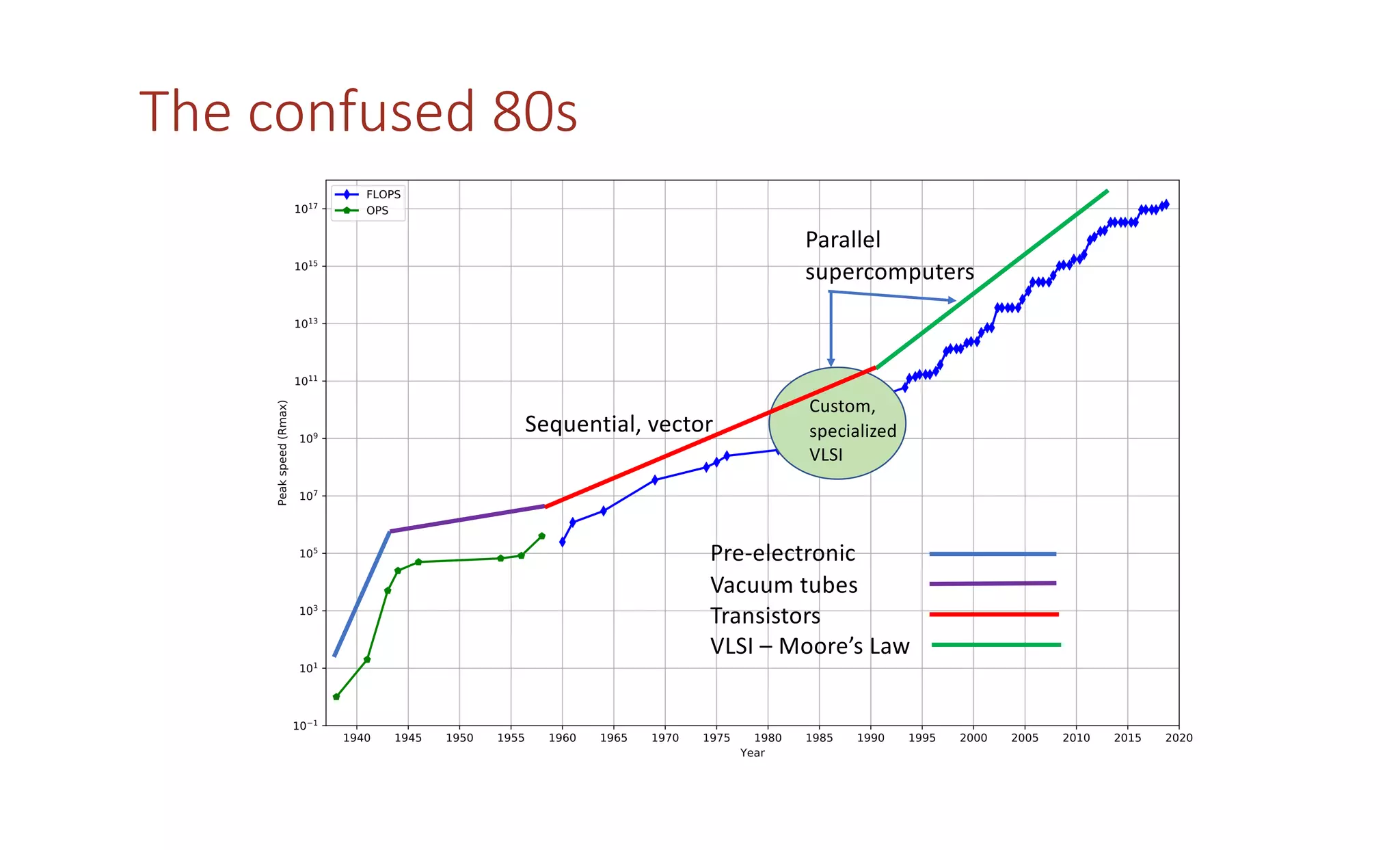














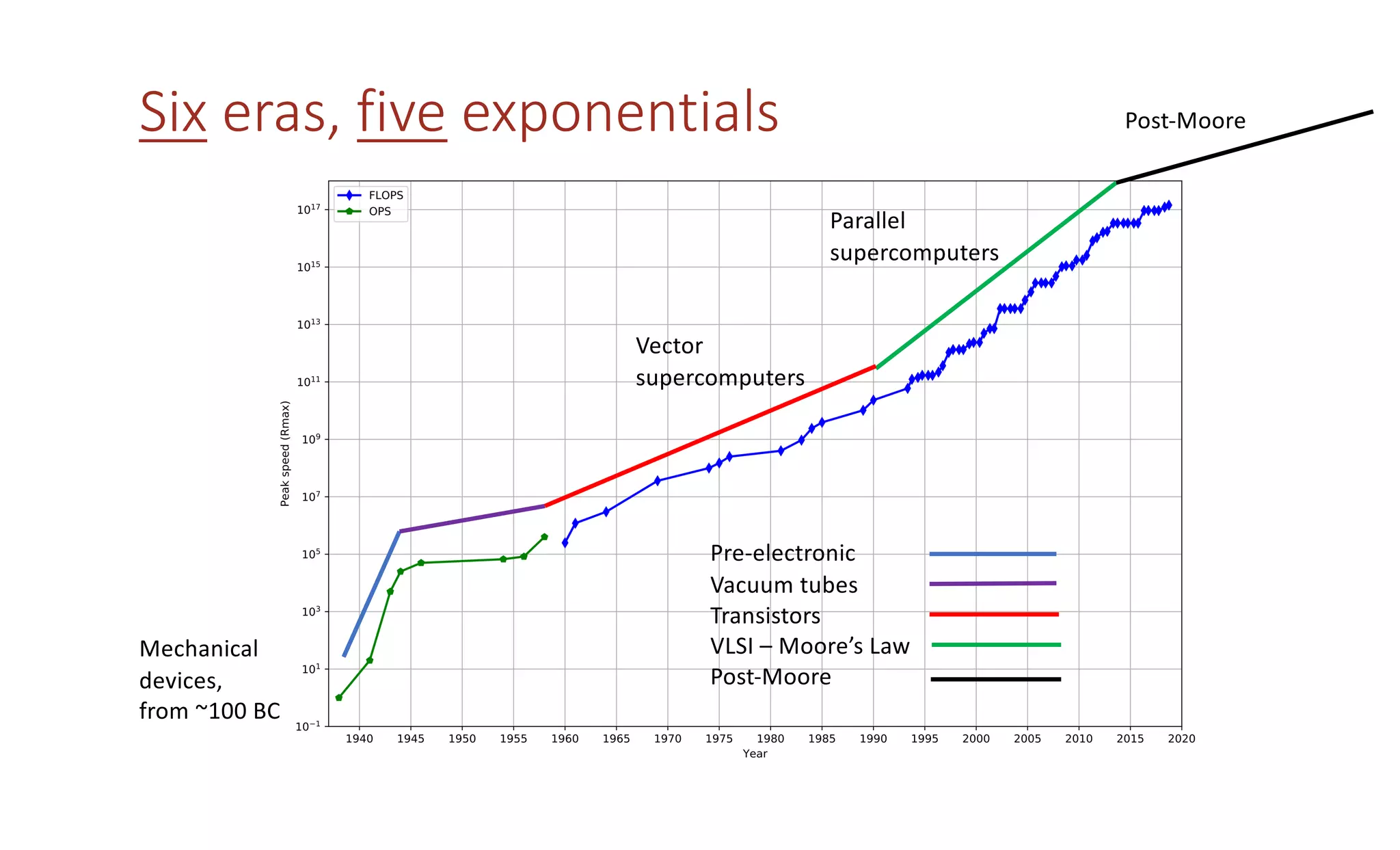



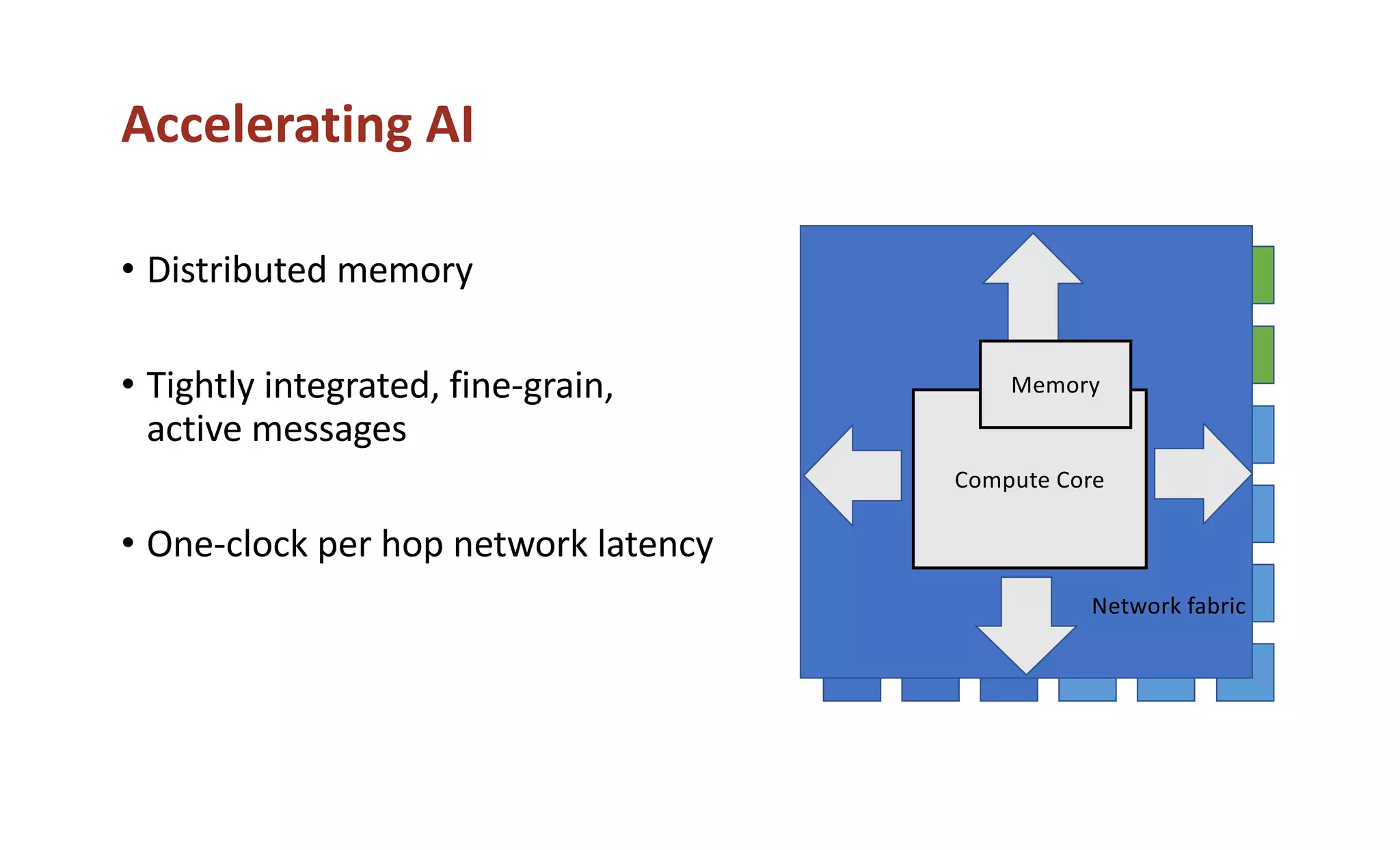



The document discusses how the parallel computing revolution is only half over. It summarizes the past eras of computing including pre-electronic, vacuum tubes, transistors, VLSI-Moore's law, and parallel supercomputers. It notes that Ivan Sutherland predicted in 1977 that the VLSI revolution was only half over. After 1990, commodity microprocessors took over high performance computing. Recent developments in AI have created a new demand for specialized computing architectures. Startups are now unveiling new deep learning processors using wafer-scale integration and other innovations to accelerate AI training.























































































