Download to read offline



























![A Data Parallel Example: Sorting7/17/200929void sort(int *src, int *dst,int size, intnvals) {inti, j, t1[nvals], t2[nvals]; for (j = 0 ; j < nvals ; j++) { t1[j] = 0;} for (i = 0 ; i < size ; i++) { t1[src[i]]++;} //t1[] now contains a histogram of the values t2[0] = 0; for (j = 1 ; j < nvals ; j++) { t2[j] = t2[j-1] + t1[j-1];} //t2[j] now contains the origin for value j for (i = 0 ; i < size ; i++) {dst[t2[src[i]]++] = src[i];}}](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-29-2048.jpg)
![When Is a Loop Parallelizable?The loop instances must safely interleaveA way to do this is to only read the data Another way is to isolate data accessesLook at the first loop:The accesses to t1[] are isolated from each other This loop can run in parallel “as is”7/17/200930for (j = 0 ; j < nvals ; j++) { t1[j] = 0;}](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-30-2048.jpg)
![Isolating Data UpdatesThe second loop seems to have a problem:Two iterations may access the same t1[src[i]]If both reads precede both increments, oops!A few ways to isolate the iteration conflicts:Use an “isolated update” (lock prefix) instructionUse an array of locks, perhaps as big as t1[] Use non-blocking updatesUse a transaction7/17/200931for (i = 0 ; i < size ; i++) { t1[src[i]]++;}](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-31-2048.jpg)
![Dependent Loop IterationsThe 3rd loop is an interesting challenge:Each iteration depends on the previous oneThis loop is an example of a prefix computationIf • is an associative binary operation on a set S, the • - prefixes of the sequence x0 ,x1 ,x2 … of values from S is x0,x0•x1,x0•x1•x2 …Prefix computations are often known as scansScan can be done in efficiently in parallel7/17/200932for (j = 1 ; j < nvals ; j++) { t2[j] = t2[j-1] + t1[j-1]; }](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-32-2048.jpg)



![The Sorting Example in OpenMPOnly the third “scan” loop is a problemWe can at least do this loop “manually”:7/17/200937nt = omp_get_num_threads();intta[nt], tb[nt];#omp parallel forfor(myt = 0; myt < nt; myt++) { //Set ta[myt]= local sum of nvals/nt elements of t1[] #pragmaomp barrier for(k = 1; k <= myt; k *= 2){tb[myt] = ta[myt];ta[myt] += tb[myt - k]; #pragmaomp barrier } fix = (myt > 0) ? ta[myt – 1] : 0; //Setnvals/ntelements of t2[] to fix + local scan of t1[]}](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-37-2048.jpg)
 { t1[j] = 0;});(void)_InterlockedIncrement(t1[src[i]]++);](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-38-2048.jpg)

{return e < pivot;}); auto mid2 = partition (mid1, last, [=](int e){return e == pivot;});parallel_invoke( [=] { quicksort(first, mid1); }, [=] { quicksort(mid2, last); } );}; 7/17/200940](https://image.slidesharecdn.com/20090720smith-100604130939-phpapp02/75/20090720-smith-40-2048.jpg)








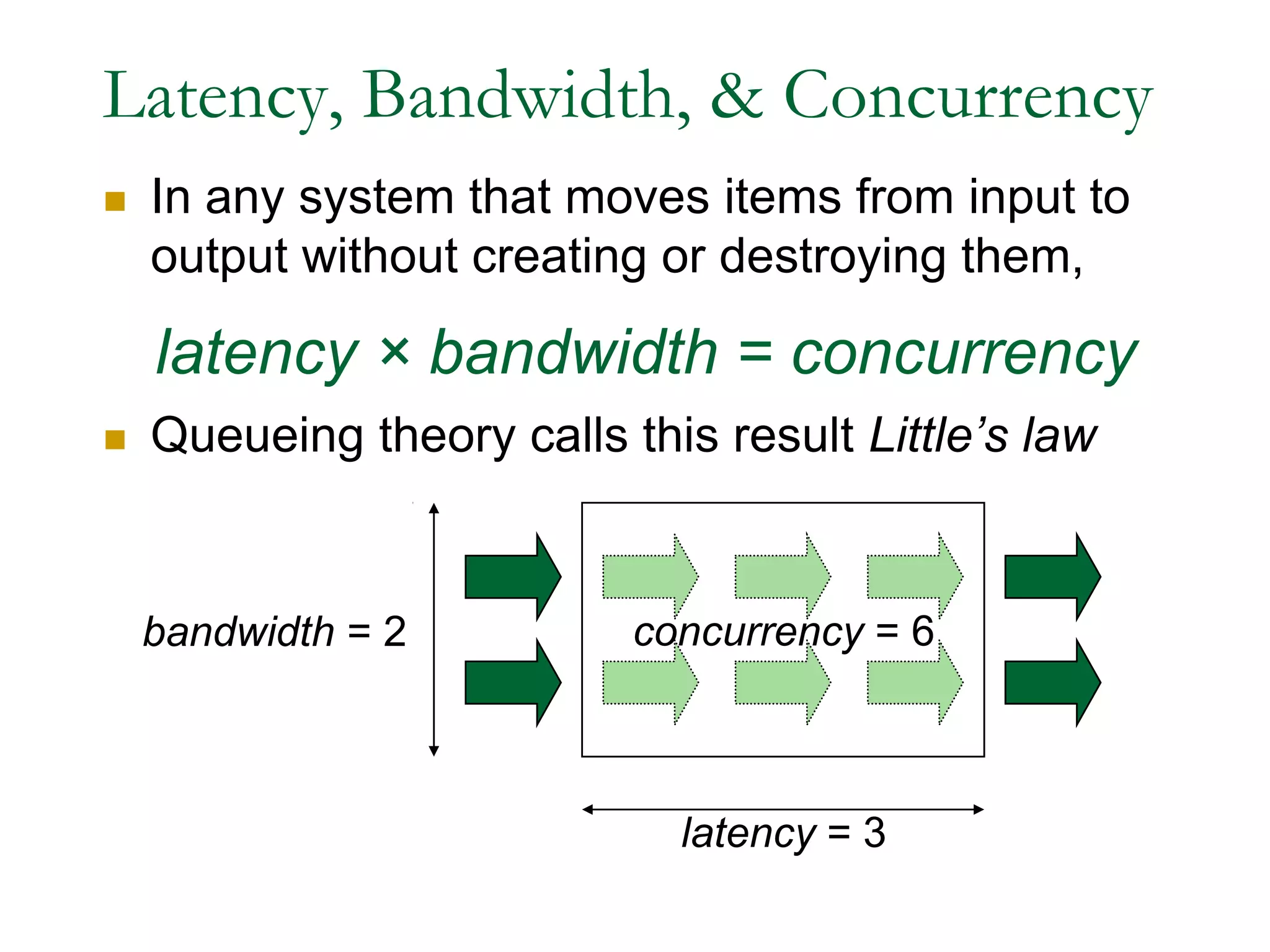
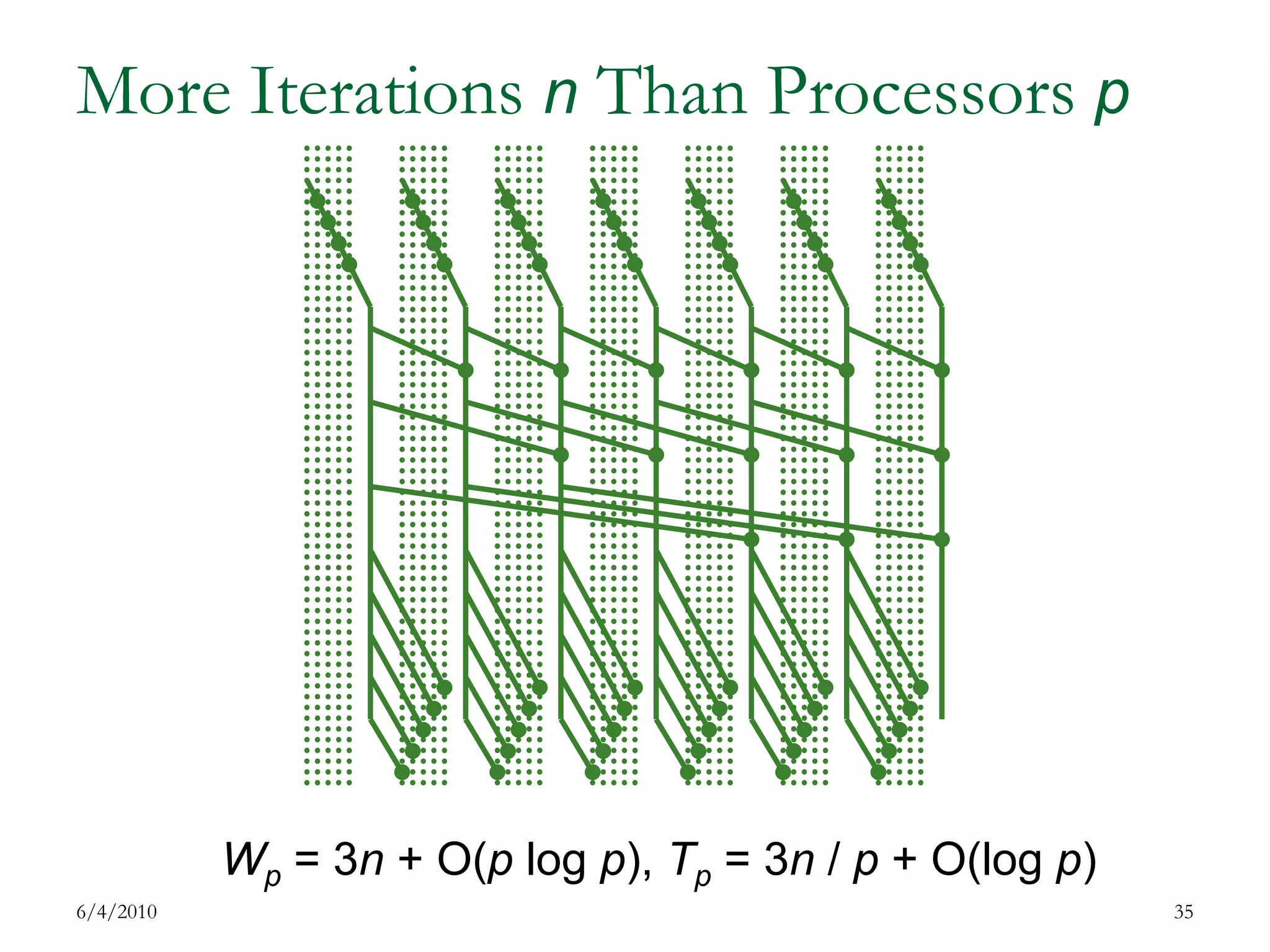
The document discusses parallel and high performance computing. It begins with definitions of key terms like parallel computing, high performance computing, asymptotic notation, speedup, work and time optimality, latency, bandwidth and concurrency. It then covers parallel architecture and programming models including SIMD, MIMD, shared and distributed memory, data and task parallelism, and synchronization methods. Examples of parallel sorting and prefix sums are provided. Programming models like OpenMP, PPL and work stealing are also summarized.


















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












