Download as PDF, PPTX








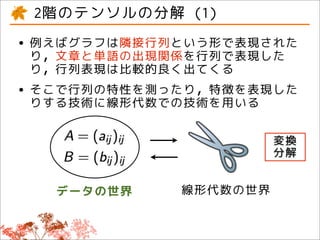





![octave-3.4.0:4> A = [1 2 3; 4 5 6; 7 8 9];
octave-3.4.0:5> [u v d] = svd(A);
octave-3.4.0:6> u
-0.21484 0.88723 0.40825
-0.52059 0.24964 -0.81650
-0.82634 -0.38794 0.40825
octave-3.4.0:7> v
1.6848e+01 0 0
0 1.0684e+00 0
0 0 1.4728e-16
octave-3.4.0:8> d
-0.479671 -0.776691 0.408248
-0.572368 -0.075686 -0.816497
-0.665064 0.625318 0.408248](https://image.slidesharecdn.com/ml-tensor-output-111025043403-phpapp02/85/Tensor-Decomposition-and-its-Applications-14-320.jpg)





![Penrose inverse (i.e., A = ( A A) A ) of Kronecker
and Khatri–Rao products are THE TUCKER AND
CANDECOMP/PARAFAC MODELS
( P ⊗ Q)† = ( P † ⊗ Q† ) (11)
The two most widely used tensor decomposition
methods are the Tucker model29 and Canonical De-
(A B)† = [( A A)∗ (B B)]−1 ( A B) (12)
composition (CANDECOMP)30 also known as Parallel
where ∗ denotes elementwise multiplication. Factor Analysis (PARAFAC)31 jointly abbreviated CP.
This reduces the complexity from O(J 3 L3 ) In the following section, we describe the models for
T A B L E 1 Summary of the Utilized Variables and Operations. X , X, x, and x are Used to Denote
Tensors, Matrices, Vectors, and Scalars Respectively.
Operator Name Operation
A, B Inner product A, B = i , j ,k a i , j ,k bi , j ,k
√
A F Frobenius norm A, A
I n × I · I ··· I · I ··· I
X(n ) Matricizing X I 1 × I 2 ×...× I N → X (n ) 1 2 n −1 n +1 N
×n or •n n-mode product X ×n M = Z where Z(n ) = MX (n )
◦ outer product a ◦ b = Z where z i , j = a i b j
⊗ Kronecker product A ⊗ B = Z where z k + K (i −1),l + L ( j −1) = a i j bkl
or | ⊗ | Khatri–Rao product A B = Z, where z k + K (i −1), j = a i j bk j .
kA k-rank Maximal number of columns of A guaranteed to be linearly independent.
26 c 2011 John Wiley & Sons, Inc. Volume 1, January/February 2011
(本文中より引用)](https://image.slidesharecdn.com/ml-tensor-output-111025043403-phpapp02/85/Tensor-Decomposition-and-its-Applications-21-320.jpg)

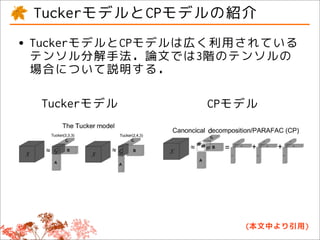

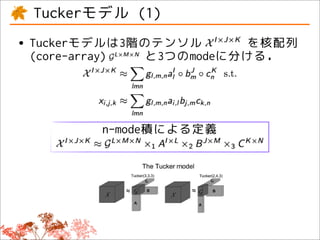





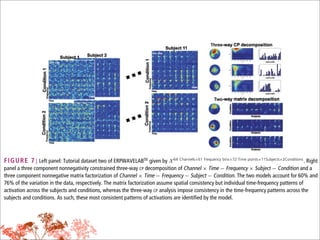


This document discusses tensor factorizations and decompositions and their applications in data mining. It introduces tensors as multi-dimensional arrays and covers 2nd order tensors (matrices) and 3rd order tensors. It describes how tensor decompositions like the Tucker model and CANDECOMP/PARAFAC (CP) model can be used to decompose tensors into core elements to interpret data. It also discusses singular value decomposition (SVD) as a way to decompose matrices and reduce dimensions while approximating the original matrix.



![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)














































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











