Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Keisuke OTAKI
PPTX, PDF
945 views
Hash Table
Introduction to Algorithms, section11 Hash Table.
Technology
◦
Education
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 18 times
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PPTX
Hash functions
by
tabun_muri
PPTX
HashMapとは?
by
Trash Briefing ,Ltd
PDF
Hash mapとは
by
Kuroiwa Takumi
PPT
アルゴリズムとデータ構造10
by
Kenta Hattori
PPT
アルゴリズムとデータ構造9
by
Kenta Hattori
PDF
[アルゴリズムイントロダクション勉強会] ハッシュ
by
Rei Takami
PDF
数学を数学で数学した人々
by
Akira Yamaguchi
PDF
Divisor
by
Ken Ogura
Hash functions
by
tabun_muri
HashMapとは?
by
Trash Briefing ,Ltd
Hash mapとは
by
Kuroiwa Takumi
アルゴリズムとデータ構造10
by
Kenta Hattori
アルゴリズムとデータ構造9
by
Kenta Hattori
[アルゴリズムイントロダクション勉強会] ハッシュ
by
Rei Takami
数学を数学で数学した人々
by
Akira Yamaguchi
Divisor
by
Ken Ogura
What's hot
PPT
アルゴリズムとデータ構造6
by
Kenta Hattori
PDF
Rustで始める競技プログラミング
by
Naoya Okanami
PDF
関数の最小値を求めることから機械学習へ
by
Hiro H.
PDF
アルゴリズム+データ構造勉強会(9)
by
noldor
PDF
programming camp 2008, introduction of programming, algorithm
by
Hiro Yoshioka
PDF
圏とHaskellの型
by
KinebuchiTomo
PDF
Haskell勉強会 in ie
by
maeken2010
PDF
圏論のモナドとHaskellのモナド
by
Yoshihiro Mizoguchi
PDF
Python勉強会3-コレクションとファイル
by
理 小林
PPTX
圏論とHaskellは仲良し
by
ohmori
PDF
自動定理証明の紹介
by
Masahiro Sakai
PDF
代数的実数とCADの実装紹介
by
Masahiro Sakai
PPTX
mathemaical_notation
by
Kenta Oono
アルゴリズムとデータ構造6
by
Kenta Hattori
Rustで始める競技プログラミング
by
Naoya Okanami
関数の最小値を求めることから機械学習へ
by
Hiro H.
アルゴリズム+データ構造勉強会(9)
by
noldor
programming camp 2008, introduction of programming, algorithm
by
Hiro Yoshioka
圏とHaskellの型
by
KinebuchiTomo
Haskell勉強会 in ie
by
maeken2010
圏論のモナドとHaskellのモナド
by
Yoshihiro Mizoguchi
Python勉強会3-コレクションとファイル
by
理 小林
圏論とHaskellは仲良し
by
ohmori
自動定理証明の紹介
by
Masahiro Sakai
代数的実数とCADの実装紹介
by
Masahiro Sakai
mathemaical_notation
by
Kenta Oono
Viewers also liked
PPTX
Presentation missouri
by
feoropeza
PPTX
õPpeinfosüSteemi üHildamine E õPpe Keskkondadega üHe üLikooli õI Si NäItel
by
Maret Mõis
PDF
Grayling foreign-investment-think-piece june-2011
by
Pavel Melnikov
DOCX
Tenth Draft Dr. Cotter
by
feoropeza
PPTX
El costo de la anticipación
by
UNAH CUROC
PDF
Direccion escolar efectiva_elsalvador
by
I GARITA
PPT
Meraviglioso
by
guest2a927f
DOC
Virtual team tools
by
Ladies Who Launch Atlanta
DOC
Firewall corewp
by
Jorge Huamán
PDF
Foilsを使ってみた。
by
Keisuke OTAKI
PDF
Perkembangan asuransi syariah di indonesia 2012
by
Wiku Suryomurti
PPTX
Pingüí
by
mertxita
PPT
Social Media Basics
by
LP Life Coach
PPT
Coworking Europe 2012 París
by
Working Space
PPTX
What is art?
by
mertxita
PDF
Think piece pharma 2020 june 2010
by
Pavel Melnikov
PDF
Presentation
by
s1170006
PDF
Presentation
by
s1170006
PDF
Em
by
Keisuke OTAKI
PPT
Natalia Zubarevich - Russian regions - September 2014
by
Pavel Melnikov
Presentation missouri
by
feoropeza
õPpeinfosüSteemi üHildamine E õPpe Keskkondadega üHe üLikooli õI Si NäItel
by
Maret Mõis
Grayling foreign-investment-think-piece june-2011
by
Pavel Melnikov
Tenth Draft Dr. Cotter
by
feoropeza
El costo de la anticipación
by
UNAH CUROC
Direccion escolar efectiva_elsalvador
by
I GARITA
Meraviglioso
by
guest2a927f
Virtual team tools
by
Ladies Who Launch Atlanta
Firewall corewp
by
Jorge Huamán
Foilsを使ってみた。
by
Keisuke OTAKI
Perkembangan asuransi syariah di indonesia 2012
by
Wiku Suryomurti
Pingüí
by
mertxita
Social Media Basics
by
LP Life Coach
Coworking Europe 2012 París
by
Working Space
What is art?
by
mertxita
Think piece pharma 2020 june 2010
by
Pavel Melnikov
Presentation
by
s1170006
Presentation
by
s1170006
Em
by
Keisuke OTAKI
Natalia Zubarevich - Russian regions - September 2014
by
Pavel Melnikov
Similar to Hash Table
PDF
PFI Seminar 2012/03/15 カーネルとハッシュの機械学習
by
Preferred Networks
PDF
PFDS 5.5 Pairing heap
by
昌平 村山
PDF
Swiss Table の実装に Deep Dive ! 〜 Go Conference 2025 〜
by
Keisuke Ishigami
PPTX
202007勉強会資料 ストリームアルゴリズム
by
Makoto Kataigi
PDF
K2PC Div1 E 暗号化
by
Kazuma Mikami
PDF
Rolling Hashを殺す話
by
Nagisa Eto
PPTX
A Fast and Space-Efficient Algorithm for Calculating Deficient Numbers (a.k.a...
by
Cryolite
PDF
HashTable と HashDos
by
Yuya Takeyama
PFI Seminar 2012/03/15 カーネルとハッシュの機械学習
by
Preferred Networks
PFDS 5.5 Pairing heap
by
昌平 村山
Swiss Table の実装に Deep Dive ! 〜 Go Conference 2025 〜
by
Keisuke Ishigami
202007勉強会資料 ストリームアルゴリズム
by
Makoto Kataigi
K2PC Div1 E 暗号化
by
Kazuma Mikami
Rolling Hashを殺す話
by
Nagisa Eto
A Fast and Space-Efficient Algorithm for Calculating Deficient Numbers (a.k.a...
by
Cryolite
HashTable と HashDos
by
Yuya Takeyama
More from Keisuke OTAKI
PDF
KDD読み会(図なし版)
by
Keisuke OTAKI
PDF
Reading Seminar (140515) Spectral Learning of L-PCFGs
by
Keisuke OTAKI
PDF
一階述語論理のメモ
by
Keisuke OTAKI
PDF
Grammatical inference メモ 1
by
Keisuke OTAKI
PDF
ベイジアンネットワーク入門
by
Keisuke OTAKI
PDF
Tensor Decomposition and its Applications
by
Keisuke OTAKI
PDF
Ada boost
by
Keisuke OTAKI
PDF
PRML§12-連続潜在変数
by
Keisuke OTAKI
PDF
Prml sec6
by
Keisuke OTAKI
PDF
ウェーブレット勉強会
by
Keisuke OTAKI
PDF
Prml sec3
by
Keisuke OTAKI
PDF
Sec16 greedy algorithm no2
by
Keisuke OTAKI
PDF
Sec16 greedy algorithm no1
by
Keisuke OTAKI
PDF
Sec15 dynamic programming
by
Keisuke OTAKI
KDD読み会(図なし版)
by
Keisuke OTAKI
Reading Seminar (140515) Spectral Learning of L-PCFGs
by
Keisuke OTAKI
一階述語論理のメモ
by
Keisuke OTAKI
Grammatical inference メモ 1
by
Keisuke OTAKI
ベイジアンネットワーク入門
by
Keisuke OTAKI
Tensor Decomposition and its Applications
by
Keisuke OTAKI
Ada boost
by
Keisuke OTAKI
PRML§12-連続潜在変数
by
Keisuke OTAKI
Prml sec6
by
Keisuke OTAKI
ウェーブレット勉強会
by
Keisuke OTAKI
Prml sec3
by
Keisuke OTAKI
Sec16 greedy algorithm no2
by
Keisuke OTAKI
Sec16 greedy algorithm no1
by
Keisuke OTAKI
Sec15 dynamic programming
by
Keisuke OTAKI
Hash Table
1.
Introduction To Algorithms.§11.
Hash Tables.2010 / 06
2.
Why Hash Tables
?探索したい @配列
3.
先頭にあれば… O(1)
4.
末尾にあれば… O(N)
5.
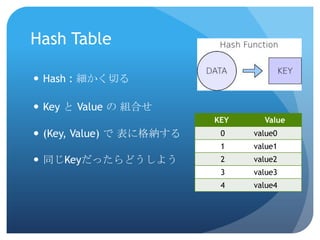
いつもO(1)ぐらいだったら嬉しいHash TableHash :
細かく切る
6.
Key と Value
の 組合せ
7.
(Key, Value) で
表に格納する
8.
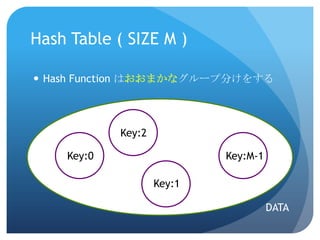
同じKeyだったらどうしようHash Table (
SIZE M )同じKeyが出にくい方がいい
9.
出来れば高速で計算して…
10.
F : Data
-> { 0, 1, 2, … , M-1 }Hash Table ( SIZE M )Hash Function はおおまかなグループ分けをするKey:2Key:0Key:M-1Key:1DATA
11.
Example.人の誕生日を覚える(1〜31)
12.
同じ日の人って…そんなにいないはず
13.
M = 7
: 素数
14.
経験的に素数を使う方がいいらしい
15.
数字の総和 mod 7
を 関数に使うExample.
16.
Question.Keyが重複したときの対処方法
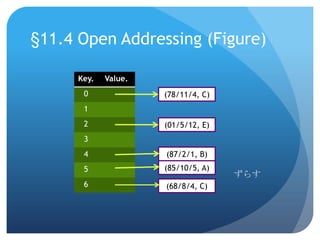
17.
チェイン法/クローズドハッシュ法
18.
どんなハッシュ関数がいいのかここから本文(?)
19.
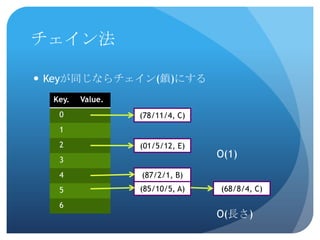
チェイン法Keyが同じならチェイン(鎖)にする(78/11/4, C)(01/5/12, E)O(1)(87/2/1,
B)(85/10/5, A)(68/8/4, C)O(長さ)
20.
§11.2〜データの個数n , 表の大きさm
21.
一つのチェイン長は平均してn / m
= α : 占有率
22.
仮定:ハッシュ関数はすぐ計算出来る O(1)
23.
そのまま挿入出来る or リストをたどる
24.
O( 1 +
α )§11.3.1 The Division Method大前提1. 同じKeyがなかなか出ない
25.
大前提2. 上手くばらける
26.
Mod: 割り算だけなので高速
27.
(再掲)経験的に素数を使う方がいいらしい§11.3.2 The Multiplication
MethodHash(k) = floor( m ( k A mod 1 ) ) , 0 < A < 1
Download






























![[アルゴリズムイントロダクション勉強会] ハッシュ](https://cdn.slidesharecdn.com/ss_thumbnails/random-171021132555-thumbnail.jpg?width=640&height=640&fit=bounds)
























































