[DL輪読会]DropBlock: A regularization method for convolutional networks
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
DropBlock: A regularization method for convolutional
networks [NIPS2018]
Masashi Yokota, RESTAR inc.
2.
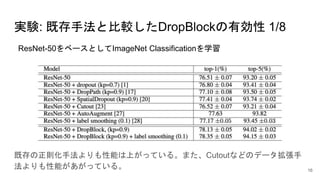
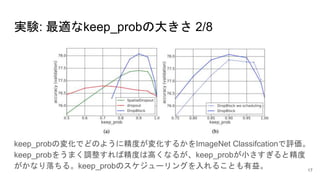
書誌情報
著者: Golnaz Ghiasi,Tsung-Yi Lin, Quoc V. Le
所属: GoogleBrain
採択会議: NIPS 2018
選定理由:
手法がシンプルかつ実験内容や分析内容が非常に面白かったため。
(ザックリと紹介していなくて恐縮ですが)Dropout関連の関連研究をしっかりサー
ベイしたかったので。
2
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
DropBlock: A regularization method for convolutional
networks [NIPS2018]
Masashi Yokota, RESTAR inc.](https://image.slidesharecdn.com/dlyokota20190222-190222002832/85/DL-DropBlock-A-regularization-method-for-convolutional-networks-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
DropBlock: A regularization method for convolutional
networks [NIPS2018]
Masashi Yokota, RESTAR inc.](https://image.slidesharecdn.com/dlyokota20190222-190222002832/75/DL-DropBlock-A-regularization-method-for-convolutional-networks-1-2048.jpg)



![● Variational Dropout [Kingma+ 2015]
○ Dropoutを変分アプローチの元で再解釈。
データに基づいてドロップ確率の決定が可能
○ 参考: 鈴木さんの過去発表
https://www.slideshare.net/masa_s/dl-hacks-variational-dropout-and-the-local-
reparameterization-trick
● Information Dropout [Achille+ 2017]
○ Information Bottlenecの観点からDropoutを一般化。
以下の式のように入力xに対して各ユニットのドロップする確率を求める。
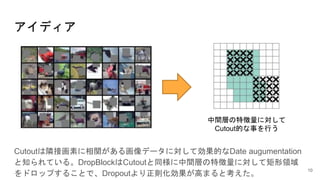
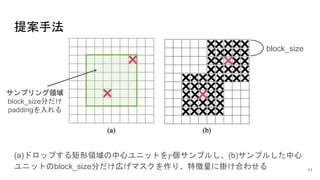
先行研究 ~ピクセルをドロップ①~ 1/4
5](https://image.slidesharecdn.com/dlyokota20190222-190222002832/85/DL-DropBlock-A-regularization-method-for-convolutional-networks-5-320.jpg)
![先行研究 ~ピクセルをドロップ②~ 2/4
● Alpha-Dropout [Klambauer+ NIPS2017]
○ SELUと一緒に提案されたDropout。self-normalizingの性質を担保するために入力
のもともとの値の平均と分散を保持しつつドロップする。SELU一緒に用いる
○ 参考: 若杉さんの過去発表
https://www.slideshare.net/DeepLearningJ
P2016/dlselfnormalizing-neural-networks
● Guided Dropout [Alemi+ AAAI2019 ]
○ 推論に強く寄与しているノードをドロップ
することで学習が不十分なノードの学習を
集中的に行う。どのノードをドロップするかも
学習によって最適化している。 Guided Dropoutの概要図
6](https://image.slidesharecdn.com/dlyokota20190222-190222002832/85/DL-DropBlock-A-regularization-method-for-convolutional-networks-6-320.jpg)
![先行研究 ~ピクセル以外をドロップ~ 3/4
● SpatialDropout [Tompson+ CVPR2015]
○ チャネル全体を確率的にドロップ
● StocasticDepth [Huang+ ECCV2016]
○ ResNetにおいてBlockを確率的にドロップ
● DropPath [Larsson+ ICLR2017]
○ 複数ブランチが生えているモデルに対して
ブランチのpathを確率的にドロップ
7](https://image.slidesharecdn.com/dlyokota20190222-190222002832/85/DL-DropBlock-A-regularization-method-for-convolutional-networks-7-320.jpg)
![先行研究 ~その他~ 4/4
● ZoneOut [IKrueger+ CLR2017]
○ RNNに特化した正則化手法。RNNの
セル/出力の更新を確率的に行うことで、
RNNに対して正則化を行う。
● Shake-Shake Regularization [Gastaldi+ ICLR2017]
○ 2つのブランチのforwardとbackward双方で
外乱を加えることで、擬似的にデータ拡張
のような効果を与える
● ShakeDrop Regularization [Yamada+ ICLR2018]
○ StocasticDepthのようなパスのスキップと
shake-shakeの外乱の双方をforwardと
backward双方に入れている 8](https://image.slidesharecdn.com/dlyokota20190222-190222002832/85/DL-DropBlock-A-regularization-method-for-convolutional-networks-8-320.jpg)










![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL Hacks]Shake-Shake regularization Improved Regularization of Convolutional...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackshakeshake-180516080948-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICLR2016] 採録論文の個人的まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2016-acceptedpapers-160209033749-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




















