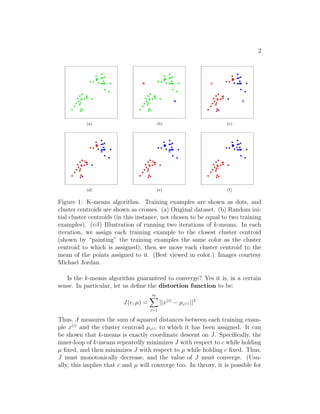
The document summarizes the k-means clustering algorithm. It describes how k-means aims to group data into k clusters by minimizing the distance between data points and their assigned cluster centroid. The algorithm works by iteratively assigning points to the closest centroid and moving each centroid to the mean of its assigned points until convergence. While k-means converges, finding the global minimum is not guaranteed as it can get stuck in local optima, so it is best to run it multiple times.