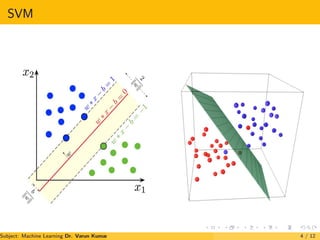
1. Support vector machine is a supervised machine learning algorithm that constructs a hyperplane or set of hyperplanes to classify data points.
2. It finds the optimal hyperplane that separates classes of data points by maximizing the margin between the closest data points of each class.
3. The optimal hyperplane is the one that maximizes the margin of separation between the different classes and minimizes the risk of misclassifying new data points.