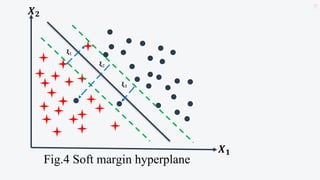
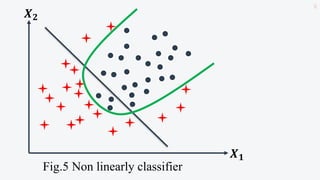
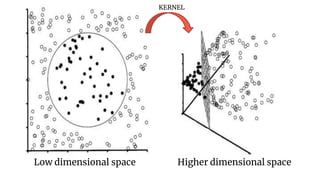
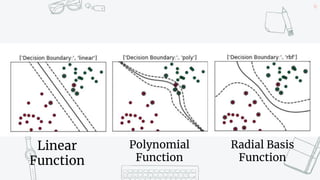
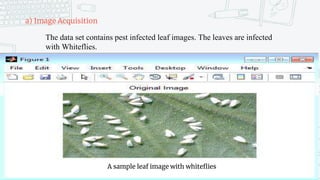
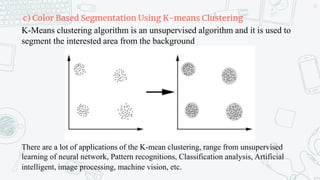
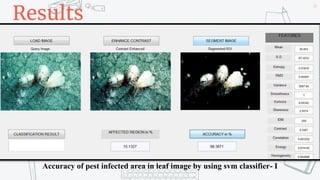
This document discusses support vector machines (SVMs) and their application in agriculture. It begins with an introduction to SVMs, explaining that they are a supervised machine learning algorithm used for classification and regression. The document then covers key aspects of SVMs including: how they find the optimal separating hyperplane for classification; handling linearly separable and non-separable data using soft-margin hyperplanes and kernels; and common kernel functions. It provides an example application of using an SVM classifier to identify pests in leaf images. In conclusion, the document provides an overview of SVMs and their use in solving agricultural classification problems.









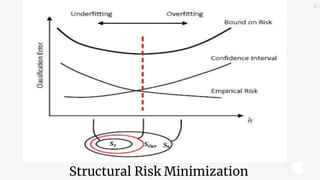
![Principle of SVM
o The formulation of SVM learning is based on the
principle of Structural Risk Minimization[SRM]
(Vapnik, 2000).
o SVM allows to maximize the generalization ability of a
model. This is the objective of the SRM principle that
allows the minimization of a bound on the
generalization error of a model, instead of minimizing
the mean squared error on the set of training data,
which is often used by empirical risk minimization.
9](https://image.slidesharecdn.com/supportvectormachine-220425094331/85/Support-Vector-Machine-pptx-9-320.jpg)

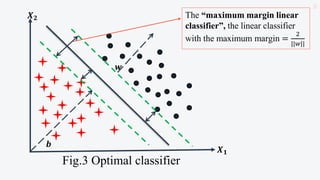
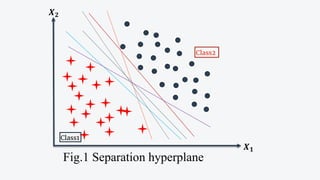
![Linearly separable case
o Each dataset consists of a pair, an vector 𝑥𝑖
(input vector) and the associated label 𝑦𝑖.
o Let training set 𝑋 be:
𝑥1, 𝑦1 , 𝑥2, 𝑦2 , …, 𝑥𝑛, 𝑦𝑛
i.e., 𝑋 = 𝑥𝑖, 𝑦𝑖 𝑖=1
𝑛
where 𝑥𝑖 ∈ 𝑅𝑑
[d-dimensions]
and 𝑦𝑖∈ +1, −1 .
12](https://image.slidesharecdn.com/supportvectormachine-220425094331/85/Support-Vector-Machine-pptx-12-320.jpg)


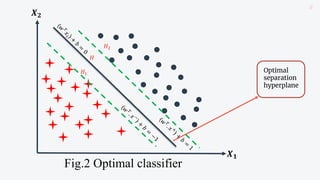
![Cont...
o The hyperplane that separates the input space is
defined by the equation
𝑤𝑇
𝑥𝑖 + 𝑏 = 0 …(1) [𝑖 = 1, … , 𝑁]
o It can be fitted to correctly classify training
patterns, where
a. The weight vector ‘𝑤’ is normal to the hyperplane,
and defines its orientation,
b. ‘𝑏’ is the bias term and
c. ‘T’ is the transpose
17](https://image.slidesharecdn.com/supportvectormachine-220425094331/85/Support-Vector-Machine-pptx-17-320.jpg)