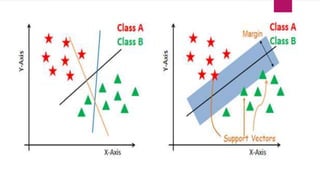
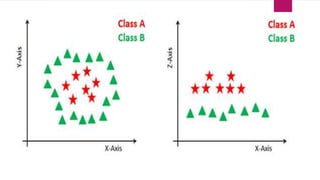
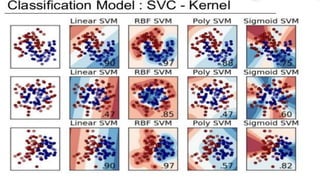
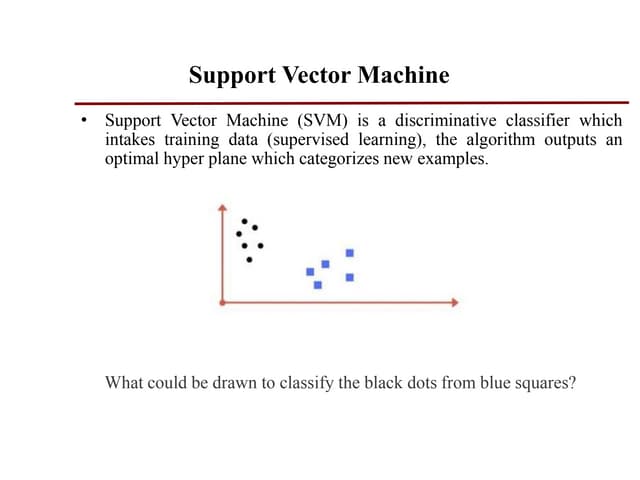
The document provides an overview of Support Vector Machines (SVM), detailing its functionality, including how it constructs hyperplanes to separate classes in datasets. It explains the kernel trick used to handle non-linear and inseparable problems, along with various types of kernels such as linear, polynomial, and radial basis function. The advantages of SVM include good accuracy and faster predictions, while its disadvantages highlight challenges with large datasets and overlapping classes.




















































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)

























