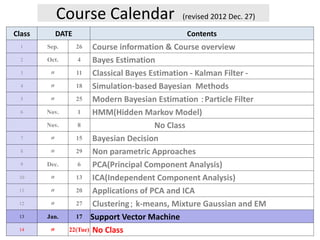
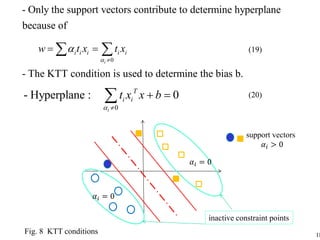
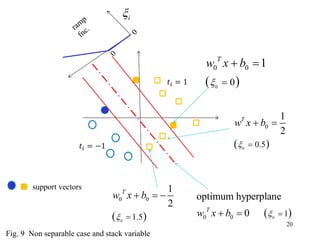
The document provides a course calendar for a class on Bayesian estimation methods. It lists the dates and topics to be covered over 15 class periods from September to January. The topics progress from basic concepts like Bayes estimation and the Kalman filter, to more modern methods like particle filters, hidden Markov models, Bayesian decision theory, and applications of principal component analysis and independent component analysis. One class is noted as having no class.












![23
2
2 2
1 1 2 2 1 2
) Polynomial kernel
, 1
where 1, , 2 , , 2 , 2
T T
T
Ex
K u v u v u v
v u u u u u u
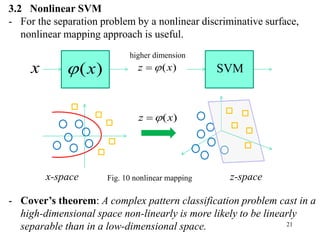
Ex) Nonlinear SVM result by utilizing Gauss kernel
Fig. 11
Support vectors
Bishop [1]](https://image.slidesharecdn.com/2012mdsp-pr13supportvectormachine-130701022429-phpapp02/85/2012-mdsp-pr13-support-vector-machine-23-320.jpg)
![24
References:
[1] C. M. Bishop, “Pattern Recognition and Machine Learning”,
Springer, 2006
[2] R.O. Duda, P.E. Hart, and D. G. Stork, “Pattern Classification”,
John Wiley & Sons, 2nd edition, 2004
[3] 平井有三 「はじめてのパターン認識」森北出版(2012年)](https://image.slidesharecdn.com/2012mdsp-pr13supportvectormachine-130701022429-phpapp02/85/2012-mdsp-pr13-support-vector-machine-24-320.jpg)







































































