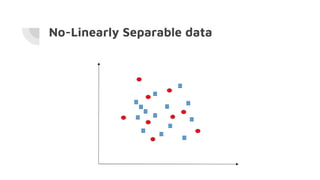
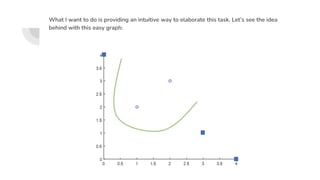
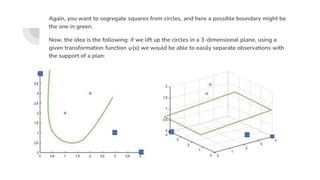
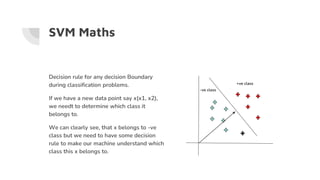
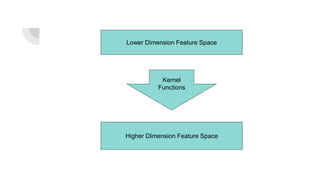
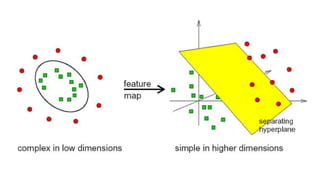
Support Vector Machines (SVM) find the optimal separating hyperplane that maximizes the margin between two classes of data points. The hyperplane is chosen such that it maximizes the distance from itself to the nearest data points of each class. When data is not linearly separable, the kernel trick can be used to project the data into a higher dimensional space where it may be linearly separable. Common kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid kernels. Soft margin SVMs introduce slack variables to allow some misclassification and better handle non-separable data. The C parameter controls the tradeoff between margin maximization and misclassification.










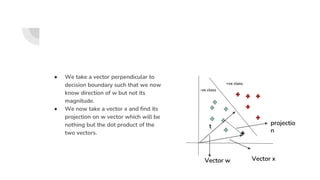

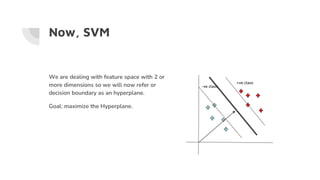
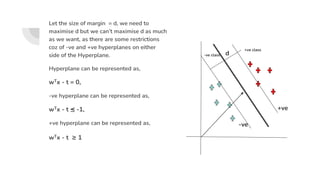

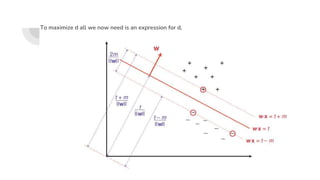






















![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)







































