Download as PDF, PPTX








![sparkContext.textFile(“hdfs://…”)
.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
[reduceByKey or groupByKey]
...
What’s Happening in Word Count
Same
Worker
Node
Triggers
a shuffle
of data
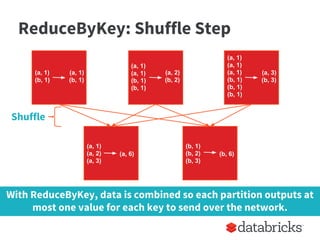
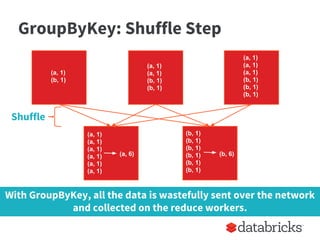
Shuffle occurs to transfer all data with the same key
to the same worker node.](https://image.slidesharecdn.com/stratasj-everydayimshuffling-tipsforwritingbettersparkprograms-150223113317-conversion-gate02/85/Everyday-I-m-Shuffling-Tips-for-Writing-Better-Spark-Programs-Strata-San-Jose-2015-8-320.jpg)















![Reuse Code on Batch & Streaming
val ips = logs.transform
(extractIp)
def extractIp(
logs: RDD[String]) = {
logs.map(_.split(“ “)(0))
}
val ips = extractIp(logs)
Streaming Batch
Use transform on a DStream to reuse your RDD to RDD functions
from your batch Spark jobs.](https://image.slidesharecdn.com/stratasj-everydayimshuffling-tipsforwritingbettersparkprograms-150223113317-conversion-gate02/85/Everyday-I-m-Shuffling-Tips-for-Writing-Better-Spark-Programs-Strata-San-Jose-2015-31-320.jpg)



![Simplest - Unit Test Functions
instead of:
val splitLines = inFile.map(line => {
val reader = new CSVReader(new StringReader(line))
reader.readNext()
})
write:
def parseLine(line: String): Array[Double] = {
val reader = new CSVReader(new StringReader(line))
reader.readNext().map(_.toDouble)
}
then we can:
test("should parse a csv line with numbers") {
MoreTestableLoadCsvExample.parseLine("1,2") should equal
(Array[Double](1.0, 2.0))
}](https://image.slidesharecdn.com/stratasj-everydayimshuffling-tipsforwritingbettersparkprograms-150223113317-conversion-gate02/85/Everyday-I-m-Shuffling-Tips-for-Writing-Better-Spark-Programs-Strata-San-Jose-2015-35-320.jpg)
![Testing with RDDs
trait SSC extends BeforeAndAfterAll { self: Suite =>
@transient private var _sc: SparkContext = _
def sc: SparkContext = _sc
var conf = new SparkConf(false)
override def beforeAll() {
_sc = new SparkContext("local[4]", "test", conf)
super.beforeAll()
}
override def afterAll() {
LocalSparkContext.stop(_sc)
_sc = null
super.afterAll()
}
}](https://image.slidesharecdn.com/stratasj-everydayimshuffling-tipsforwritingbettersparkprograms-150223113317-conversion-gate02/85/Everyday-I-m-Shuffling-Tips-for-Writing-Better-Spark-Programs-Strata-San-Jose-2015-36-320.jpg)

)
}](https://image.slidesharecdn.com/stratasj-everydayimshuffling-tipsforwritingbettersparkprograms-150223113317-conversion-gate02/85/Everyday-I-m-Shuffling-Tips-for-Writing-Better-Spark-Programs-Strata-San-Jose-2015-38-320.jpg)


}
}](https://image.slidesharecdn.com/stratasj-everydayimshuffling-tipsforwritingbettersparkprograms-150223113317-conversion-gate02/85/Everyday-I-m-Shuffling-Tips-for-Writing-Better-Spark-Programs-Strata-San-Jose-2015-40-320.jpg)





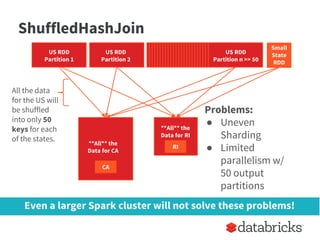
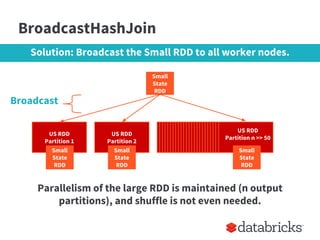
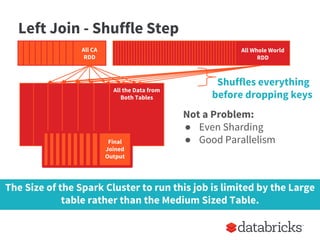
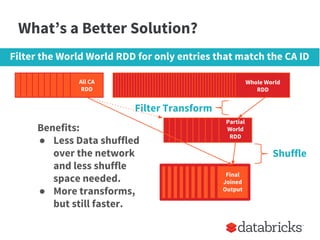
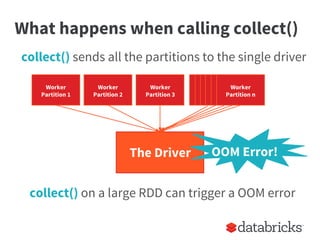
The document provides insights on optimizing Apache Spark jobs by understanding key functional elements such as shuffling, appropriate use of operations like reduceByKey versus groupByKey, and how to handle joins effectively. It emphasizes the importance of understanding Spark's internal workings to write efficient, well-tested, and reusable jobs while highlighting common pitfalls and best practices. Additionally, it discusses strategies for reusing code between batch and streaming processes, testing scenarios in Spark, and diagnosing performance issues.






























































































