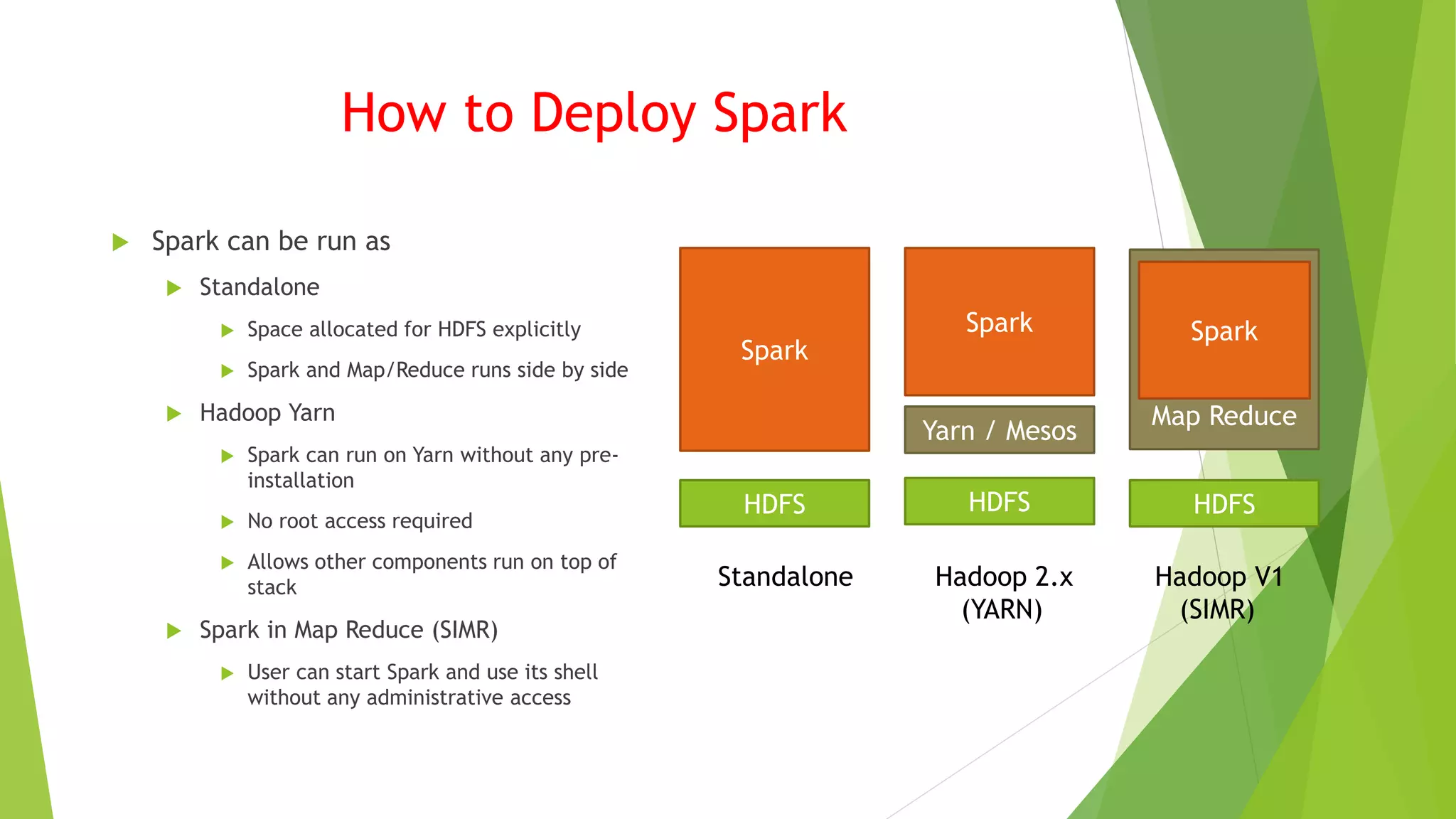
Spark is a fast and general engine for large-scale data processing. It runs programs up to 100x faster than Hadoop in memory, and 10x faster on disk. Spark supports Scala, Java, Python and can run on standalone, YARN, or Mesos clusters. It provides high-level APIs for SQL, streaming, machine learning, and graph processing.






![Example
Let’s see how we use Spark for some basic data analysis
./bin/spark=shell
scala> val tFile = sc.textFile(“c:/input/names.txt”)
First RDD created:
tFile : org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:
21
scala> tFile.count()
Res0: Long = 37
scala> tFile.first()
Res1: String = John](https://image.slidesharecdn.com/9efcdd3c-b17f-489f-9877-71374986c4ae-151123011009-lva1-app6892/75/SparkNotes-8-2048.jpg)
![Transformation Example
Now lets try a transformation to create a new RDD with filter() we will search for lines with a
specific name “Ted”
val linesWithSpark = tFile.filter(line=> line.contains(“Ted”)
linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitions[2] at filter at <console>: 23
Remember it is a lazy protocol before explicitly told no operations are performed
linesWithSpark.count()
Res2: Long=1
Only 1 line has the name “Ted”
linesWithSpark = tFile.filter(line => line.contains(“A”)).count();
<Console>: 25: error reassignment to val // as RDDs are immutable
tFile.filter(line => line.contains(“A”)).count();
Res4: Long = 6
car linesWithSpark2 = tFile.filter(line => line.contains(“A”)).count();
linesWithSpark2: Long=6
* Note how we accumulate new RDDs in memory](https://image.slidesharecdn.com/9efcdd3c-b17f-489f-9877-71374986c4ae-151123011009-lva1-app6892/75/SparkNotes-9-2048.jpg)













































