Download to read offline














![So what does that look like?
(94110, A, B)
(94110, A, C)
(10003, D, E)
(94110, E, F)
(94110, A, R)
(10003, A, R)
(94110, D, R)
(94110, E, R)
(94110, E, R)
(67843, T, R)
(94110, T, R)
(94110, T, R)
(67843, T, R)(10003, A, R)
(94110, [(A, B), (A, C), (E, F), (A, R), (D, R), (E, R), (E, R), (T, R) (T, R)]
Tomomi](https://image.slidesharecdn.com/spark-chug20161-160913010424/85/Apache-Spark-Super-Happy-Funtimes-CHUG-2016-17-320.jpg)










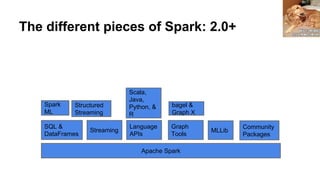
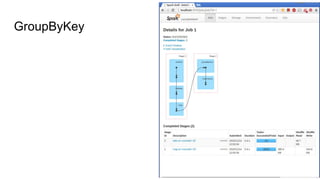
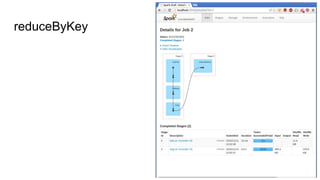
This document provides an introduction to Apache Spark, including: - An overview of what Spark is and the types of problems it can solve - A brief look at the Spark API through the word count example - Details on Spark's core abstractions of RDDs and how transformations and actions work - Potential pitfalls of using groupByKey and how reduceByKey is preferable - Resources for learning more about Spark including books and video tutorials



































































